首先我们看到,这个接口支持四个参数 q,tag,start,count
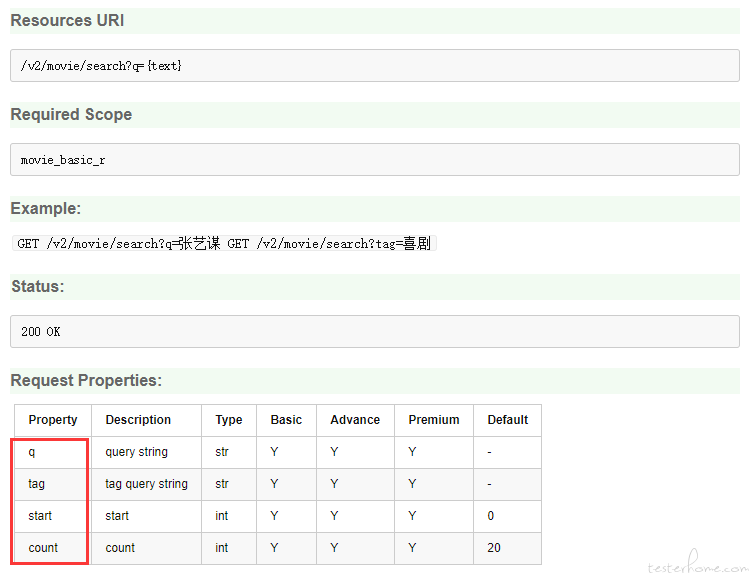
针对每个参数分别设计了一些测试集,如果使用原来的组合方式生成测试用例条数为每个参数笛卡尔乘积(8 * 6 * 3 * 3),而使用正交表生成的测试用例数目为 7,大大削减了无效重复的测试条目,提升测试效率
正交试验法是研究多因素、多水平的一种试验法,它是利用正交表来对试验进行设计,通过少数的试验替代全面试验,根据正交表的正交性从全面试验中挑选适量的、有代表性的点进行试验,这些有代表性的点具备了 “均匀分散,整齐可比” 的特点。
正交实验法设计测试用例,基本步骤如下:
项目 GitHub 地址:https://github.com/lovesoo/OrthogonalArrayTest
参考如上步骤,使用 Python 实现了使用正交表自动设计裁剪测试用例的完整流程。支持 Python 版本为 2.7, 3.7。
初始化正交表,解析构造为可用的正交表对象数组(数据来源:http://support.sas.com/techsup/technote/ts723_Designs.txt)
分别计算 m(水平数),k(因素数目),n(实验次数)值
m=max(m1,m2,m3,…)
k=(k1+k2+k3+…)
n=k1*(m1-1)+k2*(m2-1)+…kx*x-1)+1
查找匹配正交表,先查询是否有完全匹配的正交表数据,否则简单处理,只返回满足>=m,n,k 条件的 n 最小数据,暂未做复杂的数组包含校验及筛选逻辑(后续待优化)
使用查找到的正交表数据,裁剪生成测试集。支持两种用例裁剪模式,取值 0,1
完整代码如下:
# encoding: utf-8
from itertools import groupby
from collections import OrderedDict
import os
def dataSplit(data):
ds = []
mb = [sum([k for m, k in data['mk'] if m <= 10]), sum([k for m, k in data['mk'] if m > 10])]
for i in data['data']:
if mb[1] == 0:
ds.append([int(d) for d in i])
elif mb[0] == 0:
ds.append([int(i[n * 2:(n + 1) * 2]) for n in range(mb[1])])
else:
part_1 = [int(j) for j in i[:mb[0]]]
part_2 = [int(i[mb[0]:][n * 2:(n + 1) * 2]) for n in range(mb[1])]
ds.append(part_1 + part_2)
return ds
class OAT(object):
def __init__(self, OAFile=os.path.split(os.path.realpath(__file__))[0] + '/data/ts723_Designs.txt'):
"""
初始化解析构造正交表对象,数据来源:http://support.sas.com/techsup/technote/ts723_Designs.txt
"""
self.data = {}
# 解析正交表文件数据
with open(OAFile, ) as f:
# 定义临时变量
key = ''
value = []
pos = 0
for i in f:
i = i.strip()
if 'n=' in i:
if key and value:
self.data[key] = dict(pos=pos,
n=int(key.split('n=')[1].strip()),
mk=[[int(mk.split('^')[0]), int(mk.split('^')[1])] for mk in key.split('n=')[0].strip().split(' ')],
data=value)
key = ' '.join([k for k in i.split(' ') if k])
value = []
pos += 1
elif i:
value.append(i)
self.data[key] = dict(pos=pos,
n=int(key.split('n=')[1].strip()),
mk=[[int(mk.split('^')[0]), int(mk.split('^')[1])]for mk in key.split('n=')[0].strip().split(' ')],
data=value)
self.data = sorted(self.data.items(), key=lambda i: i[1]['pos'])
@staticmethod
def get(self, mk):
"""
传入参数:mk列表,如[(2,3)],[(5,5),(2,1)]
1. 计算m,n,k
m=max(m1,m2,m3,…)
k=(k1+k2+k3+…)
n=k1*(m1-1)+k2*(m2-1)+…kx*x-1)+1
2. 查询正交表
这里简单处理,只返回满足>=m,n,k条件的n最小数据,未做复杂的数组包含校验
"""
mk = sorted(mk, key=lambda i: i[0])
m = max([i[0] for i in mk])
k = sum([i[1] for i in mk])
n = sum([i[1] * (i[0] - 1) for i in mk]) + 1
query_key = ' '.join(['^'.join([str(j) for j in i]) for i in mk])
for data in self.data:
# 先查询是否有完全匹配的正交表数据
if query_key in data[0]:
return dataSplit(data[1])
# 否则返回满足>=m,n,k条件的n最小数据
elif data[1]['n'] >= n and data[1]['mk'][0][0] >= m and data[1]['mk'][0][1] >= k:
return dataSplit(data[1])
# 无结果
return None
def genSets(self, params, mode=0, num=1):
"""
传入测试参数OrderedDict,调用正交表生成测试集
mode:用例裁剪模式,取值0,1
0 宽松模式,只裁剪重复测试集
1 严格模式,除裁剪重复测试集外,还裁剪含None测试集(num为允许None测试集最大数目)
"""
sets = []
mk = [(k, len(list(v)))for k, v in groupby(params.items(), key=lambda x:len(x[1]))]
data = OAT.get(self, mk)
for d in data:
# 根据正则表结果生成测试集
q = OrderedDict()
for index, (k, v) in zip(d, params.items()):
try:
q[k] = v[index]
except IndexError:
# 参数取值超出范围时,取None
q[k] = None
if q not in sets:
if mode == 0:
sets.append(q)
elif mode == 1 and (len(list(filter(lambda v: v is None, q.values())))) <= num:
# 测试集裁剪,去除重复及含None测试集
sets.append(q)
return sets
我们复用之前写过的豆瓣电影搜索接口,针对这个接口编写了一个正交表生成裁剪用例 Demo (接口文档地址:https://developers.douban.com/wiki/?title=movie_v2#search)
首先我们看到,这个接口支持四个参数 q,tag,start,count
针对每个参数分别设计了一些测试集,如果使用原来的组合方式生成测试用例条数为每个参数笛卡尔乘积(8 * 6 * 3 * 3),而使用正交表生成的测试用例数目为 7,大大削减了无效重复的测试条目,提升测试效率
执行结果如下(有一条用例出错是因为,根据指定条件查询结果为空,所以结果校验失败):
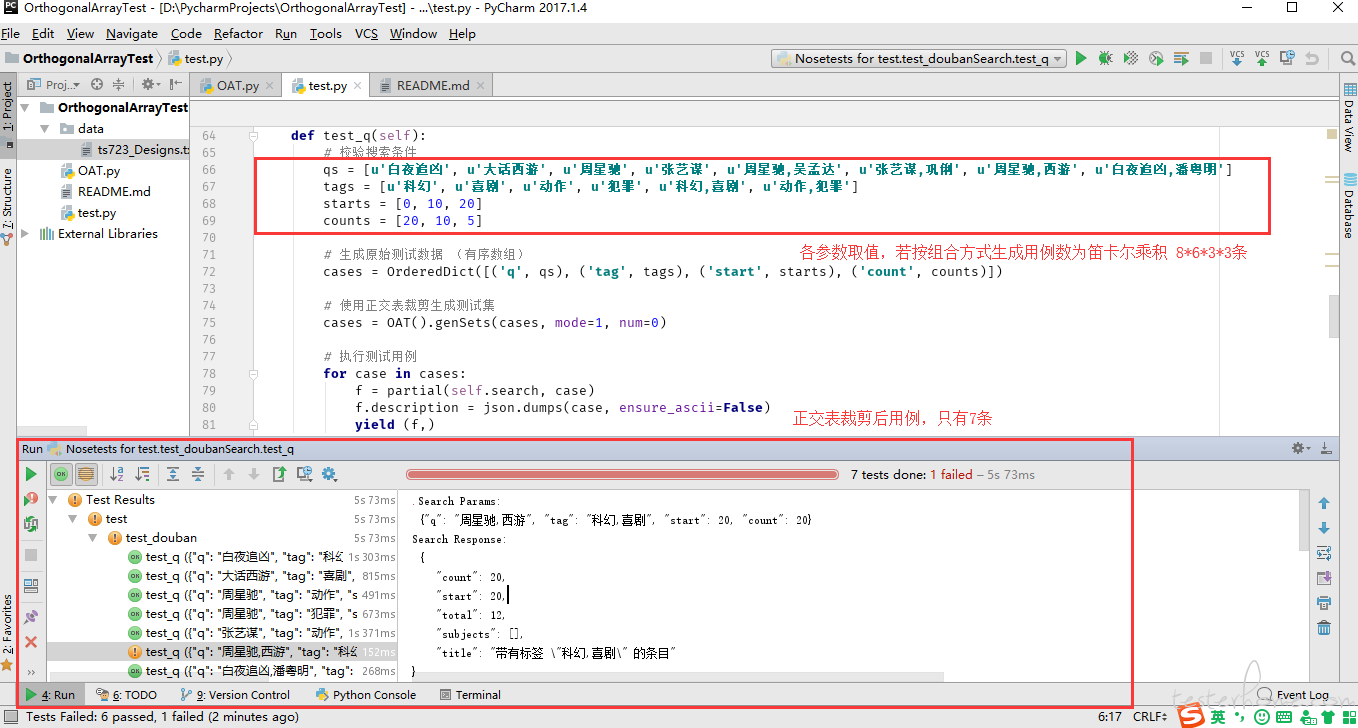
脚本如下:
# encoding: utf-8
from OAT import *
import json
import requests
from functools import partial
from nose.tools import *
"""
pip install requests
pip install nose
"""
class check_response():
@staticmethod
def check_result(response, params, expectNum=None):
# 由于搜索结果存在模糊匹配的情况,这里简单处理只校验第一个返回结果的正确性
if expectNum is not None:
# 期望结果数目不为None时,只判断返回结果数目
eq_(expectNum, len(response['subjects']), '{0}!={1}'.format(expectNum, len(response['subjects'])))
else:
if not response['subjects']:
# 结果为空,直接返回失败
assert False
else:
# 结果不为空,校验第一个结果
subject = response['subjects'][0]
# 先校验搜索条件tag
if params.get('tag'):
for word in params['tag'].split(','):
genres = subject['genres']
ok_(word in genres, 'Check {0} failed!'.format(word))
# 再校验搜索条件q
elif params.get('q'):
# 依次判断片名,导演或演员中是否含有搜索词,任意一个含有则返回成功
for word in params['q'].split(','):
title = [subject['title']]
casts = [i['name'] for i in subject['casts']]
directors = [i['name'] for i in subject['directors']]
total = title + casts + directors
ok_(any(word.lower() in i.lower() for i in total),
'Check {0} failed!'.format(word))
class test_douban(object):
"""
豆瓣搜索接口测试demo,文档地址 https://developers.douban.com/wiki/?title=movie_v2#search
"""
def search(self, params, expectNum=None):
url = 'https://api.douban.com/v2/movie/search'
r = requests.get(url, params=params)
print ('Search Params:\n', json.dumps(params, ensure_ascii=False))
print ('Search Response:\n', json.dumps(r.json(), ensure_ascii=False, indent=4))
code = r.json().get('code', 0)
if code > 0:
assert False, 'Invoke Error.Code:\t{0}'.format(code)
else:
# 校验搜索结果是否与搜索词匹配
check_response.check_result(r.json(), params, expectNum)
def test_q(self):
# 校验搜索条件
qs = [u'白夜追凶', u'大话西游', u'周星驰', u'张艺谋', u'周星驰,吴孟达', u'张艺谋,巩俐', u'周星驰,西游', u'白夜追凶,潘粤明']
tags = [u'科幻', u'喜剧', u'动作', u'犯罪', u'科幻,喜剧', u'动作,犯罪']
starts = [0, 10, 20]
counts = [20, 10, 5]
# 生成原始测试数据 (有序数组)
cases = OrderedDict([('q', qs), ('tag', tags), ('start', starts), ('count', counts)])
# 使用正交表裁剪生成测试集
cases = OAT().genSets(cases, mode=1, num=0)
# 执行测试用例
for case in cases:
f = partial(self.search, case)
f.description = json.dumps(case, ensure_ascii=False)
yield (f,)
