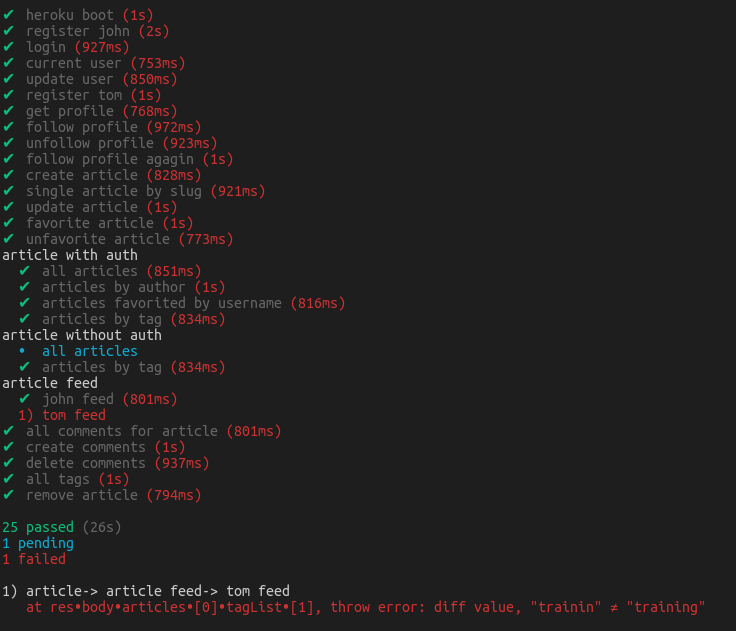
每个组件都是一个独立的模块,对立完成一项具体的工作。所以能很轻易的替换,也很容易进行扩展。
安装命令行
npm i htte-cli -g
编写配置文件 htte.yaml
modules:
- auth
modules/auth.yaml
- describe: john登录
name: loginJohn
req:
url: https://htte-realworld.herokuapp.com/api/users/login
method: post
body:
user:
email: john@jacob.com
password: johnnyjacob
res:
body:
user:
email: john@jacob.com
username: johnjacob
token: !@exist
- describe: john更改用户名
includes: updateUser
req:
headers:
Authorization: !$concat ['Bearer', ' ', !$query loginJohn.res.body.user.token]
body:
user:
username: johnjacobII
res:
body: !@object
username: johnjacobII
htte htte.yaml
有这样一个接口:它的服务地址是 http://localhost:3000/add,采用 POST 并使用 json 作为数据交换格式,请求数据格式 { a: number, b: number},返回数据格式 {c: number},实现功能是对 a,b 求和并返回结果 c。
针对这个接口,测试思路: 向这个接口传递数据 {"a":3,"b":4},并期待它返回{"c":7}
这个测试以文档的形式在 HTTE 中是这样写的。
- describe: 两个数相加
req:
url: http://localhost:3000/add
method: post
headers:
Content-Type: application/json
body:
a: 3
b: 4
res:
body:
c: 7
直接罗列请求和响应,再加一段描述说明测试是干什么的,一个完整的测试就编写完成了。
请看下面两个测试,猜猜目标接口实现了什么功能。
- describe: 登录
name: fooLogin
req:
url: /login
method: post
body:
email: foo@example.com
password: '123456'
res:
body:
token: !@exist string
- describe: 更改昵称
req:
url: /user
method: put
Authorization: !$conat [Bearer, ' ', !$query fooLogin.res.body.token]
body:
nickname: bar
res:
body:
msg: ok
尽管你现在可能还不理解 !@exist, !$concat, !$query,但应该能粗略明白这两个接口的功能、请求响应数据格式。
由于测试逻辑由文档承载,HTTE 轻而易举获得一些其它框架梦寐以求的优点:
完全不需要 care 后端是那种语言实现的,再也不担心从一门语言切换到另一门语言,更遑论从一个框架切换到另一个框架了。
纯文档,不需要懂后端的技术栈,甚至不需要会编程。小白员工,甚至是文职都能快速掌握并编写。
容易写,又容易读,技能要求又低,当然写起来快了。终于能自由的享用测试带来的优点,又最大的避免测试带来的麻烦。
文档写起来又快又容易,很方便采用 TDD 开发策略。终于可以无副作用享受 TDD 的优点了。
即使有 swagger/blueprint 文档了但还是不会用接口怎么办?把测试文档扔给他,满满的都是例子。
初入职员工或初级工程师可能没有那么熟悉业务,技能也没有那么熟练,需要较长的学习期或适应期,写出的接口质量可能也不过关。
有这样一份测试文档能大大缩短这段时间,提高接口质量。
HTTE 除了拥有文档驱动测试的全部优点外,还拥有以下优点.
不是引入新的 DSL,而是直接采用 YAML。没有额外的学习成本,也更容易上手,还能能享受现有 YAML 工具和生态。
先说说为什么文档驱动的测试中需要插件。
某个接口有重名检测,所以测试时我们需要生成一个随机字符串,如何在文档描述随机数呢?某个接口返回一个过期时间,我们需要校验这个时间是再当前时间 24 小时之后,如何再文档中定义这个时间呢?
文档驱动测试这一策略最大的阻碍就是文档无法承载复杂逻辑,缺乏灵活性,它很难描述随机字符串,当前时间这些概率。只有函数才能提供这种灵活性。
插件就是为文档提供函数的,提供这种灵活性的。
插件以 YAML 自定义标签的形式呈现。
有这样一段代码
req:
body: !$concat [a, b, c]
res:
body: !@regexp \w{3}
!$concat 和 !@regexp 就是 YAML 标签,它是一种用户自定义的数据类型。再 HTTE 中,其实就是函数。
所以上面的代码再 HTTE 看来是这样子的。
{
req: {
body: function(ctx) {
return (function(literal) {
return literal.join('');
})(['a', 'b', 'c'])
}
}
res: {
body: function(ctx, actual) {
(function(literal) {
let re = new Regexp(literal);
if (!re.test(actual)) {
ctx.throw('不匹配正则')
}
})('\w{3}')
}
}
}
总的来说,文档具有易读易写易上手等优点,但无法承载复杂逻辑,不够灵活;而函数/代码能提供这种灵活性,但又带来过多的复杂性。
HTTE 采用 YAML 格式,将函数封装到 YAML 标签中, 协调了这种矛盾,最大程度融合彼此的优点,并几乎规避的彼此的缺点。
这是 HTTE 最大的创新之处了。
接口测试中关于数据主要有两种操作,构造请求和校验响应。所以 HTTE 中存在两种插件。
!$
!@
插件集:
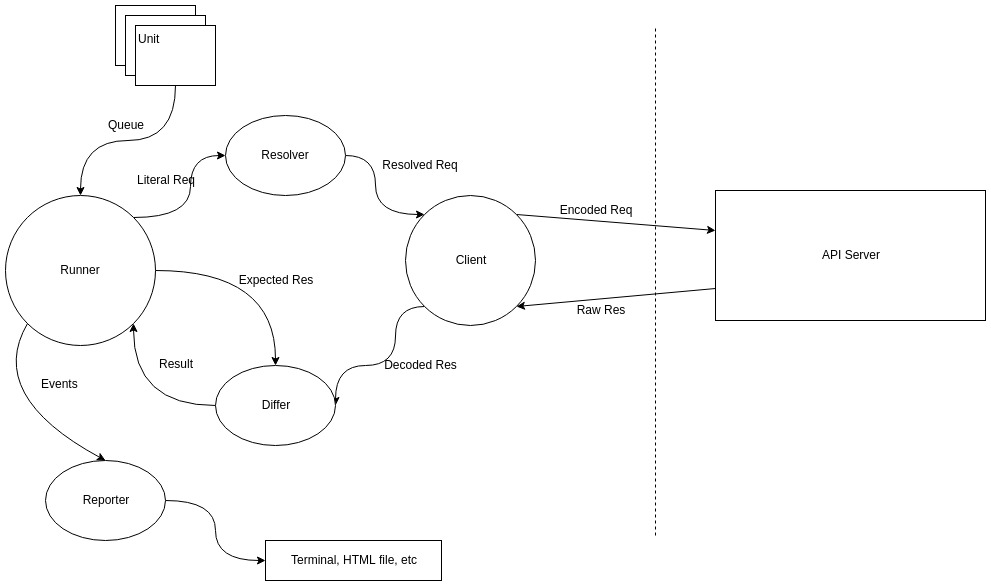
HTTE 架构图如下:
每个组件都是一个独立的模块,对立完成一项具体的工作。所以能很轻易的替换,也很容易进行扩展。
下面结合一个例子,介绍一个测试单元在 HTTE 中具体执行过程,以便大家熟悉各个组件的功能。
又这样一个测试
- describe:
req:
body:
v: !$randnum [3, 6]
res:
body:
v: !@compare
op: gt
value: 2
在被 Runner 载入后所有 YAML 标签依据插件定义展开成函数,伪代码如下。与此同时 Runner 会发送 runUnit 事件。
{
req: { // Literal Req
body: {
v: function(ctx) {
return (function(literal) {
let [min, max] = literal
return Math.random() * (max - min) + min;
})([3, 6])
}
}
},
res: { // Expect Res
body: {
v: function(ctx, actual) {
(function(literal) {
let { op, value } = literal
if (op === 'gt') fn = (v1, v2) => v1 > v2;
if (fn(actual, literal)) return;
ctx.throw('test fail');
})({op: 'gt', value: 2})
}
}
}
}
Runner 将 Literal Req 传递给 Resolver,Resolver 的工作就是递归遍历 Req 中的函数并执行,得到一个纯值的数据。并传递给 Client。
req: { // Resolved Req
body: {
v: 5
}
}
Client 收到这个数据后,构造请求,并将数据编码为合适的格式 (如果是JSON,Encoded Req 将变成 {"v":5}),并发送给后端接口服务。
Client 收到后端服务返回的响应后,需要先将数据解码。假设这个接口是一个回显服务,返回的数据是{"v":5}(Raw Res) 且为JSON,Client 会将数据解码为:
res: { // Decoded Res
body: {
v: 5
}
}
Differ 这时将拿到来自 Runner 的 Expected Res 和 来自 Client 的 Decoded Res。它的工作就是将两者进行比对。
Differ 会遍历 Expected Res 中的每一个值,逐一于 Decoded Res 进行比对。有任意一处不相等都会抛出错误,标记测试失败。
如果两者都是值,判断是否它们全等。如果碰到函数,那么会执行比对函数。伪代码如下:
(function(ctx, actual) {
(function(literal) {
let { op, value } = literal
if (op === 'gt') fn = (v1, v2) => v1 > v2;
if (fn(actual, literal)) return;
ctx.throw('test fail');
})({op: 'gt', value: 2})
}
})(ctx, 5)
如果比对函数没有抛出错误,表示测试通过。Runner 收到测试通过的结果后将发送 doneUnit 事件,并执行队列中的下一条测试。
Reporter 监听 Runner 发送的事件,生成相应的报告,或打印到终端,或生成 HTML 报告文件。
接口协议由客户端扩展提供。
接口间数据是存在耦合的。常见例子,先登录拿到 TOKEN 之后才有权限下订单,发朋友圈等。
所以一个接口测试常常需要访问另一个测试的数据。
HTTE 通过会话 + 插件处理这个问题。
还是结合例子来说明。
有一个登录接口,是这样的。
- describe: tom login
name: tomLogin # <--- 为测试注册一个名字, Why?
req:
body:
email: tom@gmail.com
password: tom...
res:
body:
token: !@exist string
有一个修改用户名的接口,它是权限接口,必须有个 Authorization 请求头且带上登录返回的 token 才能使用。
- describe: tom update username to tem
req:
headers:
Authorization: !$conat [Bearer, ' ', token?] # <--- 如何当上 TOKEN 呢?
body:
username: tem
揭晓答案
Authorization: !$conat [Bearer, ' ', !$query tomLogin.res.body.token]
还可以通过 tomLogin.req.body.email 获取邮箱值,通过 tomLogin.req.body.password 获取密码。是不是优雅?
这是如何实现的呢?
HTTE 中 Runner 启动后,会初始化会话。每次执行完一条单元测试后,会将执行结果记录在会话中,包括请求数据,响应数据,耗费时间,测试结果等。这些数据是只读的,并作为ctx的暴露给了插件函数,所以插件能访问于它之前执行的测试的数据。
同一个测试中, res 中也是能引用 req 中的数据的。
- describe: res ref data in req
req:
body: !$randstr
res:
body: !@query req.body
围绕一个接口常常会由复数个单元测试,而接口有一些一致的属性,拿 HTTP 接口举例,有 req.url, req.method, req.type,难道每次调用都要重新写一遍吗?
- decribe: add api condition 1
req:
url: /add
method: put
type: json
body: v1...
- decribe: add api condition 2
req:
url: /add
method: put
type: json
body: v2...
宏就是为了解决这种重复输入问题而引入的。使用也很简单,定义 + 引用。
在项目配置中定义宏。
defines:
add: # <-- 定义宏
req:
url: /add
method: put
type: json
任意地方再用到这个接口,只需要这样了
- describe: add api with macro
includes: add # <-- 引用宏
req:
body: v...
这个特性是通过组合命令行选项实现。
相关的两个命令行选项是: --bail 遇到任何测试失败的情况停止执行;--continue 从上次中断的地方继续执行测试。
组合这两个选项,可以让我们无数次重置执行该问题接口,直到调试通过。