测试环境还好,可以清空数据库(清起来超爽
 ,就是可能会被测试同事打)。但是生产环境无法接触到数据库。这些测试数据一条一条删起来很费力(selenium 删或者手动删)。
,就是可能会被测试同事打)。但是生产环境无法接触到数据库。这些测试数据一条一条删起来很费力(selenium 删或者手动删)。看到社友的帖子,受了启发,决定用爬虫 + 接口去处理掉这些垃圾数据。
帖子参考:
https://testerhome.com/topics/14695
在我们公司测试中,无论测试环境测试还是线上回归,都不可避免的会出现大量的垃圾数据。
测试环境还好,可以清空数据库(清起来超爽 ,就是可能会被测试同事打)。但是生产环境无法接触到数据库。这些测试数据一条一条删起来很费力(selenium 删或者手动删)。
看到社友的帖子,受了启发,决定用爬虫 + 接口去处理掉这些垃圾数据。
帖子参考:
https://testerhome.com/topics/14695
我们公司涉及的业务是住宅小区方面的,小区下面会有很多的住户,住户可以批量创建,创建完后需要删除。
1.要通过接口删除这些数据,先要找到这个接口,然后这个接口需要哪些参数
通过 fiddler 抓包知道,删除接口是根据用户 id 来的。/deleteUser?id=
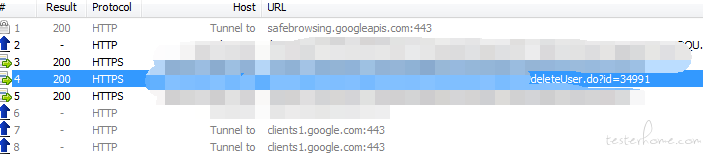
2.调删除的接口,要传用户 ID,需要找到用户 ID
有的用户 ID 是直接在界面展示的,有的用户 ID 可以通过查看 html 源码获取。一般用户 ID 都是一堆字母 + 数字,展示给用户看也没什么意义,大多都会隐藏起来。我这边是通过查看 html 源码获取的
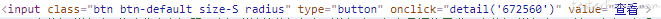
通过比对发现,detail 里面的 672560 就是 ID
3.通过爬虫获取所有的用户 ID
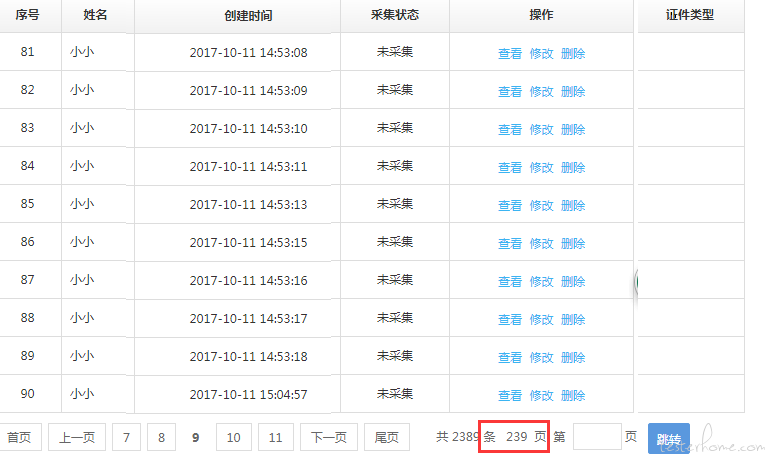
获取到总的页数,获取到每页的 ID,再翻页获取,然后获取到所有的 ID
以下代码作为参考,了解大致思路。
# coding:utf-8
import requests,time
import re
import warnings
warnings.filterwarnings("ignore")
cookie = ''
host = ''
def getTotalPage():
'''先到数据展示的页面查到数据的页数
上图显示的数据有239页'''
totalPage = '' # 数据所显示的页数
urlFind = host + '/findHouseUserList.do'
result = requests.get(urlFind, headers={'Cookie': cookie}, verify=False)
for line in result.content.decode('utf-8').split('\n'):
kw = re.findall(re.compile('条(.*?)页'),line)
if kw:
#得到的kw是一个list
for s in kw[0]:
if s.isdigit():
totalPage = totalPage + s
if not totalPage.isdigit():
print('没有获取到总页数')
return 0
return totalPage
def getAllUserId():
'''获取每页的用户ID'''
userIds = [] # 用于保存获取到的住户id
totalPage = getTotalPage()
for i in range(int(totalPage)):
#页码规律是每翻一页page增大10,第一页page是0,第二个page是10,第三页page是20,第四页page是30,以此类推
page = (int(i) - 1) * 10
urlFindByPage = host + '/findHouseUserList.do?page=' + str(page)
result = requests.get(urlFindByPage, headers={'Cookie': cookie},verify=False)
'''根据上面的html源码查看到id,决定取detail和value之间的字段'''
for line in result.content.decode('utf-8').split('\n'):
if "detail('" in line:
startIndex = line.find("detail('")
endIndex = line.find("')\" value")
userIds.append(line[startIndex+8:endIndex])
# 防止爬取太快,增加服务器压力
time.sleep(0.1)
return userIds
def deleteUserById():
userIds = getAllUserId()
i = 0 #用于统计删除的用户的数量
for id in userIds:
urlDeleteById = host + '/deleteUser.do?id=' + id
result = requests.get(urlDeleteById, headers={'Cookie': cookie}, verify=False)
i = i + 1
print(result.status_code)
print('删除第'+str(i)+'个')
# 防止频繁请求,增加服务器压力
time.sleep(0.1)
