
神经网络是机器学习中里程碑式的发现。 在一次研究猫的视觉神经原理的实验中,科学家在一只小猫的眼睛中安装了监测神经元活动的仪器,并给这只小猫观看各种物体以刺激视觉神经。 科学家根据神经活动发现,当物体进入猫的视觉神经中的时候并不是所有的神经元都做出反应。而是像一条链或者说像是一个网络一样,由一个节点传递到下一个节点。 由此引发了神经网络的定义。
上面是一个典型的神经网络,在神经网络中,每一个神经元都会传递到下层的节点上。 每一个神经元都会接受来自上一层的每一个神经元的值。这样一层一层的传递和计算,组成了神经网络。 第一层的 x1,x2,x3,x4 是神经网络的输入层,他们是我们的输入特征 (也是之前说的规则)。 之后是隐藏层 (因为对于用户来说他是隐藏的,用户只看的到输入层和输出层),隐藏层的每一个节点都会接收到上一层每一个神经元的值,经过计算后继续向下传递。 直到最后的输出层计算出最终的结果。 那么我们神经网络中的每一个神经元是什么呢? 我们可以理解,每一个神经元都是我们之前说到的逻辑回归。神经网络是把很多个逻辑回归组成了一个网络进行不停的迭代计算。
那么深度学习是什么呢?深度学习是一个很唬人的名字,这个名字有碍于人理解它的本质。它是一个多隐藏层的神经网络。上面介绍神经网络的时候,我们有一个输入层 (输入特征,也就是 x1,x2,x3,x4),还有之后的隐藏层以及最后的输出层。 如果我们固定输入层和输出层。把一个隐藏层扩展成多个隐藏层,那这就是深度学习了。 如下:
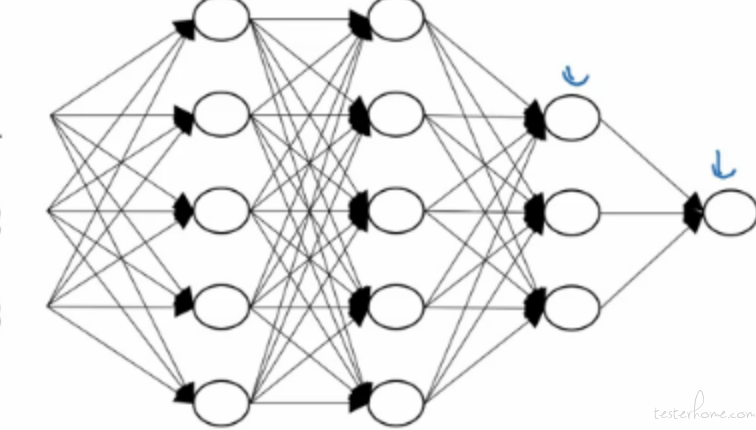
所以,深度学习就是一个多隐藏层的神经网络。
接下来我们探讨一下我们为什么使用深度学习,它有什么优点么? 我们之前讲逻辑回归的时候说到,只要更换激活函数我们可以处理 2 分类,多分类以及回归预测问题。这几乎已经覆盖了除 NLP 外现在所有主流的商业场景 (NLP:自然语言处理,序列模型的应用之一,之后会讲到)。那为什么我们还要使用深度学习呢?它有什么优点或者说它比我们单纯的逻辑回归有什么优势呢。 接下来我们讨论一下深度学习是如何处理计算机视觉的吧。在 CNN(卷积神经网络) 中,我们识别一张人脸图片的方式大概是下面的样子的。
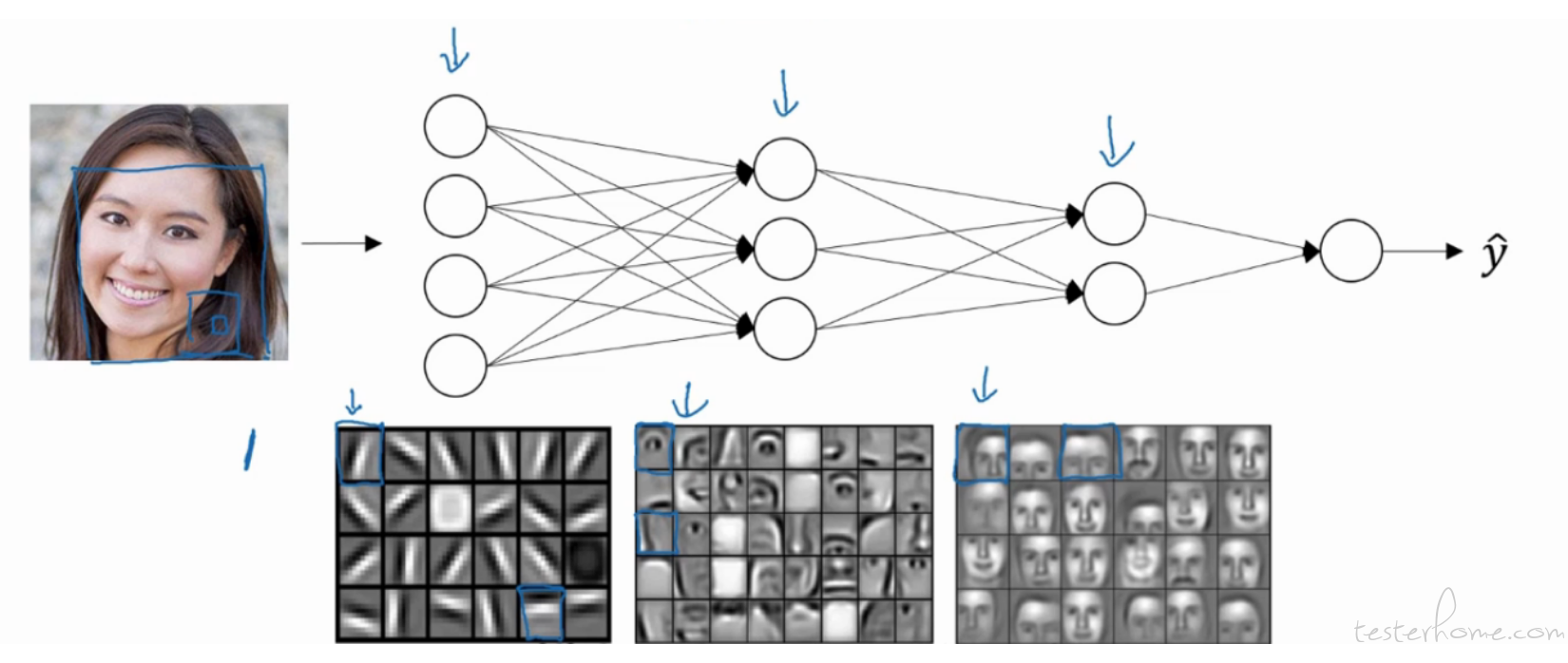
我们在这里用人话简单说一下它的过程。 我们输入的特征是一个人脸图片,我们的计算机程序会把它转换成像素矩阵作为输入层的特征,我们可以把前几层的神经单元当成是一些探测器。例如上图我们看输入层输入了一张图片,然后第一个隐藏层识别出了一些浅层的边框,这时候计算机还不知道他们的具体意义,接下来把他们输入到第二个隐藏层中继续识别,我们识别出了一些人体器官,这时候就已经有了一些实体的基本具象。然后我们把这些人体器官的信息继续输出到下一层,下一层的神经元通过这些特征进行计算,组合成人脸各种局部人脸。最后把这些作为特征输出到输出层计算出最终结果。 我们可以这么理解,深度学习的每一层都是在给下一层计算出新的特征。
大家都说深度学习很像是人脑,很像我开始说的关于实验猫的视觉神经的过程。 因为人脑识别图片的过程就是先通过识识别一些浅层信息,然后一点点的组成更深层的东西。 那这种处理图片的方式就比单纯的逻辑回归好很多。 其实我们是可以直接把图片转换成像素矩阵输入到逻辑回归进行计算。 但他的效果相对于深度学习来说是惨不忍睹的。
深度学习的发展历史是坎坷的。早在上个世纪神经网络就已经被提了出来。但他的应用却一直被限制住了。甚至当时的教科书中都会写如果你要使用神经网络,层数不要超过三层。为什么会这样呢?如果深度学习是一个特别牛逼的事情,层数越多,精度应该就会越高。那为什么我们还要限制网络深度呢? 答案是数据, 我们在最开始的时候说过现阶段人工智能的定义是机器学习 + 大数据。 模型的效果主要取决于数据, 数据量越大,机器学习能利用的样本和特征越多,效果就越好。 而在上个世纪的时候,我们的数据被限制到了一个很小的量级,因为那个时候没有互联网没有数据沉淀。 所以过于复杂的模型算法 (深度学习是多个逻辑回归组成的多隐藏层神经网络,它比单一一个逻辑回归复杂很多),如果没有足够的数据喂给它就会造成机器学习中经典的过拟合问题, 过拟合的详细解释我会在后面介绍数据集的时候说。现在大家只需要知道过拟合会导致模型效果变的很差。 所以当时的数据量限制了深度学习的发展。
到了本世纪,互联网井喷式的发展,互联网的快速发展带动了大量的用户数据的积累。 这时候深度学习终于有了可用武之地。 但这时候我们面临了一个新的问题, 数据量太大了之后,我们的存储和计算跟不上去了。本身对于深度学习这种复杂算法就需要大量的计算,数据量过于庞大会导致过于缓慢的运算效率是企业无法接受的。 所以 Google 的 3 篇 Map reduce 论文适时的出现了,由此揭开了以 hadoop 生态圈为主的分布式计算的大数据技术时代。 我们的深度学习也依托于这一成果进入了一个有史以来最辉煌的时期。 所以我再开篇就说人工智能的定义是:机器学习 + 大数据。 很外行人会忽略大数据起到的作用,认为算法是王道。 但其实数据与算法拥有同等的地位和实现难度。
CNN 在深度学习中有着特别的意义。如果是 RNN(循环神经网络) 是 NLP(自然语言处理) 的关键技术。那 CNN 就是计算机视觉的不二选择。刚才我们简单的讲到过识别一张人脸是如何在 CNN 中工作的。那么在这里我再拓展一些内容。
CNN 作为深度学习的一个分支,他与传统的 DNN 不一样的是它在神经网络中,除了由逻辑回归构成的神经元外,还存在一个名为卷积层的东西,它会对图片进行卷积计算。 那什么是卷积计算呢。 其实就是存在一个过滤器, 这个过滤器就是在图片转成的像素矩阵中,探测到各种各样的边框特征,帮助算法识别更加具象的特征。所以我们刚才在介绍 CNN 的时候就是通过这样一个一个的卷积层去识别出一张人脸的。 当然如果是一个人脸识别的场景,比如员工刷脸打卡。那么我们不仅要识别出数据库中存放的员工照片,还要识别出现场照相出来的图片,并进行对比。 那么这个网络就变成了下面的样子。
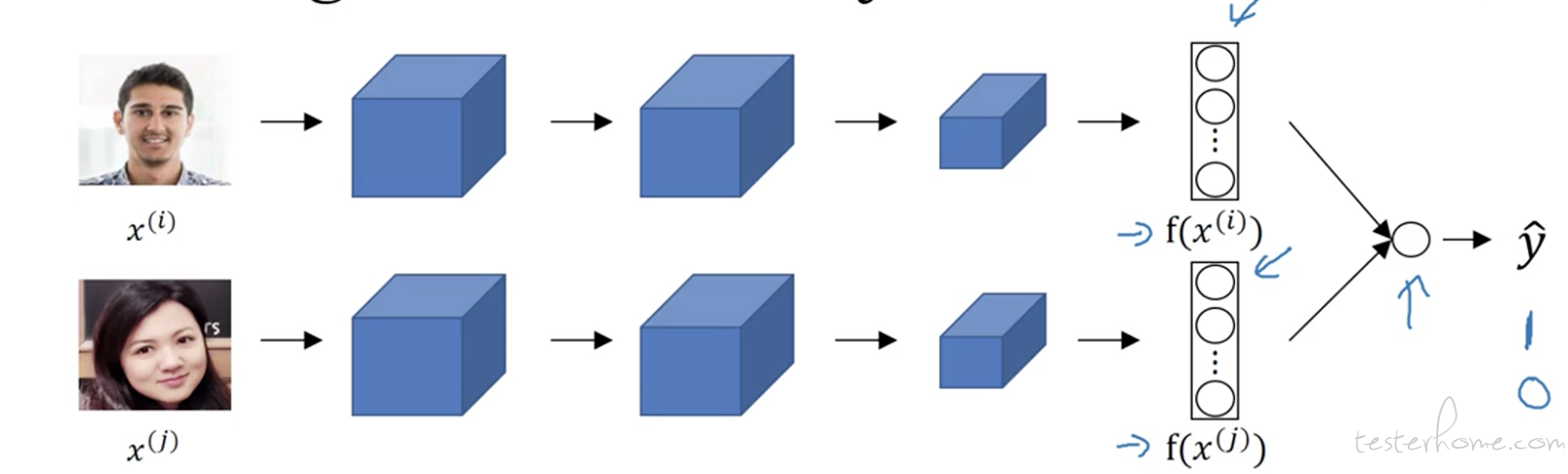
我们的网络变成了一个双层网络,他们分别是一个单独的 CNN,但是缺少了输出层。 我们把这样两个缺少了输出层的 CNN 网络连接到了一个输出层上。选择 sigmod 作为激活函数。实现二分类的效果。判断出两个图片是不是同一个人。这样我们遍历系统中的员工库与当前这个人依次比较。就完成了这样一个场景。
