HTMLParser 是 Python 自带的一个类,主要用来解析 HTML 和 XHTML 文件。
使用 HTMLParser 非常简单,只需要在你的 python 文件中导入 HTMLParser 类,创建一个新类来继承它,并且对其 handle_starttag、handle_data 等事件处理方法进行重写从而解析出需要的 HTML 数据。
# coding=utf-8
from HTMLParser import HTMLParser
# 创建类MyHTMLParser并继承HTMLParser
class MyHTMLParser(HTMLParser):
#重写handle_starttag方法
def handle_starttag(self, tag, attrs):
print "Start tag:", tag
for attr in attrs:
print " attr:", attr
#重写handle_endtag方法
def handle_endtag(self, tag):
print "End tag :", tag
#重写handle_data方法
def handle_data(self, data):
print "Data :", data
#重写handle_comment方法
def handle_comment(self, data):
print "Comment :", data
#重写handle_charref方法
def handle_charref(self, name):
if name.startswith('x'):
c = chr(int(name[1:], 16))
else:
c = chr(int(name))
print "Num ent :", c
def handle_decl(self, data):
print "Decl :", data
if __name__ == "__main__":
parser = MyHTMLParser()
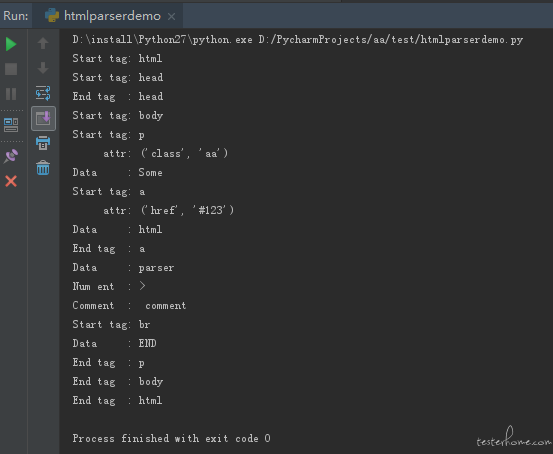
parser.feed('<html><head></head><body><p class = "aa" >Some <a href=\"#123\">html</a>parser><!-- comment --><br>END</p></body></html>')
以上这段代码通过 feed() 方法传入一个简单的 HTML 文件,对其开始标签及开始标签属性、结束标签、标签内容、注释、特殊字符等进行解析并打印。执行结果如下:
# coding=utf-8
from urllib import urlopen
from HTMLParser import HTMLParser
class Scraper(HTMLParser):
def handle_starttag(self, tag, attrs):
print "StartedTag: ", tag
def handle_endtag(self, tag):
print "EndTag: ", tag
def handle_data(self, data):
print "Data: ", data
if __name__=="__main__":
content = urlopen("http://www.baidu.com").read()
sc = Scraper()
sc.feed(content)
# coding=utf-8
from HTMLParser import HTMLParser
class AnalyzeReport(HTMLParser):
def __init__(self):
HTMLParser.__init__(self)
self.ps = 0
self.fail = 0
def handle_starttag(self, tag, attrs):
pass
def handle_endtag(self, tag):
pass
def handle_data(self, data):
'''
# 打印测试用例详细执行结果
if self.lasttag == 'font' or data.__contains__("用例:"):
print data
'''
if data == "Fail":
self.fail += 1
elif data == "Pass":
self.ps += 1
else:
pass
def get_ps(self):
return self.ps
def get_fail(self):
return self.fail
def read_html(filepath):
'''
:param filepath: 要解析的html文件路径
:return: 返回文件内容
'''
try:
f = open(filepath)
except IOError, e:
print e
else:
content = f.read()
return content
if __name__ == "__main__":
content = read_html("TestReport.html")
pars = AnalyzeReport()
pars.feed(content)
print "*" * 100
print "失败测试用例数:", pars.fail
print "成功测试用例数:", pars.ps
