## 脚本编写
一、设置流程
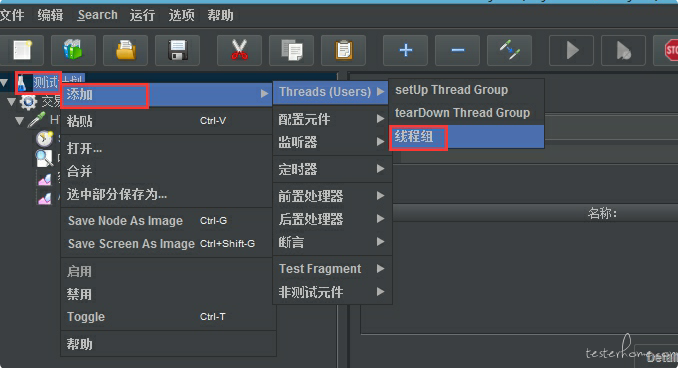
1.创建线程组;
右键测试计划->添加->Threads(Users)->线程组

2.创建 HTTP 请求
右键线程组->添加-Threads(Users)->HTTP 请求
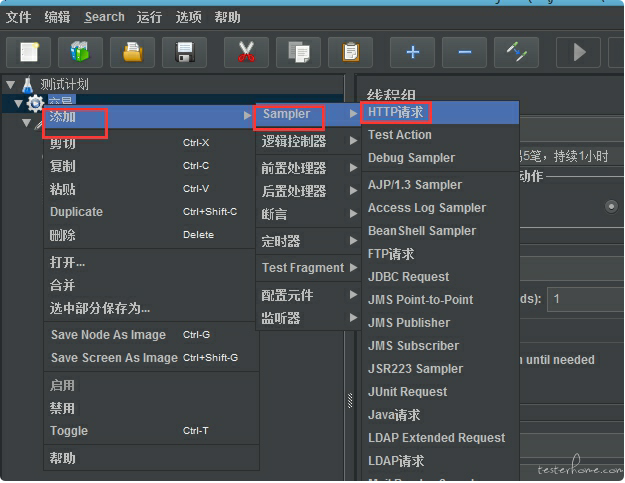

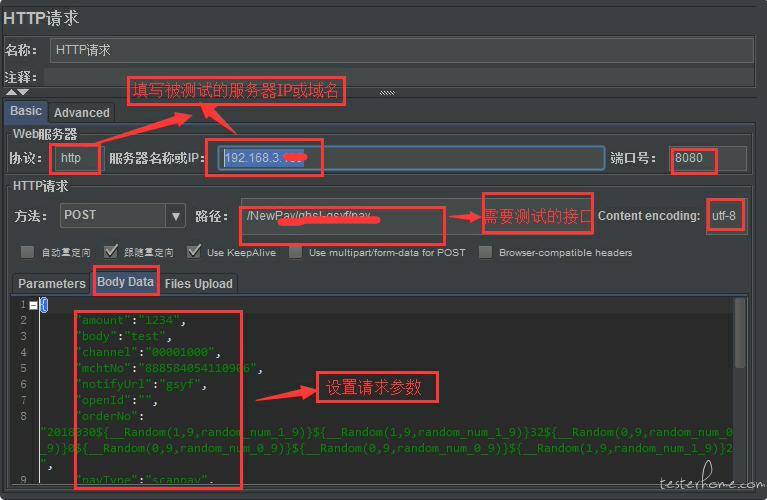
3.设置 HTTP 请求
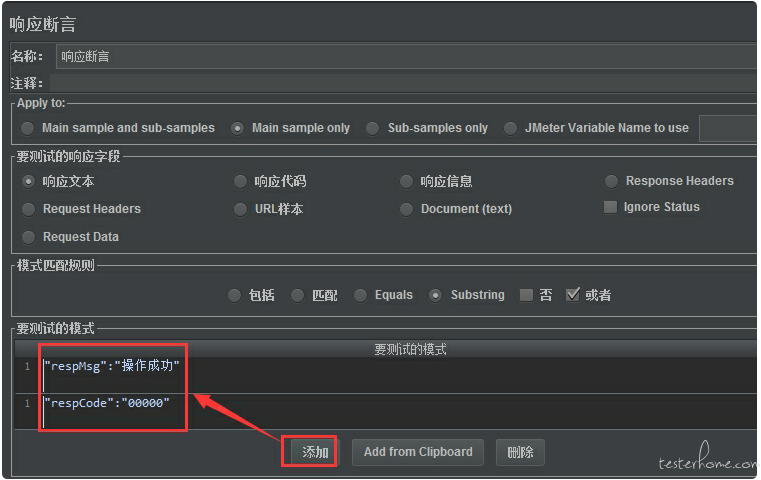
4.设置断言
右键 HTTP 请求->添加->断言

5.设置监听
添加聚合报告、查看结果树、图形结果
##Jmeter 常用函数
"_csvRead"函数
csvRead 函数是从外部读取参数,csvRead 函数可以从一个文件中读取多个参数。
下面具体讲一下如何使用 csvread 函数:
1.新建一个 csv 或者 text 文件,里面保存要读取的参数,每个参数间用逗号相隔。每行表示每一组参数,每列表示每种参数:
比如:
admin,123
manager,456
2.打开 Jmeter 的函数助手,选择 csvread 函数:
其中:
CSV file to get values from | *alias:要读取的文件路径,应该是绝对路径
CSV 文件列号 | next| *alias:从第几列开始读取,注意第一列是 0
点击生成按钮,则生成了函数,为:${__CSVRead(D:\login.txt,1)}csvread 就是从 login.txt 文件中读取第一列的参数。以此类推。
3.将生成的参数拷贝到需要参数化的参数的值一项中,如果要修改要读取的参数的列,则可以直接在参数值中修改数字而不用重新在 csvread 函数生成中修改。
4.jmeter 执行的时候,如果有多个线程,顺序读取第一行的数字,如果线程组多余文件中的行数,则循环读取。
5.利用该功能,可以实现不同参数需要不同参数值的问题,只需要在需要参数化的地方将生成的 CSVRead 函数字符串粘贴过去,然后修改表示第几列的数字就可以了。
"_ StringFromFile"函数
功能:这个函数是从一个文件中取到一个字符串,这个函数和 LoadRunner 中的 File 变量差不多,不过 LoadRunner 可以直接从数 据库中查询记录,自动生成文件,而 Jmeter 需要我们借助第三方工具生成文本作用:可以用来实现参数化 http 请求发送的参数,使得在 Jmeter 运行 时参数化了的参数在每个线程读取不同的内容。如果某个参数每次发送请求的时候不能重复才可以存储到数据库中,则用这个功能十分方便。
使用:
1.首先需要一个文本文件,可以手工生成,也可以通过数据库查询工具查出结果,然后拷贝到一个文本文件中。
2.点击 Jmeter 的 “选项”,选择 “函数助手对话框”(或者使用快捷键 “Ctrl+F”),在 “选择一个功能” 的下拉框中选择 “_StringFromFile”
3.设置 “_StringFromFile” 函数的值,具体如下:
● 输入文件的全路径:输入前面生成的文件的完整路径,即文件路径+文件名.扩展名(文件路径可以写成相对路径或绝对路径,默认读取位置为/bin 下)
● 函数名称:输入某个名称,用于存储在测试计划中其他的方式使用的值。
● 文件开始结束序号:第三,第四个参数是文件开始的序号,也就是文件读取的其起始行数。第四个参数是文件的结束序号,也就是要读取文件的最后行。假如咱们生 成的文本文件有 200 行,如果开始序号设置成 50,结束行设置成 150,那么这个函数会按顺序从第 50 行,一直读取到 150 行,如果测试的循环次数超过了 文件行数,比如循环了 102 次,那么最后一次循环读取的文件内容和第一次的一样,函数会自动循环读取。文件的起始序号和结束序号也可以不用设置,这样函数 会从第一行读取到最后一行,然后再循环读取。
4.注意:该函数每次读取文件中的一行,如果线程组中有多个线程,则每个线程顺序读取一行,如果有多次循环,则每次循环顺序读取一行。
"_Random"函数
功能:这个函数是从某个数字段随机读取数据替换参数,可以利用在测试需要添加多条数据记录而且某些字段需要唯一性的测试脚本中,随机生成的参数是数字
作用:可以用来实现参数化 http 请求发送的参数,使得在 Jmeter 运行时参数化了的参数在每个线程去不同的随机数。如果某个参数每次发送请求的时候不能重复才可以存储到数据库中,则用这个功能十分方便。
使用:
1.点击 Jmeter 的 “选项”,选择 “函数助手对话框”(或者使用快捷键 “Ctrl+F”),在 “选择一个功能” 的下拉框中选择 “_Random”。
2.配置 “Random” 函数,第一个参数是 “一个范围内的最小值”,即所要取的随机数的最小值,我们设置成 1;第二个参数是 “一个范围内的 最大值”,即所要取的随机数的最大值,我们设置成 100;第三个参数是 “函数名称”,即用于存储在测试计划中其他的方式使用的值,我们设置成 Random。设置好上面的三个参数后,点击 “生成” 按钮,这样就会在对话框的最下面生成一个字符串 “${_Random(1,100,Random)}”,在我们编写的脚本中,找到要替换的参数,把它的值换成前面生成的字符串就可以了,然后每次运行 的时候,这个参数会变成一个 1 到 100 之间的随机数。。
"_counter"函数
功能:这个函数是一个计数器,用于统计函数的使用次数,它从 1 开始,每调用这个函数一次它就会自动加 1,它有两个参数,第一个参数是布尔型的, 只能设置成 “TRUE” 或者 “FALSE”,如果是 TRUE,那么每个用户有自己的计数器,可以用于统计每个线程歌执行了多少次。如果是 FALSE,那就 使用全局计数器,可以统计出这次测试共运行了多少次。第二个参数是 “函数名称”
格式:${__counter(FALSE,test)}
使用:我们将 “_counter” 函数生成的参数复制到某个参数下面,如果为 TRUE 格式,则每个线程各自统计,最大数为循环数,如果为 FALSE,则所有线程一起统计,最大数为线程数乘以循环数
"_time” 函数
功能:Jmeter 运行时取当前时间到变量,利用该功能,可以将某个参数增加 time 函数,然后用该参数作为查询条件查询,然后以该参数作为断 言,这样可以使得断言更精确,因为时间实时变化的,使用该方法,需要注意的是,要先添加一个全局的用户参数,具体在断言操作中有描述。
>格式:${time(MMddmmss,TEST)}
使用:添加 jmeter 的 time 函数,选择选项——函数助手,然后选择time 函数
在 “ormat string for SimpleDateFormat (optional)” 中输入值 “MMddhhmmss”,表示取月日时分秒。
然后,点击生成,则生成了 time 参数。
"_intSum” 函数
功能:用于计算多个整数的和,可以是计算正整数和负整数的和,它有 N 个参数,最少有 3 个参数,最多不限。最后一个参数是函数名称,前面的其它参 数是要求和的整数。这个函数在函数对话框中只显示 3 个参数,如果要计算多个整数,可以通过添加参数实现,不过最后一个参数一定要是函数名称。再添加的参数 会在函数名称后面,这个时候,需要我们手动将函数名称参数放到最后一个。
格式:${__intSum(1,100,test)}
#Jmeter消息类的功能
${__threadNum} :得到testplan的线程数
${__machineName} :得到主机名字
${__time(EEE\, d MMM yyyy)} :返回一定格式的时间信息 。${__log(Message)}:写入log文件”…thread Name : Message” 。${__log(Message,OUT)}:输出到命令行。${__log(${VAR},,,VAR=)} :以 “…thread Name VAR=value”形式输出到log文件。
#Jmeter输入类的功能
这里Jason只介绍下${__XPath(File,//XX/XX/@XX)} :XPath方式读了File文件的相应属性.
#Jmeter计算类的功能
${__counter(X)} :自增函数,X(true/false)来控制是否分配线程来增加.
${__Random(X,Y,Z)} :随机函数,X为最小值,Y为最大值,Z为存储的变量名.
#Jmeter的Properties文件使用的功能类
之前Jason在Jmeter的P函数及properties文件介绍了相关的内容.
#Jmeter的变量操作类的功能
${__split(X,Y,Z)} :用来分割变量用的,X为需要分割的变量或者String,Y为存储的变量名,Z为分割符.
${__V} :的使用主要来源于变量中含变量的情况 eg. ${A${N}} 可以用${__V(A${N})} 来显示成功.
${__eval} :主要用在对SQL的处理上,具体使用看下面的例子:
* name=Smith * column=age * table=birthdays * SQL=select ${column} from ${table} where name=’${name}’
用${__eval(${SQL})}可以得到”select age from birthdays where name=’Smith’”.
#Jmeter的String操作类的功能
${__regexFunction} :对前一个响应进行正则规约提取.具体参考这里.
${__char},${__unescape},${__unescapeHtml},${__escapeHtml} :主要用来对字符的编码格式的转换的.
#Jmeter的脚本操作类的功能
${__javaScript(X,Y)} :主要是使用Javascript来做一些简单的操作.例如计算和字符处理等等.
eg. ${__javaScript(‘${sp}’.slice(7\,99999))}
${__BeanShell(X)} :主要是利用BeanShell来实现一些具体的功能,BeanShell具体我们可以参考BeanShell.
## 运行脚本
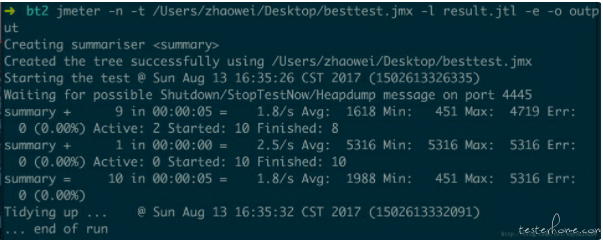
一、如果没有.jtl 文件,运行如下命令:
jmeter -n -t source.jmx -l result.jtl -e -o /tmp/ResultReport
我们来看一下这条命令的参数:
-n :以非 GUI 形式运行 Jmeter
-t :source.jmx 脚本路径
-l :result.jtl 运行结果保存路径(.jtl),此文件必须不存在
-e :在脚本运行结束后生成 html 报告
-o :用于存放 html 报告的目录
二、如果已经存在结果文件(.jtl),可运行如下命令生成报告
jmeter -g result.jtl -o /tmp/ResultReport
参数:
-g : result.jtl 已经存在的.jtl 文件的路径。
-o :用于存放 html 报告的目录
这种没有日志打印


无论采用哪种方式,执行完后会在执行的目录生成如下文件或文件夹:


## 分析报告
查看结果树
Thread Name: 线程组名称
Sample Start: 启动开始时间
Load time: 加载时长
Latency: 等待时长
Size in bytes: 发送的数据总大小 1GB=1024MB,1MB=1024KB,1KB=1024Bytes Headers size in bytes: 发送头大小
Body size in bytes: 发送数据的其余部分大小
Sample Count: 发送统计
Error Count: 交互错误统计
Response code: 返回码
Response message: 返回信息
Response headers: 返回的头部信息
图形结果
样本数目:总共发送到服务器的请求数
最新样本:代表时间的数字,是服务器响应最后一个请求的时间
吞吐量:服务器每分钟处理的请求数。是指在没有帧丢失的情况下,设备能够接受的最大速率。
平均值:总运行时间除以发送到服务器的请求数
中间值:时间的数字,有一半的服务器响应时间低于该值而另一半高于该值。
偏离:服务器响应时间变化、离散程度测量值的大小,或者,换句话说,就是数据的分布。
Status:请求状态,如果为勾则表示成功,如果为叉则表示失败 如果 Status 为叉,那很显然请求是失败了,但如果是勾,也并不能认为请求就一定完全成功了,因为还得看 Bytes 的字节数是否是所请求网页的正常大小值,如果不是则说明发生了丢包现象,也不是完全成功。
Bytes:请求字节数
Latency:等待时长
聚合报告
Label:请求类型,对应在测试计划下填写的请求名称。
Samples:当前发送到服务器的请求总数,对应图形报表中的样本数目。
Average:平均响应时间,计算方法是总运行时间除以发送到服务器的总请求数,对应图形报表中的平均值。
Median:中位数,也就是 50% 用户的响应时间,即图形报表中的中间值。
90%line:90% 请求的响应时间值
Min:服务器响应的最短时间 Max: 服务器响应的最长时间
Error%: 请求返回错误的百分比 Throughput: 服务器每单位时间处理的请求数,对应图形报表中的吞吐量。 KB/sec: 每秒钟请求的字节数。
KB/sec: 每秒钟请求的字节数。
Throughput: 服务器每单位时间处理的请求数,对应图形报表中的吞吐量。
