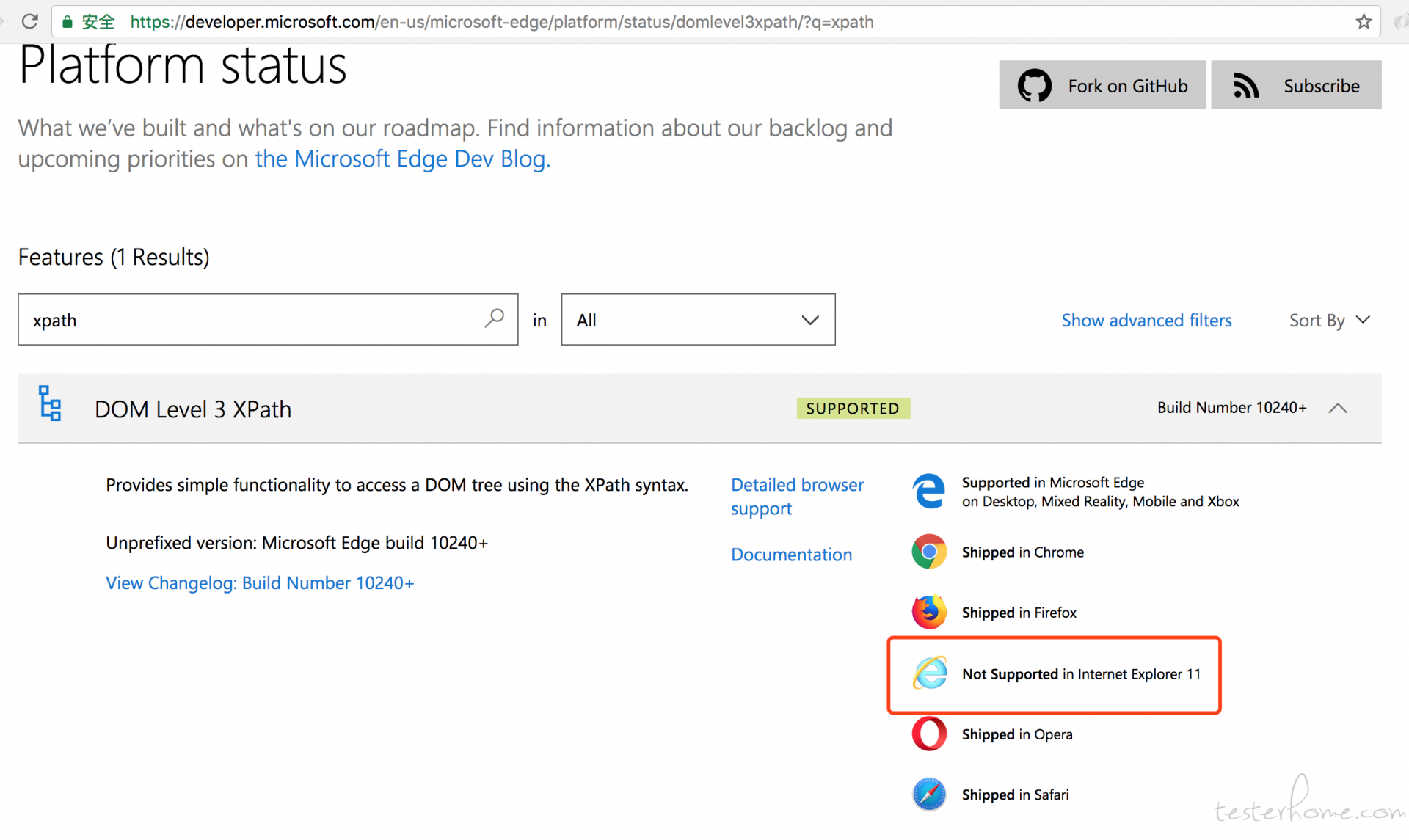
建议抛弃 ie 的可以退下了,人家可能定位的群体,大部分使用 ie 的怎么办?
楼主看看这篇文章 http://laiyenmin.blogspot.tw/2014/01/xpath-ie10-ie11-selectnodes.html
經過不斷的 google ,網路上有幾個解法
\1. 在獲取 xml 的同時,將他封裝成 MSXML
try{
xhr.responseType = "msxml-document";
}catch(e){}
\2. 在使用 xPath 的地方將 xml 變更成 MSXML
var doc;
try{
doc = new ActiveXObject('Microsoft.XMLDOM');
doc.loadXML(stringVarWithXml);
var node = doc.selectSingleNode('//foo');
}catch(e){
//deal with case that ActiveXObject is not supported
}
\3. 使用模擬 xPath 的套件取代 xPath 行為
https://code.google.com/p/wicked-good-xpath/
雖然其實最後這三個解法都無法解決我的問題
我另外又試了另一個可能可以的方法
使用 getElementsByTagName() 函式來取代 SelectNodes (SelectSingleNode)
但是在程式中又都是只尋找下一層的子節點
而且原本的 xml 竟然一大堆同名的節點下方還有同名的節點
真是被打敗
於是花了很多時間,把原本的程式邏輯搞清楚
發現其實根本不需要用到 xPath 因為所有的搜尋行為都只找下一層而已
因此我自己寫了一個 getChildByName function 來取代掉原本的方法
getChildByName = function(xmlDoc, tagName){
var tmpXML = xmlDoc.cloneNode(true);
var childNodes = tmpXML.childNodes;
for(var i = childNodes.length-1 ; i >= 0 ; i--){
if(childNodes[i].tagName != tagName){
tmpXML.removeChild(childNodes[i]);
}
}
childNodes = tmpXML.childNodes;
return childNodes;
}
其實確實是還有改進的空間
但是以目前來說,可以確實解決問題就好了