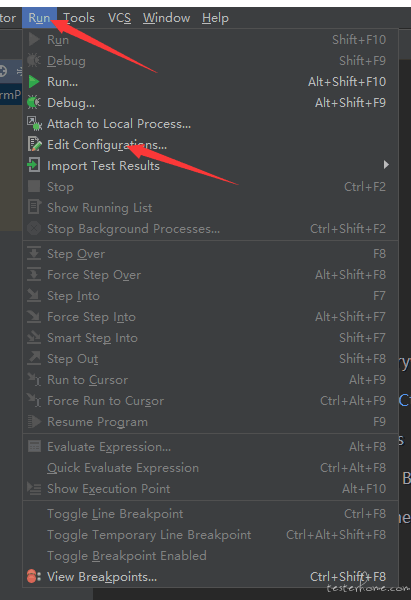
点击 Run->Edit Configurations
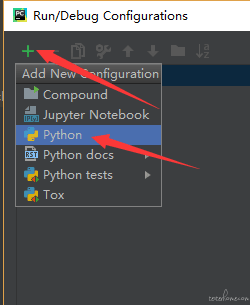
新建一个运行的 python 模块
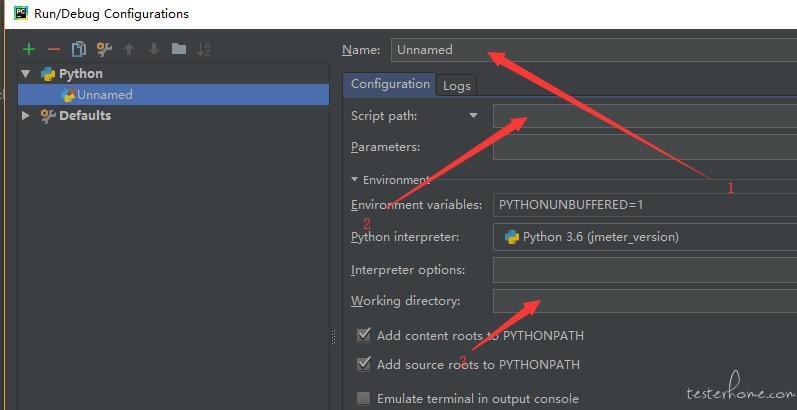
1.Name:改成 spider;
2.script:选择刚才新建的那个 begin.py 文件;
3.Working Direciton:改成自己的工作目录
6 .点击运行
1 .新建工程
scrapy startproject JMeterVersion
2 .pycharm 打开项目,选择 open
3 .新建爬虫 spider.py
import scrapy
class JMeterVersionSpider(scrapy.Spider):
name = 'JMeterVersion' #爬虫的名字
start_urls = ['http://jmeter.apache.org/changes_history.html'] #要爬取的网站列表
def parse(self, response):
print(response.body) #打印网站的静态代码(此种方法无法获取由js动态生成的数据)
4 .scrapy.cfg 同目录下新建 begin.py
from scrapy import cmdline
cmdline.execute("scrapy crawl JMeterVersion".split())
5 .配置 pycharm
点击 Run->Edit Configurations
新建一个运行的 python 模块
1.Name:改成 spider;
2.script:选择刚才新建的那个 begin.py 文件;
3.Working Direciton:改成自己的工作目录
6 .点击运行
