最近问答类应用火的不像话,各大搜索平台也基于 AI 技术推出各种答题辅助应用,这就需要我们有多余的设备,一时间也带火了各种模拟器。
试用了这些大厂的 AI 产品,是挺强大的,但全听它的几本没几次能通关的,即使通关了也是大几十万人都通关。
于是想结合大厂的 AI 计算结果,同时调浏览器搜索相关的问题,获取答案关键词在搜索页面上的出现次数,反应快的话还能自己做个人工个判断。
下面是刚开始运行脚本的动图,实际运行时是会自己一直运行检查是否有新的问题并自动搜索的。
主要步骤
1.获取 AI 机器人的推荐答案
这里 result 的是 sougou 的 AI 计算的结果:
url = 'http://140.143.49.31/api/ans2?key=zscr&wdcallback=jQuery3210029295865213498473_1516703643922&_='+str(curr_time)
2.爬虫统计答案关键词并给出推荐结果
百度搜索问题,并统计答案在搜索结果中出现的次数(待优化):
search_url = "http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=" + answer_title[answer_title.rfind('.',1)+1:len(answer_title) - 1]
html = requests.get(search_url)
html = html.text
dict_count = {}
dict_count[answer_answers[0]] = {'count':html.count(answer_answers[0])}
...
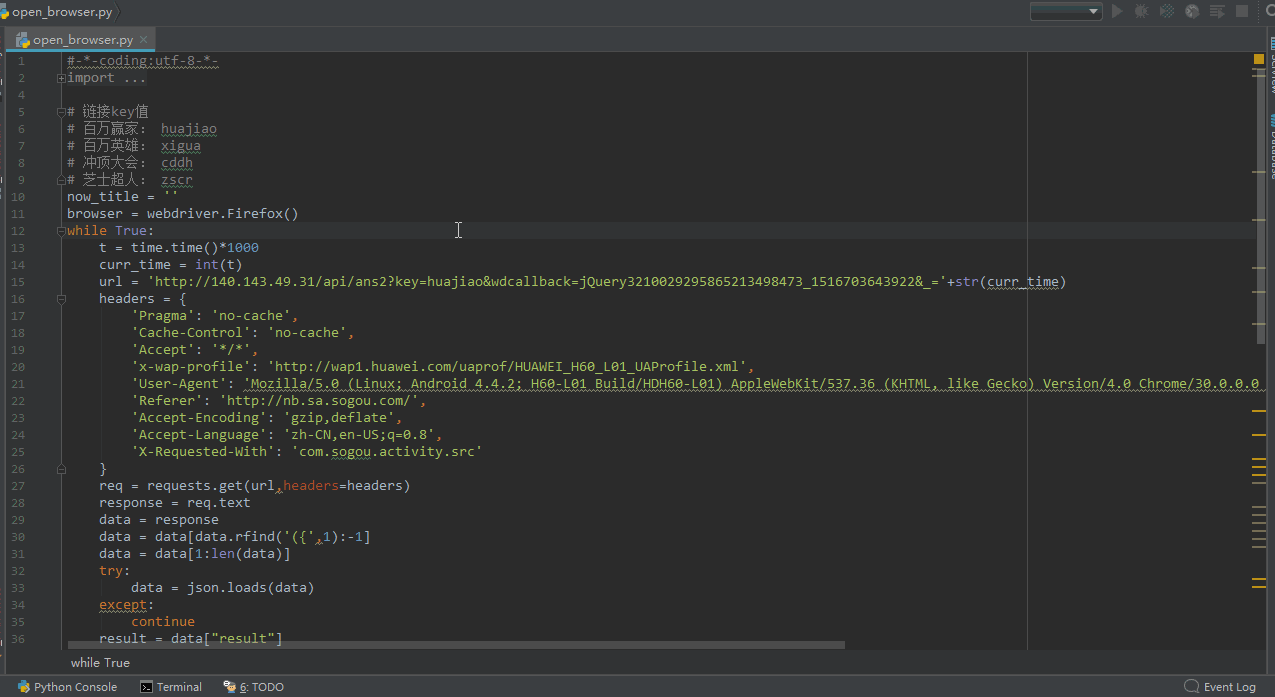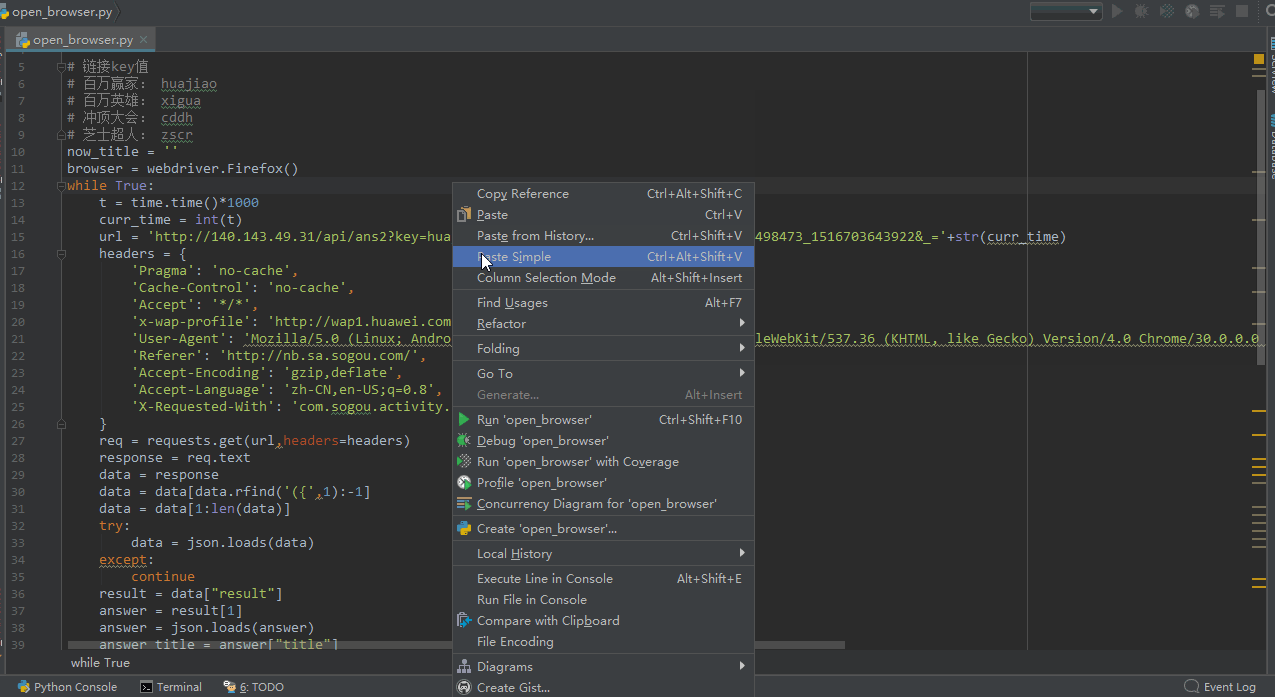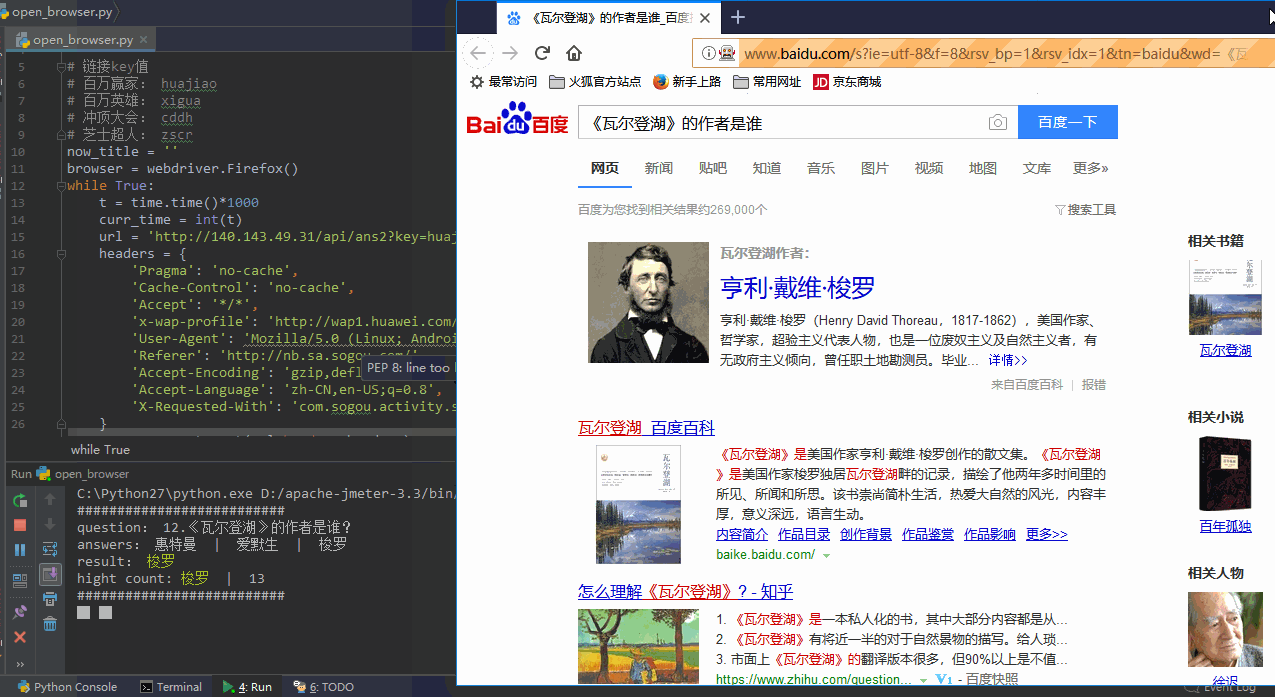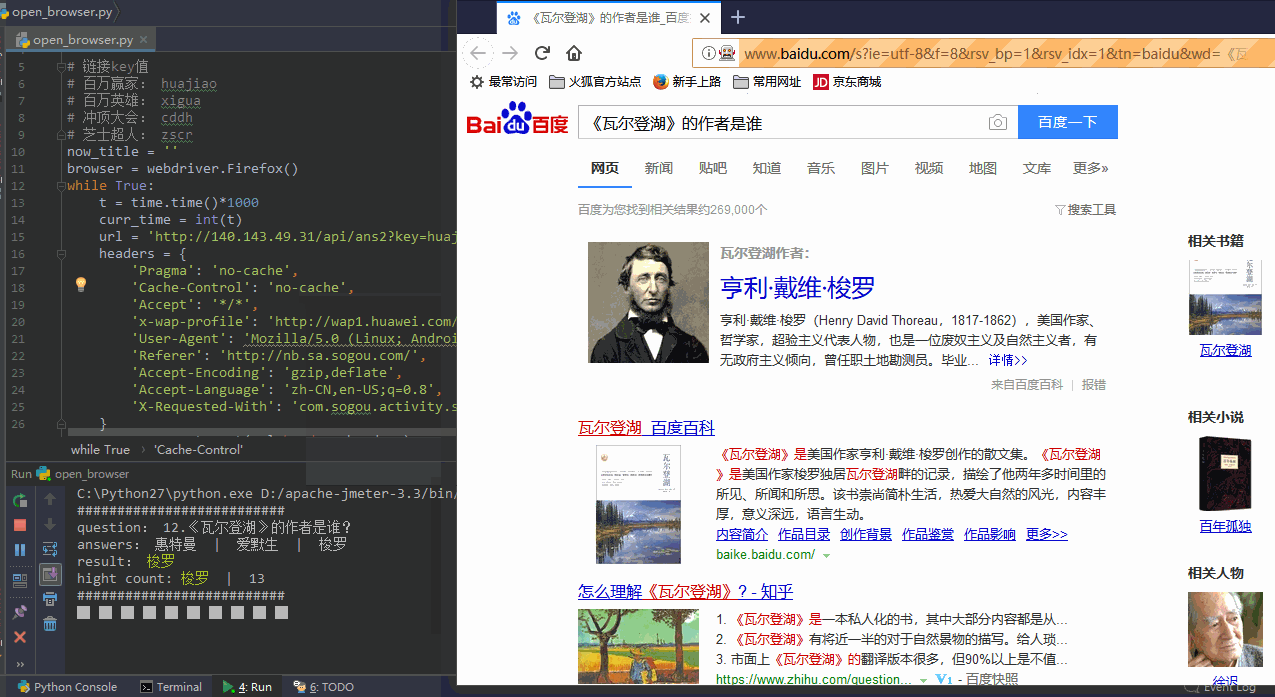
3.浏览器显示搜索结果
调出用浏览器并显示问题的搜索结果:
browser.get(search_url)
完整脚本如下:
#-*-coding:utf-8-*-
from selenium import webdriver
import requests,json,time
# 链接key值
# 百万赢家: huajiao
# 百万英雄: xigua
# 冲顶大会: cddh
# 芝士超人: zscr
now_title = ''
browser = webdriver.Firefox()
while True:
t = time.time()*1000
curr_time = int(t)
url = 'http://140.143.49.31/api/ans2?key=zscr&wdcallback=jQuery3210029295865213498473_1516703643922&_='+str(curr_time)
headers = {
'Pragma': 'no-cache',
'Cache-Control': 'no-cache',
'Accept': '*/*',
'x-wap-profile': 'http://wap1.huawei.com/uaprof/HUAWEI_H60_L01_UAProfile.xml',
'User-Agent': 'Mozilla/5.0 (Linux; Android 4.4.2; H60-L01 Build/HDH60-L01) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/30.0.0.0 Mobile Safari/537.36 SogouSearch Android1.0 version3.0 AppVersion/5909',
'Referer': 'http://nb.sa.sogou.com/',
'Accept-Encoding': 'gzip,deflate',
'Accept-Language': 'zh-CN,en-US;q=0.8',
'X-Requested-With': 'com.sogou.activity.src'
}
req = requests.get(url,headers=headers)
response = req.text
data = response
data = data[data.rfind('({',1):-1]
data = data[1:len(data)]
try:
data = json.loads(data)
except:
continue
result = data["result"]
answer = result[1]
answer = json.loads(answer)
answer_title = answer["title"]
if now_title != answer_title:
count = 10
now_title = answer_title
answer_answers = answer["answers"]
answer_result = answer["result"]
default_title = '大家'
default_title = default_title.decode('utf-8')
if default_title in now_title:
print '还没开放'
else:
print "##########################"
print "question:",answer_title
print "answers:",answer_answers[0],' | ',answer_answers[1],' | ',answer_answers[2]
print "result:", '\033[5;32;2m%s\033[0m' % answer_result
search_url = "http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=" + answer_title[answer_title.rfind('.',1)+1:len(answer_title) - 1]
html = requests.get(search_url)
html = html.text
dict_count = {}
dict_count[answer_answers[0]] = {'count':html.count(answer_answers[0])}
dict_count[answer_answers[1]] = {'count':html.count(answer_answers[1])}
dict_count[answer_answers[2]] = {'count':html.count(answer_answers[2])}
dict = sorted(dict_count.iteritems(), key=lambda d: d[1]['count'], reverse=True)
if dict[0][1]['count']>0 and dict[0][1]['count'] != dict[1][1]['count'] :
print "hight count:", '\033[5;32;2m%s\033[0m' % dict[0][0], " | ", dict[0][1]['count']
print "##########################"
browser.get(search_url)
if count > 0:
print '▇',
count -= 1
数据是死的人是活的,大厂 AI 都跪了,关键词统计推荐结果仅供参考。
「原创声明:保留所有权利,禁止转载」
如果觉得我的文章对您有用,请随意打赏。您的支持将鼓励我继续创作!
 AI 也怕搅屎棍啊,你有爬虫搜答案,大厂也有机器人注水大量上传错误答案啊
AI 也怕搅屎棍啊,你有爬虫搜答案,大厂也有机器人注水大量上传错误答案啊