有不少用户好奇 Appetizer 截获 http 请求的原理,主要关心:1)会搜集什么数据,会不会搜集到敏感的信息; 2)我的 apk 的一些请求无法截获为什么;3)https 的请求能截获么;这里来一并解释一下:
插桩,就是基于一定规则自动在代码里面打点,例如如果程序有这样的请求代码,通过 java 标准库的 HttpURLConnection 发出请求:
URL url = new URL("http://www.example.com/comment");
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setDoOutput(true);
connection.setRequestMethod("POST");
OutputStreamWriter writer = new OutputStreamWriter(
connection.getOutputStream());
Appetizer 做的就是在代码里面查找openConnection()这个函数调用,在它的后面插桩数据搜集代码,例如:
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
Appetizer.collect(connection); // 把这个请求的信息保存下来
Appetizer log 的信息包括:url,请求发发,请求参数(http request header),返回头(response header);不 log 请求体 (request body) 和返回体(response body);简单来说,只是请求的参数信息,不包括具体传递的 POST 数据和返回内容,所以安全上,Appetizer 不搜集 APK 的敏感请求数据
那大家在 apk 中可能会用不同的 http 库,比如常用的 okhttp 等等,Appetizer 的做法是对于每一个 http 都有相应的规则去搜集数据。虽然开发中可能会用到很多不同的 http 库,事实上绝大多数的库都是对一些基本库的再次封装(尤其是那些所谓的快速开发框架,基本都是用了 okhttp 来做 http 请求的)。所以 Appetizer 通过截获底层的这些库来支持包括 HttpURLConnection, Apache HTTP client, okhttp 2/3,retrofit, volley 等。同时 https 是完全可以截获的,不同于一些抓包工具,抓包工具的原理是代理,而 https 的设计是防止代理软件看请求内容的,所以抓包工具需要额外配置伪造的证书等等麻烦的事情;而 Appetizer 完全是打点,采集的数据好比在源代码里面能看到的数据一样,没有这个问题,https 请求的内容可以完全抓到
不支持的情况包括:
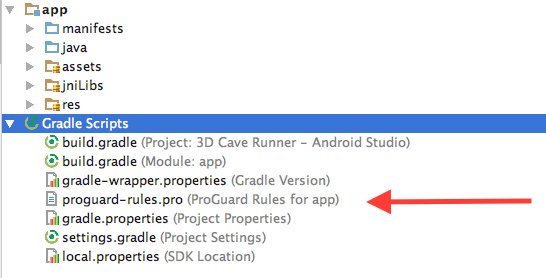
绝大多数的 http 库都不受到混淆的影响,唯一有问题的是 okhttp,我们观测到强力的混淆会去除 okhttp 一些功能,导致 Appetizer 无法正常截获请求,解决方案是到proguard-rules.pro里面,添加一下规则防止混淆 okhttp,首先找到这个规则文件:
然后添加
-keep class okhttp3.** { *; }
-keep interface okhttp3.** { *; }
-dontwarn okhttp3.**
-keep class com.squareup.okhttp.** { *; }
-keep interface com.squareup.okhttp.** { *; }
-dontwarn com.squareup.okhttp.**
-keep class okio.* { *; }
-keep interface okio.* { *; }
-dontwarn okio.**
这些字段保证混淆器不会删除 okhttp 的功能,Appetizer 就能正常工作了。
