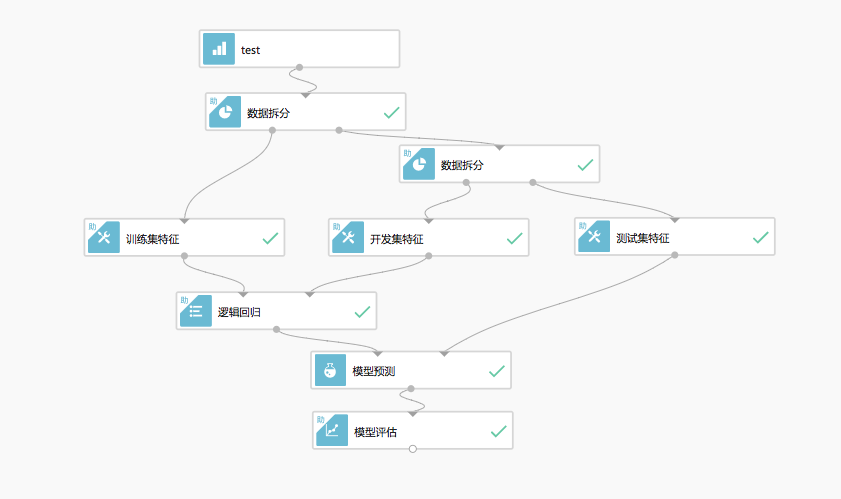
我们在模型训练的时候通常会将我们所得到的数据分成三部分。 分别是 training set, dev set(也叫 validation set) 和 test set。 在我们的模型调研过程中,他们分别起着不同的作用。training set 用来训练模型, dev set 用来统计单一评估指标,调节参数, 选择算法。 test set 则用来在最后整体评估模型的性能。
如上图,假设我们有一份数据,会将它按一定的规则进行拆分。其中 training set 和 dev set 分别输入到了逻辑回归算法中,而 test set 则是在模型训练结束后,被输入到模型中评估结果。 我们可以根据 report 来看一下他们各自的作用。 尤其是 dev set 和 test set,在很多文章中对他们的介绍很模棱两可,让人搞不明白他们之间到底有什么区别。 给我的感觉就是写文章的人也不懂,在那里随便写写罢了。 我们先看 training set 和 dev set,因为他们都被输入到了模型训练算法中。
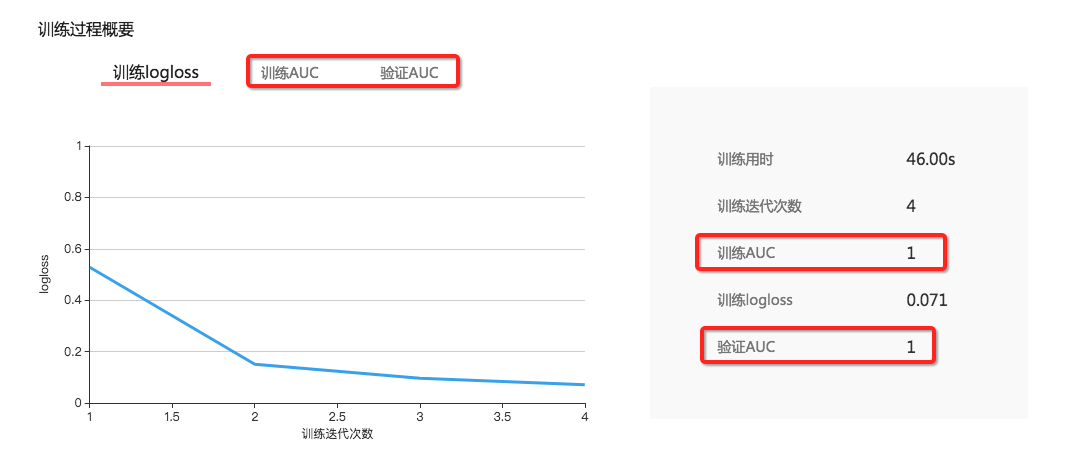
上图是模型训练的 report。 我们可以从中看到 training set 和 dev set(图中叫验证集) 的 auc 指标。这里便引入了 dev set 的作用, training set 很好理解,训练模型用的。 而 dev set 的作用就是在这里很方便的评估算法的单一评估指标,在这里也就是 auc,通过这个指标在 training set 和 dev set 上的对比我们可以用来调整算法参数。 例如,如果 training set 的 auc 是 0.9 而 dev set 的 auc 确是 0.6. 根据之前学到的我们很可能发生了过拟合的情况。 需要减少迭代次数或者设置 L2 正则来减少拟合。 又或者说我们发现训练 AUC 和验证 AUC 的数值都很低,例如只有 0.6, 而 loss(损失函数) 仍然没有收敛,我们可能要增加迭代次数或者是扩大数据集或者改变特征。 这就是 dev set 的作用, 它是与 training set 一起被输入到模型算法中但又不参与模型训练,我们一边训练一边在 dev set 上看 auc。这样相比于在 test set 上进行评估可以节省大量的时间。 我们在最开始的图中可以看到,使用 test set 会增加额外的步骤。 在我们调参阶段完全没有必要。只有当我们觉得当前的模型在 dev set 的效果已经差不多的时候,才会使用 test set 进一步验证模型性能。 那么 dev set 和 training set 有什么区别么? 看上去好像都是用来评估模型好坏的,特意在 test set 上进行验证又有什么用呢? 因为 test set 能够提供更多的评估模型的指标。 我们之前说过评估一个分类器有混淆矩阵,有 ROC,有召回,精准,F1 Scroe 等。 这些都是在 dev set 上不做统计的,dev set 上只统计单一评估指标,也就是 AUC。 例如下面是 test set 的评估报告
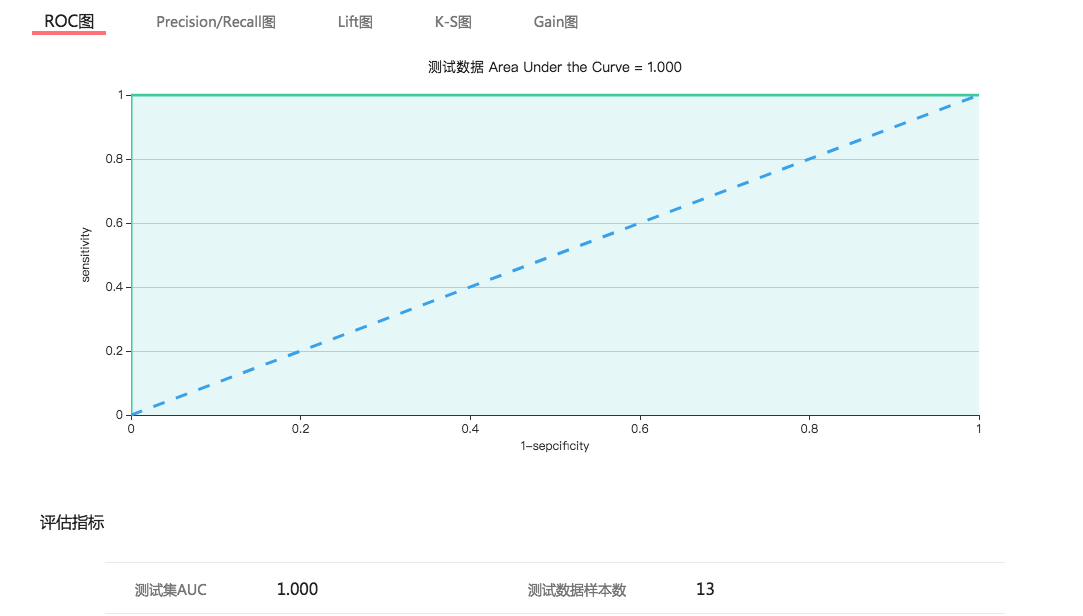
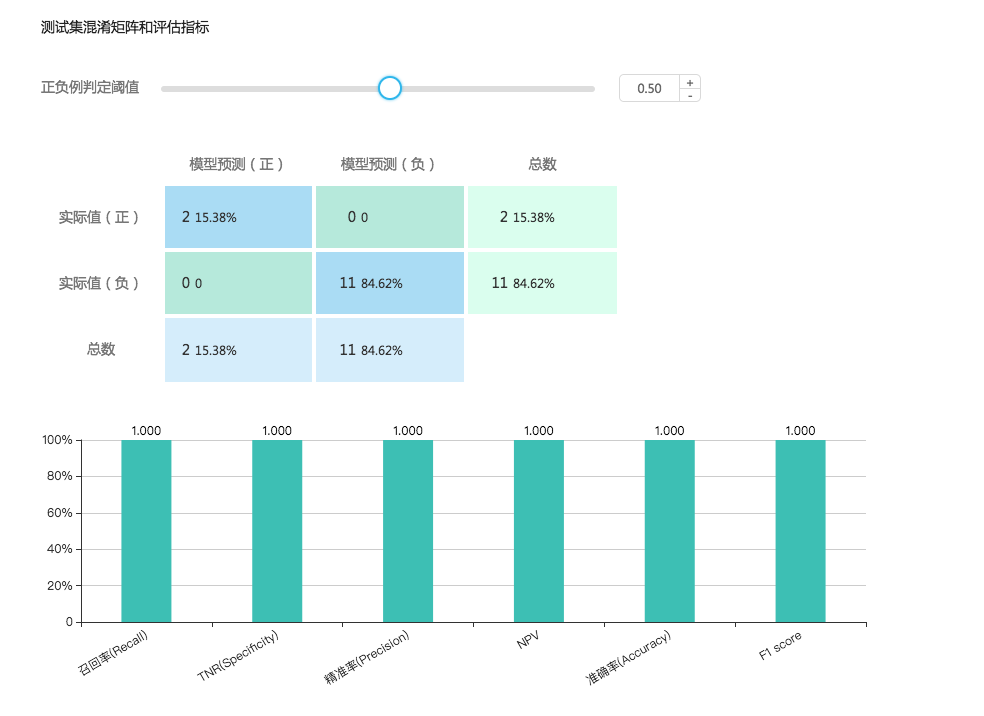
我们用 training set 做训练, dev set 来初步评估结果,这里的评估结果是单一评估指标,也就是对模型来说最重要的一个指标,在这里我们使用 AUC。 这么做的优点是 dev set 跟随 training set 一起被输入到模型算法中但又不参与模型训练。只是用来快速评估 AUC 的, 在调参阶段我们会不停的改变参数值来调整模型,而 dev set 就能帮助我们快速的查看结果。 相反的 test set 的作用并不是快速查看结果的,它提供一个模型的完整评估报告。可以更好的从多个维度评价模型的性能,但缺点是要做很多其他的操作,比较费时。我们一般在 dev set 上把参数调整的差不多后,才会使用到 test set。
现在我们知道要把数据拆分成 3 份,那么我们需要有一定的规则拆分数据集。 在老的规则里,也就是大数据时代之前。可能的规则是数据按照 8:1:1 来拆分。dev set 和 test set 不能太小,小了不能很好的评估模型效果。 但这个规则是建立在数据集比较小的情况下,例如只有 1w 条数据或者更小。 在大数据时代小,我们一般面临的都是百万级甚至亿级的数据量。这时候的拆分规则就会变化一下。比如我们有一百万行的数据,那么这时候的拆分就不能按照 8:1:1 来了。 可能是 98%:1%:1% 的规则比较合适,因为百万级的数据即便只有 1% 也有一万行,用来评估模型效果已经有了比较不错的效果。把更多的数据留给 training set 来获得更好的模型是比较好的选择。
我们的数据都是有业务含义的。 所以我们拆分的时候出了要考虑数据量以外可能还要考虑一些场景。 首先说 dev set 和 test set,他们都是用来评估模型性能的,所以一定要保证他们的数据处于同一分布。 举个例子说,如果我们统计的是 8 个国家的数据,如果我们选择 4 个国家的数据作为 dev set, 另外 4 个国家作为 test set 可以么? 这是明显不可以的,他们的数据处于不同的分布上。 如果我们在这样的 dev set 上进行调参并训练模型。 那到了 test set 上的时候你会发现模型效果极其的差。 所以我们要牢记于心的规则就是 dev set 和 test set 一定要处于同一分布。 在这里例子,我们要让 dev set 和 test set 随机的从所有国家中平均的抽取数据。 例如说每个国家有 100 份数据。 那么我们要保证 dev set 和 test set 能在每个国家中都随机抽取 50 份数据。
那么 traning set 呢? 理论上 traning set 最好也是要跟 dev set 和 test set 处于同一分布的。但有些时候我们不能这么做,比如说我们的数据是有时序性的。例如预测点击率这种场景中,数据的时序性是很重要的。因为新闻,视频或者音频等资源的时效性比较强。 这时候如果让 traning set 与 dev set,test set 处于同一分布就会有问题。 例如如果我们从数据中随机的拆分就会有问题。这样拆分甚至会出现用未来的数据预测过去的行为。 而我们希望的是用过去的数据预测未来的数据。 所以这时候我们应该做的是首先按时间把数据分成两类 ---- 过去的数据和未来的数据, 或者说是按一个时间点拆分成两种数据,处于这个时间点之前的数据作为 traning set。 这个时间点之后的数据作为 dev set 和 test set。 这时候我们再按照上面的规则,保证 dev set 和 test set 处于同一分布就好了。 所以关于 training set 的选择要根据数据的业务场景来定。
这是我总结出的关于拆分数据的一些规则。
