Selenium selenium:偏爱 xpath 的若干个理由
相信用过 selenium webdriver 的人都可以列举出其支持的几种 locator:id,name,className, tagName, linkText,xpath,cssSelector 等等。其中最常用的应该是前几个,原因无外乎两个:1. 用法简单;2. 运行效率高。但这两个优点却无法掩盖在实际操作中无法满足需求的不足,有时我们不得不选用 xpath 和 cssSelector。与其被迫选用,不如直接去发现它们的美。鉴于 cssSelector 和 xpath 有诸多相似,且用法上更为简单,于是在这篇文章中我将集中火力介绍一下 xpath。
瑜不掩瑕:id,name,className, tagName, linkText
用法简单与否
所谓任何事物都有两面性,把这句话应用到 locators 上,我觉得可以说用法简单往往意味着可发挥空间小。
- id:id 值通常是唯一的,这个优点确实很好,省去了潜在的应对多个匹配的问题。但一旦 id 值经常变化,或者开发压根没有定义 id 值,那这个方法就完全无用。
- name:和 id 一样,它同样存在可能没有被定义的情况;与 id 不同的是,它还可能存在重复值。
- className:不仅存在未定义、重复值的问题。对于形式为<div class="class1 class2 class3" />的元素,webdriver 提供的 className 方法就无法应对了,据我所知目前这个方法无法处理空格分隔的多个 class 名。
- tagName:多用于 drop downs, check boxed, radio buttons 等元素,不适用于其他元素。
- linkText:它只适用于超链接,与 partialLinkText 相配合,对于 < a > 元素来说是相当得力的 locator,但也只适用于< a >元素。
运行效率的高低
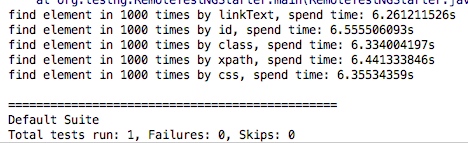
关于这点按理说很容易验证,我用形如下面的代码,循环 1000 次,用不同的方法定位同一个元素,统计每种方法的用时。
long startTime = System.nanoTime();
WebElement test = webDriver.findElement(By.certainMethod());//使用任一种locator
long endTime = System.nanoTime();
elapseTime =endTime - startTime;
结果如下图,运行时间多少的排位并不确定,运行 1000 次的总时间相差不会超过 1s,而且查找 id 的方法并不是最快速的,虽然我这种验证方法并不完善,但就这一情况而言,运行效率的高低至少不是限制我们选择 xpath 和 css 的理由。

瑕不掩瑜:xpath,cssSelector
众所周知,xpath 的形式复杂多变,学习成本更高。但没有无缘无故的恨,也没有无缘无故的爱。如果不是在使用简单常用 locator 时遇到无法解决的问题,我想我应该也不会舍近求远的采用 xpath 和 cssSelector。下面简单举几个例子吧。
- 对于下面这种没有 id,没有 name,多个 class 的元素,我们通常需要求助于 css 和 xpath。
<table summary="Search Results" class="x1ii x1j6" style="table-layout: fixed; position: relative; width: 1238px;" _totalwidth="583" _selstate="{'0':1}" _rowcount="1" _startrow="0" cellspacing="0"><colgroup span="3"><col style="width: 866px;"><col style="width:161px;"><col style="width:211px;"></colgroup><tbody><tr _afrrk="0" class="xe8 p_AFSelected"><td style="width: 855px;" class="xe9" nowrap=""><a id="pt1:r1:0:r0:1:AP1:t1:0:cl2" class="xjk" onclick="return false;" href="#">Manage Profile Content Section Access</a></td><td style="width:150px;" class="xe9" nowrap="">Task</td><td style="width:200px;" class="xe9" nowrap=""> </td></tr></tbody></table>
webDriver.findElement(By.cssSelector("table[summary='Search Results']")
webDriver.findElement(By.xpath("//table[@summary='Search Results']"));
- 对于想要定位 table 中一个 cell 元素时,xpath 往往也是最有效的,例如将上面例子中的 html 文本稍作修改,去掉 table 中第一个 td 的超链接,想要定位该 td 元素,或是该 table 中其他拥有相似属性的 td 元素,对 xpath 来说都是小菜一碟。
<table summary="Search Results" class="x1ii x1j6" style="table-layout: fixed; position: relative; width: 1238px;" _totalwidth="583" _selstate="{'0':1}" _rowcount="1" _startrow="0" cellspacing="0"><colgroup span="3"><col style="width: 866px;"><col style="width:161px;"><col style="width:211px;"></colgroup><tbody><tr _afrrk="0" class="xe8 p_AFSelected"><td style="width: 855px;" class="xe9" nowrap="">Manage Profile Content Section Access</td><td style="width:150px;" class="xe9" nowrap="">Task</td><td style="width:200px;" class="xe9" nowrap=""> </td></tr></tbody></table>
webDriver.findElement(By.xpath("//table[@summary='Search Results']/descendant::td[1]")
- 对于下面这种想要根据元素文本内容来定位的非链接类元素,我们也通常需要运用 xpath。xpath 提供的函数对于定位元素来说,有时简直是救命的。
<td class="xe9" nowrap="">Career Potential</td>
webDriver.findElement(By.xpath("//td[contains(text(),'Career Potential')]"));
为了应对这些特殊情况,也为了让程序更通用、更稳健,我决定多多学习和采用 css 和 xpath 作为 locator。
探究 xpath locator 的奥秘
xpath 基本形式
xpath 基本语法形式为:Xpath=//tagname[@attribute='value']。我在 webdriver 学习资料中见过两种形式,单斜线开头的 “/html/body/div[2]/form/div/div[1]/div/div/div/div[1]/div/div/div/div/div/div[2]/table/tbody/tr/td[4]/table/tbody/tr/td[2]/div/div” 和 双斜线开头的 “//*[@id="pt1:_UIScmil1u"]”。
- 单斜线开头的 xpath 路径是绝对路径,一般的 HTML 页面中的元素在绝对路径的 xpath 里显示的均为 html -> body -> 之后元素的形式。一般路径会很长,而且一旦页面有任何修改,都可能会影响定位其他的元素。
- 双斜线开头的 xpath 路径是相当路径,对应的是整个页面中斜线后紧跟标签对应的所有元素开始的路径。这种方法较常用,且稳健,但使用起来会有变形和需要避开的误区,我将在后面独立章节来说明。
获取 xpath 路径,一般可以借助工具,譬如 Firefox 或是 Chrome 浏览器自带的 inspector 工具。这种工具使用时有如下情况:
- 如果对应元素有唯一的 id 值,工具自动生成的 xpath 就会是 “//*[@id="pt1:_UIScmil1u"]” 形式,其中星号代表任何标签,因为 id 号是唯一的,元素也就是唯一的。
- 如果没有定义 id 值,那么自动生成的 xpath 路径就会是单斜线开头的绝对路径,虽然可以直接使用,但还是建议手动修改成相对路径。
这样来看,其实直接手动编写 xpath 反倒可能来的更痛快些。
xpath 支持的函数
下面的代码针对的是 “ http://demo.guru99.com/v1/ ” 和 “ http://demo.guru99.com/selenium/guru99home/ ”,大家也可以拿这两个网站试试手,看看能不能用 xpath 定位你想要的元素。
- text() 方法:与属性同等地位,指的是元素显示在页面上的文本,常与下面将介绍的 contains() 方法配合使用,也可以直接用等号与字符串做完整匹配。
By.xpath("//*[text()='UserID']");
- contains() 方法:前文中我就用它做过例子,类似 partialLinkText,只是这里的 partial text 可以来自于元素的各种属性。比如下面的代码就给出了部分匹配 type 属性、name 属性和文本属性的 xpath。
By.xpath("//*[contains(@type,'sub')] ");
By.xpath("//input[contains(@name, 'btn')]");
By.xpath("//*[contains(text(),'Login')]");
- or & and 条件:有时我们需要多于一个条件来判断元素,用到多个条件的与运算或是或运算,这里需要用的就是这两个符号。具体代码如下。这里需要指出的是,有的资料里写的 and 和 or 是大写形式,我在 Chrome 工具和 IntelliJ 里试了下,大写不好使,得用小写。
By.xpath("//div[@id='rt-feature' and @class='rt-grid-12 rt-alpha rt-omega']");
By.xpath("//*[contains(@name,'btn') or contains(text(),'User')]");
- start-with 方法:常用于作为匹配条件的元素属性尾部分常常动态变化的情况,比如 Id=" message12", Id=" message345",Id=" message8769"
By.xpath("//label[starts-with(@id,'message')]");
- axes 方法:重中之重,不知道怎么翻译合适。用于匹配某个元素的 parent、child、sibling 等关系的其他元素。我试图找到更直观的方式来表现具体的元素之前的层级关系,最后决定用下面的 xml 代码来表示,虽然并不确定是否够直观。
- xml 代码中包含 axisname:ancestor、ancestor-or-self、child、descendant、descendant-or-self、following、following-sibling、parent、preceding、preceding-sibling、self。
- 对应的语法形式为:axisname::nodetag,如 child::div,following::* 等
- 需要注意的是:preceding 不包含 parent 和 grandparent 这些 ancestor;following 不包含 children、grandchildren 等
- xml 代码中缺少两个 axisname:attribute 可以用来得到属性;namespace 一般声明在 XSLT 里。这两个我都没有真正用过,就不在这里多说误导大家了。
<head>
<grandparent-ancestor1>
ancestor: includes parent, grandparent
<preceding1>
preceding: any nodes appear before self node, except ancestors, attribute and namespace nodes
</preceding1>
<parent-ancestor2>
<preceding2-precedingSibling1>
precedingSibling: sibling before self node
</preceding2-precedingSibling1>
<self>
current node
<child1-descendant1>
descendent: includes children, grandchildren
<grandchild1-descendant2>
inside self node, not following
</grandchild1-descendant2>
</child1-descendant1>
<child2-descendant3>
inside self node, not following
</child2-descendant3>
</self>
<followingSibling-following1>
followingSibling: sibling after self node
following: includes everything after the closing tag of self node
</followingSibling-following1>
</parent-ancestor2>
<following2>
following: includes everything after the closing tag of self node
</following2>
</grandparent-ancestor1>
</head>
xpath 实际使用中的小陷阱
这里我要简单列几个我遇到的小陷阱,希望可以帮助遇到相同的问题的人少走弯路。
双斜线的小秘密
直接上例子给大家看。http://demo.guru99.com/v1/ 这个网址里有下面这样一节代码,如果我用 xpath="//td//child::img" 搜索,那我得到的应该就是什么呢?如果用 xpath="//td//following-sibling::img" 搜索呢?
<tr>
<td align="center"><img src="../images/1.gif">
<img src="../images/3.gif">
<img src="../images/2.gif"></td>
</tr>
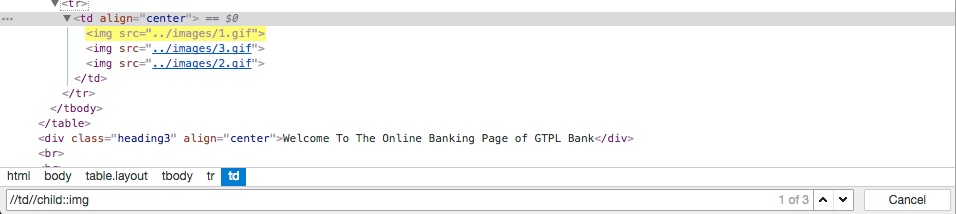
等等!img 那些元素怎么会是 td 的 sibling?明明是 child 呀! 这个问题让我纠结好久。最后发现问题来自于 xpath 中第二个双斜线。
按照前面我说的以双斜线开头的 xpath 是相对路径,而我最初参考的资料里 axes method 示例代码又都是长成 “Xpath=//*[@id='rt-feature']//parent::div[1]” 这种样子,于是我就想当然把相对路径中的每一个分隔符都用成了双斜线。这才导致了这个问题。
真正的双斜线有着自己的含义:/descendant-or-self::node()/*,根目录的 descendant 和根目录本身,用在路径的开头也就表示了根目录的所有 children、grandchildren 等等,也就是所有元素。之后接上一个元素标签,就限定了一种元素,从特定标签的元素位置为起点,也就是相对路径。
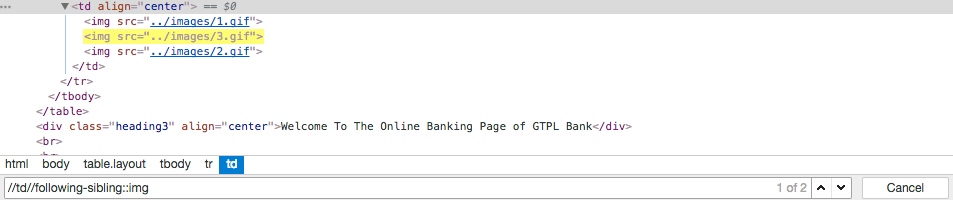
但是双斜线放在路径中间就有问题了。xpath="//td//following-sibling::img" 就相当于是/descendant-or-self::node()/td/descendant-or-self::node()/following-sibling::img",即:包含所有 td 元素的 following-sibling 以及 td 的 descendant 元素的 following-sibling。
说到这里你应该明白了吧,img 这些元素虽然不是 td 的 sibling,但第一个 img 是 td 的 descendant,查找这个 img 的 sibling,显然就找到了其他两个 img。这样也就让像我一样以为在寻找 td 的 sibling 的人大跌眼镜,殊不知结果集里混进了内鬼。
别小看一个空格
看到上面我贴的那段 html,有些强迫症的同志可能忍不住了,td 元素跟第一个 img 元素怎么挨那么近呀,我要改改,于是就变成了下面的情况。
<tr>
<td align="center">
<img src="../images/1.gif">
<img src="../images/3.gif">
<img src="../images/2.gif"></td>
</tr>
嗯,看起来顺眼多了,可是你再试试 xpath="//td//following-sibling::img"? 结果又变了!之前只匹配了 3.gif 和 2.gif,现在三个 img 全都匹配啦!不是说第一个 img 是 td 的 descendant,所以匹配另外两个 img 作为它的 sibling 吗?回车了一下,第一个 img 变成谁的 sibling 了?
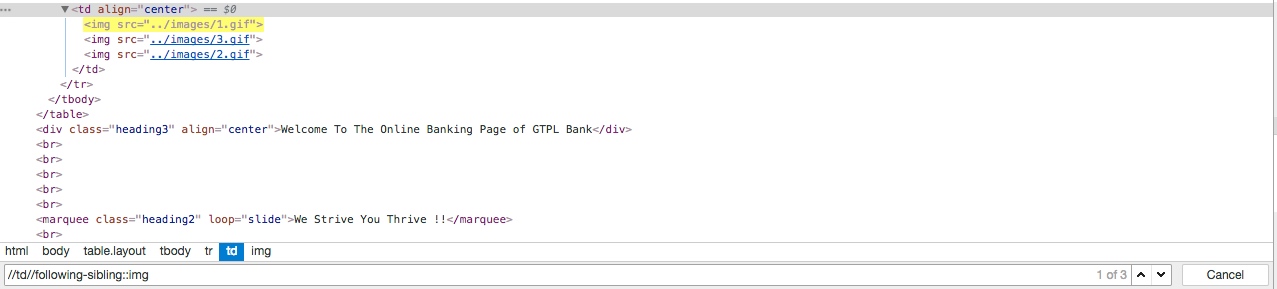
这是因为,有一种元素叫做whitespace text node,回车或是加一个空格,1.gif 那个 img 元素前就相当于多了一个元素。虽然你看不到他,一般也注意不到它,但它就在那里,默默地影响了结果。
从 1 开始的 index
前文介绍 xpath 可以处理的几种特殊场景的例子中,我用到了这样一段代码,这里 td[1] 代表的就是 table 中第一个 td 元素,对于习惯了程序员从 0 开始思维模式的人来说,这应该也算是需要注意的一个点吧。
webDriver.findElement(By.xpath("//table[@summary='Search Results']/descendant::td[1]")
另外,以 “https://www.guru99.com/” 为例,想要定位其中第一个 class 属性为 “fa fa-chevron-circle-right” 的 li 元素,如果你使用下面的第一条代码得到的并不是唯一的元素。为什么呢?这是因为 [] 运算符的优先级高于//运算符,下面的代码获取的是所有满足 1. class 属性为 “fa fa-chevron-circle-right”,2. 是其 parent 元素的第一个 child 的元素。而你想要的元素并不一定要求满足 2,而是应该满足所有满足 1 的 li 元素中的第一个。所以,应该用括号区分运算顺序。
webDriver.findElement(By.xpath("//li[@class='fa fa-chevron-circle-right'][1]") //可能得到很多匹配或者没有匹配
webDriver.findElement(By.xpath("(//li[@class='fa fa-chevron-circle-right'])[1]") //唯一一个匹配
不等于之争:not() VS !=
做多了 equal 判断,我不禁想知道 not equal 该如何使用。“ http://demo.guru99.com/selenium/guru99home/ ” 里有下面这样一段代码,两个 div 元素 id 相同,class 不同,想要匹配第二个 div 元素,我们可以用 id and class 的 xpath,但是想要匹配第一个 div 元素呢?
<div id="rt-feature">
...........
<div class="rt-grid-12 rt-alpha rt-omega" id="rt-feature"><div class="rt-grid-6 ">
..........
</div>
</div>
By.xpath("//div[@id='rt-feature' and @class='rt-grid-12 rt-alpha rt-omega']") //匹配第二个div
By.xpath("//div[@id='rt-feature' and @class!='rt-grid-12 rt-alpha rt-omega']")//匹配第一个div,不成功
By.xpath("//div[@id='rt-feature' and not(@class='rt-grid-12 rt-alpha rt-omega')]")//匹配第一个div,成功
!=和 not() 在 xpath 中均可以用来判断属性值相等与否,从语法上来说两者都是正确的用法。但!=没有成功匹配到第一个 div,not() 却可以,这是为什么呢?
xpath 官方协议(https://www.w3.org/TR/xpath/#booleans)中有这样一段话:
If one object to be compared is a node-set and the other is a string, then the comparison will be true if and only if there is a node in the node-set such that the result of performing the comparison on the string-value of the node and the other string is true.
也就是说@attribute!=value 判断的是元素必须有属性 attribute,但是值并不等于 value 的情况;而 not(@attribute=value) 则可以判断元素并没有属性 attribute 的情况。例子中第一个 div 并没有 class 这个属性,那么用!=判断时,无论 value 是什么,这个表达式都会返回 false。总而言之,如果目标是判断元素没有某个属性,或者属性值不是预期值,那么只能用 not();如果目标是判断元素一定有某个属性,但属性值不是预期值,则应该用!=。
总结
深究下来,xpath 的使用并不像我想的那么复杂,它同样是规则很明确的一种 locator,只是规则多了些而已。同理 cssSelector 的用法更不是什么难事,有兴趣的话,不妨多用一下。
用一种 locator,应对各种各样的情况,何乐而不为呢?
 实在定位不了的时候,才会使用 xpth
实在定位不了的时候,才会使用 xpth ,利用 text() contains() 等函数 加上 Axes 可以解决大部分元素定位的疑难杂症问题
,利用 text() contains() 等函数 加上 Axes 可以解决大部分元素定位的疑难杂症问题