from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.PhantomJS()
wait = WebDriverWait(driver, 10)
def open_bank_url():
print("打开银行页面")
try:
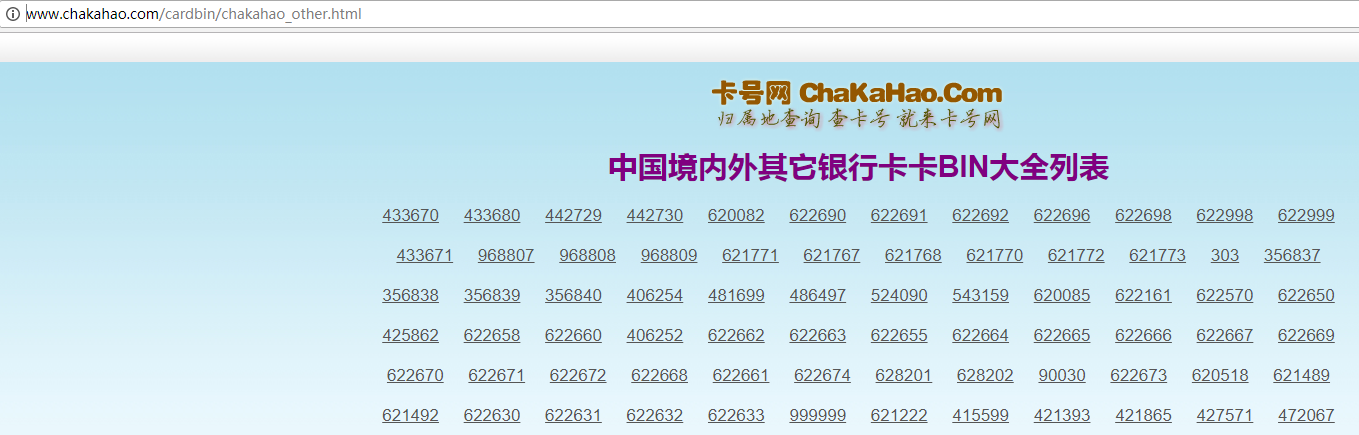
driver.get('http://www.chakahao.com/cardbin/chakahao_other.html')
driver.maximize_window()
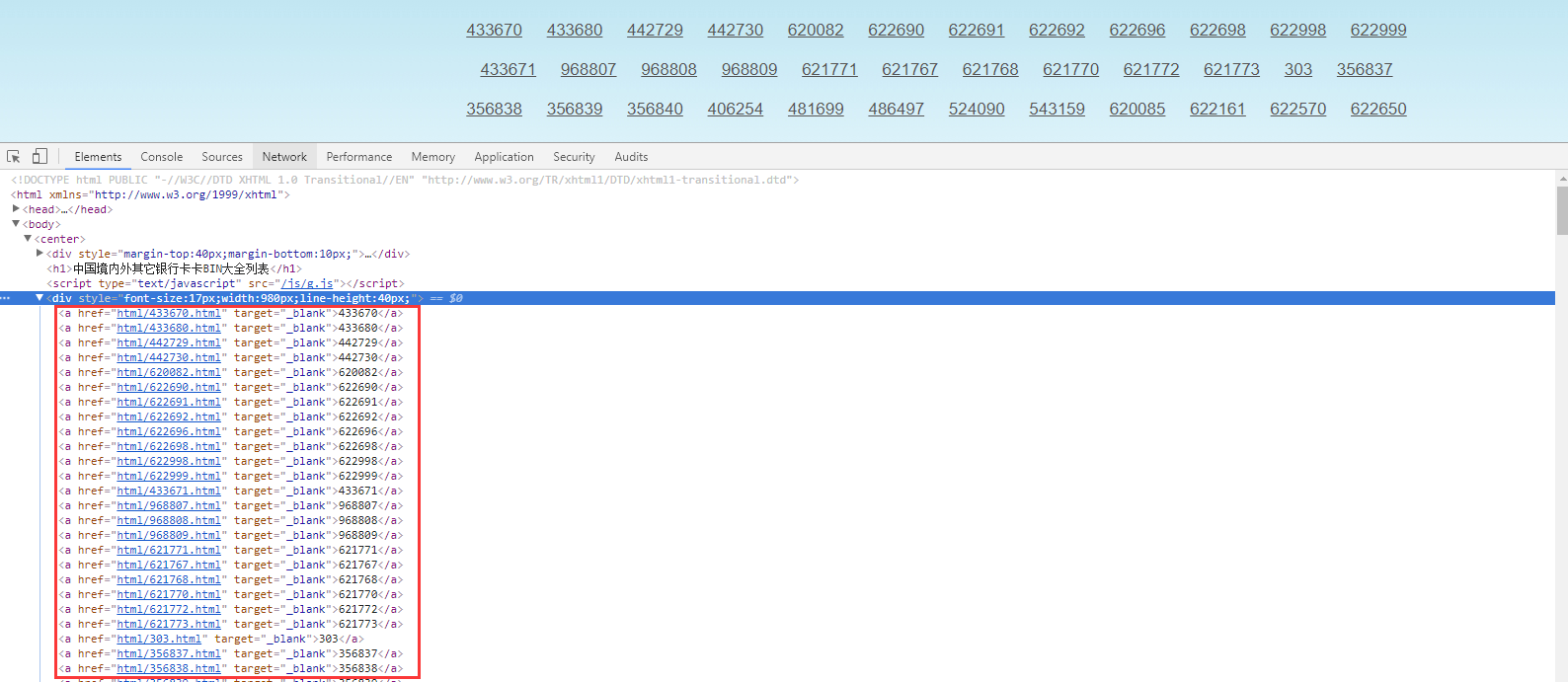
text = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, 'body>center>div:nth-child(4)')))
str1 = text.text.split(' ')
# print(str1)
for i in str1:
# print(i)
url = 'http://www.chakahao.com/cardbin/html/{0}.html'.format(i)
driver.get(url)
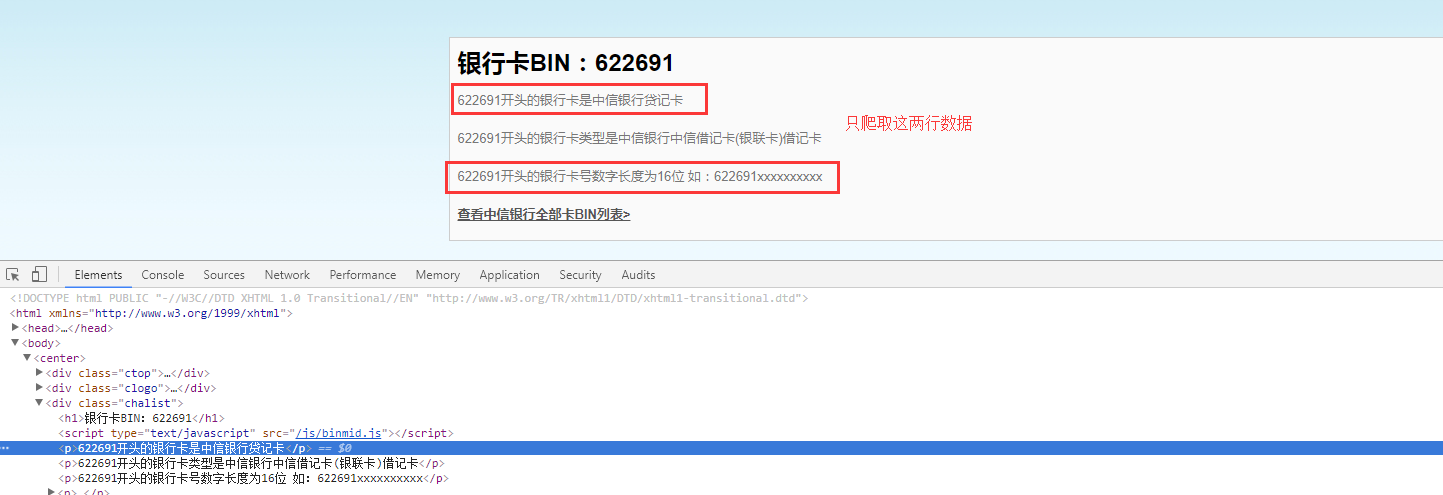
bank = driver.find_element_by_css_selector(".chalist > p:nth-child(3)")
bank_number = driver.find_element_by_css_selector(".chalist > p:nth-child(5)")
f = open("bank_text.txt", 'a') # 存储爬取到的银行卡的数据
print(bank.text, bank_number.text, file=f)
# driver.quit()
except TimeoutError:
print("NO")
open_bank_url()