现在网络上大多数关于 selenium 的资料还停留在 selenium2,实际上 selenium3 已经出了正式版,如果你想要对运行在新版浏览器上的程序进行自动化测试,那么升级到 selenium3 无疑是正确的选择。对比 selenium2 和 selenium3,最明显的区别,也是很多人在升级 selenium 之前最先遇到的问题,就是 Firefox driver 的问题,在这篇文章中我将尽我所能解释一下与此相关的问题,期待各位看官的批评指正。
在我看来,用户与浏览器的交互可以有很多种形式,作为测试,我们可以暂且不去关注这些操作中涉及到的技术细节,而是将这些交互过程简单的归结为发送请求与验证响应的产物。那么以这种用户与浏览器的交互为测试重点的基于 Web 的自动化测试的技术重点也就集中到了如何向服务器发送正确的请求和如何正确解析校验服务器返回的响应这两点上。(我一直纠结于基于 Web 的自动化测试、接口自动化测试和 UI 自动化测试这三个概念的区别。)依我的拙见来看,接口和 UI 自动化测试是基于 Web 的自动化测试的两个方面。不同之处在于接口自动化测试更直接处理 REQUEST 和 RESPONSE 本身;而 UI 自动化测试是将请求与响应隐藏在 UI 之下,向用户实际操作靠拢,即通过操纵页面元素发送请求,通过校验页面展示内容来校验响应。UI 自动化测试适用于浏览器页面对用户有直观影响的情况,而接口自动化测试则适用于对后台服务端代码的测试。也可以说接口自动化测试独立于浏览器,而 UI 自动化测试与浏览器密不可分。如果说接口自动化测试属于集成测试阶段,那么 UI 自动化测试则是系统测试的一环。
基于我在上一部分的总结,selenium 要想实现 UI 自动化测试,它就不得不解决模拟操纵页面元素和校验返回页面展示内容的问题,而这两个问题的共通之处就在于定位页面元素和操作页面元素两点,selenium 提供了大量的 API 接口实现这些功能。作为基础,在本文我想要关注的点就在于 selenium 如何控制打开浏览器,并访问一个网址。
大多数 selenium 入门教程都会在一开始介绍这么几个概念:selenium IDE、selenium RC、Selenium Grid、Selenium webdriver,在以后的文章中我们可能会再来关注它们。本文我只关注 Selenium webdriver。
单纯从名字来看,driver 嘛,就是一个驱动,是测试进行的动力来源。各位在 selenium 入门教程里看到的第一段代码应该就是下面这两行代码。
say Hi to WebDriver:
WebDriver driver = new FirefoxDriver();
webDriver.get("http://www.google.com");
作为 selenium 领域里和 hello world 比肩的入门级代码,你也许期待着这两行代码就可以启动浏览器,打开谷歌页面。但依我的个人经验来看,十有八九会在这里栽第一个跟头。
比如:
在谷歌上搜索相关问题的话,升级 selenium 或是降级 Firefox 会是最有效也是最费时的解决方案。

所以在测试之处,确定好要测试的浏览器版本后,一定要慎重选择与之匹配的 selenium 版本,一般来说最新的非 beta 版 selenium 和浏览器应该是比较好的选择。我在写这篇文章的时候选择的是两个组合 “FF32 和 selenium2.53.0”,“FF52 和 selenium3.5.2” 来做对比实验。
虽然通过更换版本可以解决上图中的错误,但这个错误信息仍然困扰着我。“Unable to connect to host 127.0.0.1 on port 7055”,这个信息到底代表着什么,又是从何而来呢?
1.首先定位目标浏览器的 binary 文件所在的位置,判定机器的 platform 类型。同时定义了 timeout 为 45000,也就是上面错误消息中的超时时间,以及其他初始化操作。
2.建立连接,启动 Firefox,主要代码集中在 NewProfileExtensionConnection.start() 方法中。
public void start() throws IOException {
addWebDriverExtensionIfNeeded();
...
port = determineNextFreePort(profile.getIntegerPreference(PORT_PREFERENCE, DEFAULT_PORT));
profile.setPreference(PORT_PREFERENCE, port);
profileDir = profile.layoutOnDisk();
delegate = new HttpCommandExecutor(buildUrl(host, port));
...
process.startProfile(profile, profileDir, "-foreground");
long waitUntil = System.currentTimeMillis() + connectTimeout;
while (!isConnected()) {
if (waitUntil < System.currentTimeMillis()) {
throw new NotConnectedException(
delegate.getAddressOfRemoteServer(), connectTimeout, process.getConsoleOutput());
}
...
从上面这段代码可以看到,程序添加了 extension,跟踪到内部实现,可以看到添加的 extension 是名为 webdriver.xpi 的插件。
private static Extension loadDefaultExtension() {
return new ClasspathExtension(FirefoxProfile.class,
"/" + FirefoxProfile.class.getPackage().getName().replace(".", "/") + "/webdriver.xpi");
}
之后 profile.layoutOnDisk() 方法,新建并暂存了一个 profile 文件,该文件包含了新添加的插件信息,同时记录了与添加的插件绑定的端口号,监听发往此端口的请求。下图看出 default 端口号为 7055,对应上文中的错误信息。

process.startProfile() 方法按照 profile 文件定义的配置信息,调用 Firefox binary 的可执行文件,启动浏览器。
跟踪到 startProfile() 方法内部,会看到其实它会启动一个新的线程执行异步命令,完成打开浏览器的操作,而主线程则通过 while 循环在一定时间段内不断检查浏览器是否成功打开。
public void execute(final CommandLine command, final Map<String, String> environment,
final ExecuteResultHandler handler) throws ExecuteException, IOException {
....
final Runnable runnable = new Runnable()
{
public void run()
{
int exitValue = Executor.INVALID_EXITVALUE;
try {
exitValue = executeInternal(command, environment, workingDirectory, streamHandler);
handler.onProcessComplete(exitValue);
}
....
};
this.executorThread = createThread(runnable, "Exec Default Executor");
getExecutorThread().start();
}

3.浏览器成功打开后,工程会发送请求新建一个 session,并记录 session 号,以备后续使用。
总结起来启动浏览器的整个过程就是:创建新的 profile 文件,该配置文件中记录了一个 webdriver 插件,按照该 profile 文件打开的浏览器会默认安装了 webdriver 插件,并记录插件的监听端口,该插件可以监听 selenium 工程发出的请求并打开浏览器。
我们来从后往前看关键代码:
1.下面这部分代码完成之后浏览器就将 Google 主页展示出来了。
public HttpResponse execute(
...
try {
HttpResponse response = doSendRequest(request, conn, context);
if (response == null) {
response = doReceiveResponse(request, conn, context);
}
...
}
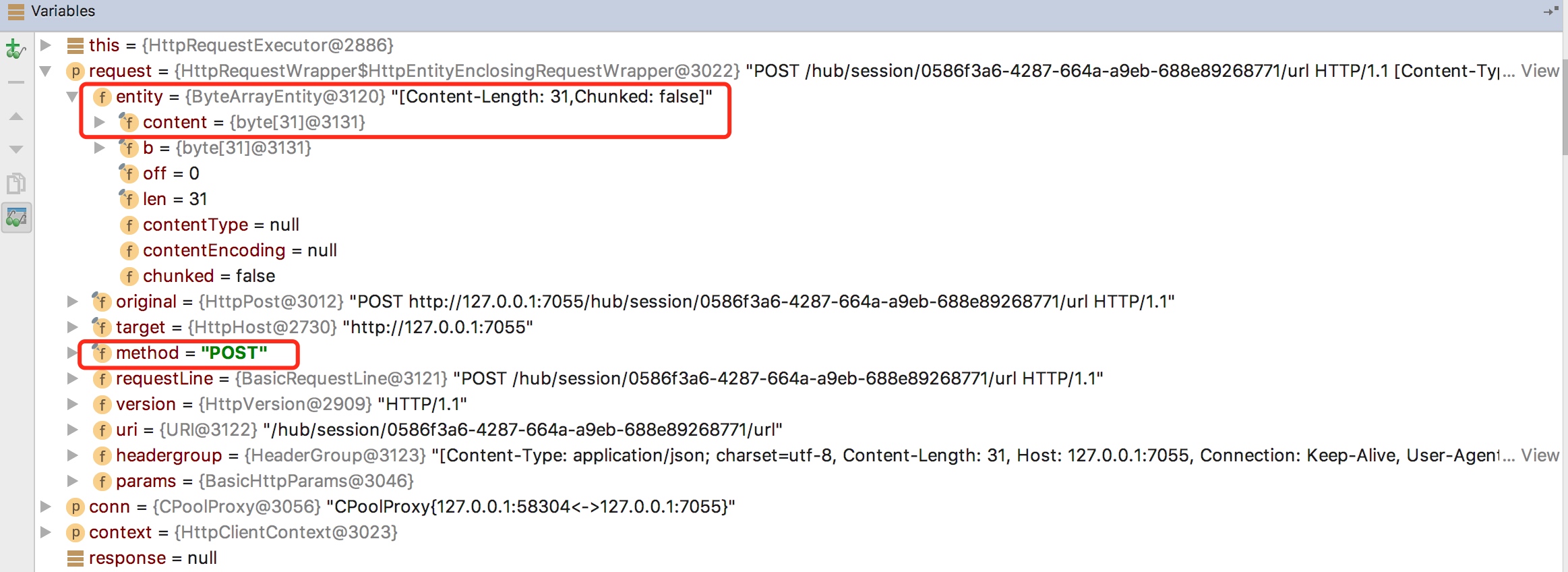
由此可以看出,我们写下的这行代码最终转换成了一个 POST 请求,发往 localhost:7055,路径被改写为"/hub/session/:sessionId/url"。而 "www.google.com" 这一网址则包含在了 entity 的 content 里。
2.将 selenium command 转化成 HTTP request 的步骤发生在 JsonHttpCommandCodec.encode() 方法内。
public HttpRequest encode(Command command) {
CommandSpec spec = nameToSpec.get(command.getName());
...
String uri = buildUri(command, spec);
HttpRequest request = new HttpRequest(spec.method, uri);
if (HttpMethod.POST == spec.method) {
String content = beanToJsonConverter.convert(command.getParameters());
byte[] data = content.getBytes(UTF_8);
request.setHeader(CONTENT_LENGTH, String.valueOf(data.length));
request.setHeader(CONTENT_TYPE, JSON_UTF_8.toString());
request.setContent(data);
}
if (HttpMethod.GET == spec.method) {
request.setHeader(CACHE_CONTROL, "no-cache");
}
return request;
}
对比 new FirefoxDriver() 和 get(url) 二个命令发送的请求可以发现,不同的 selenium command 可以转换成不同的 request。
new FirefoxDriver() :


get(url):

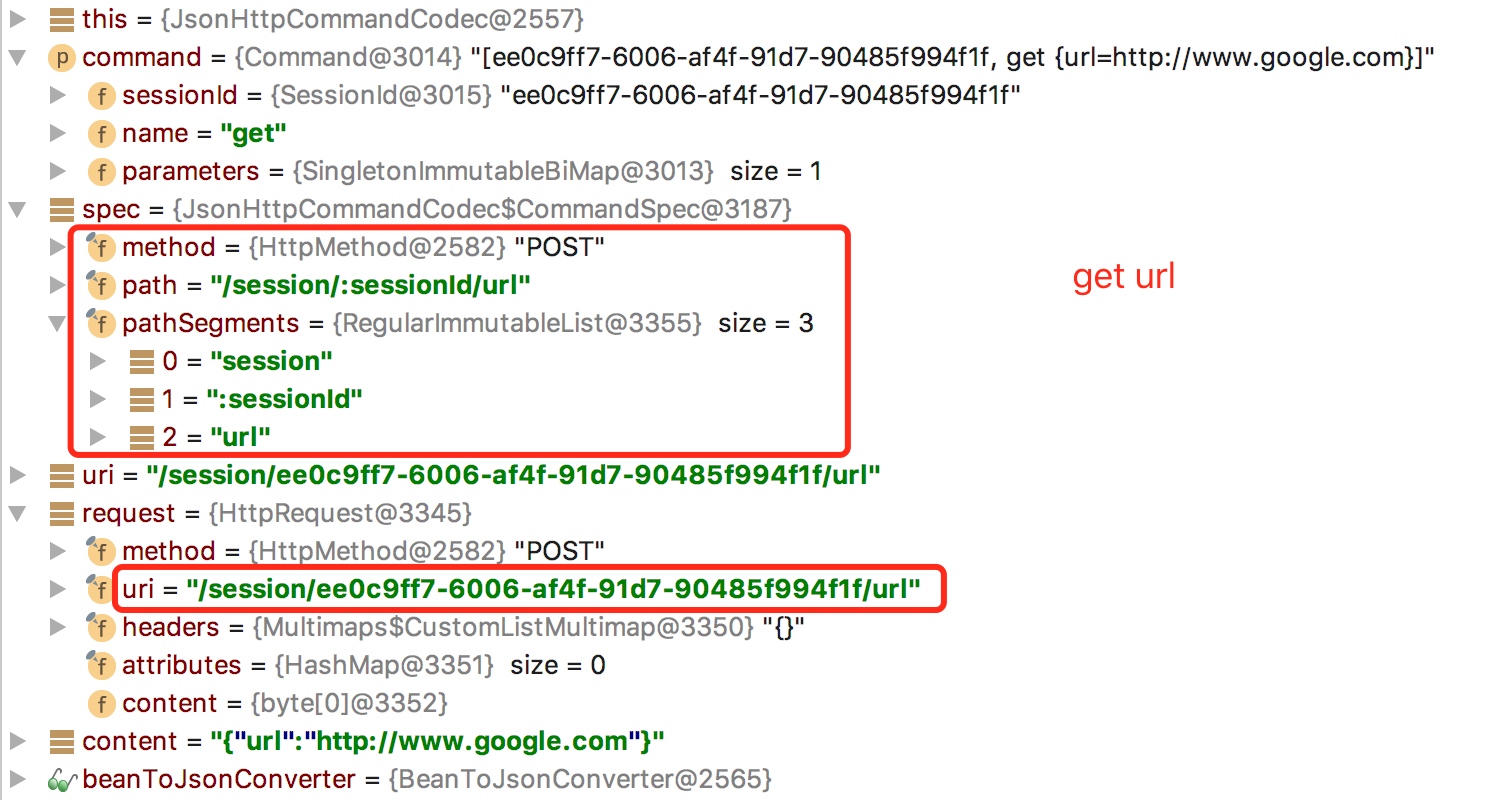
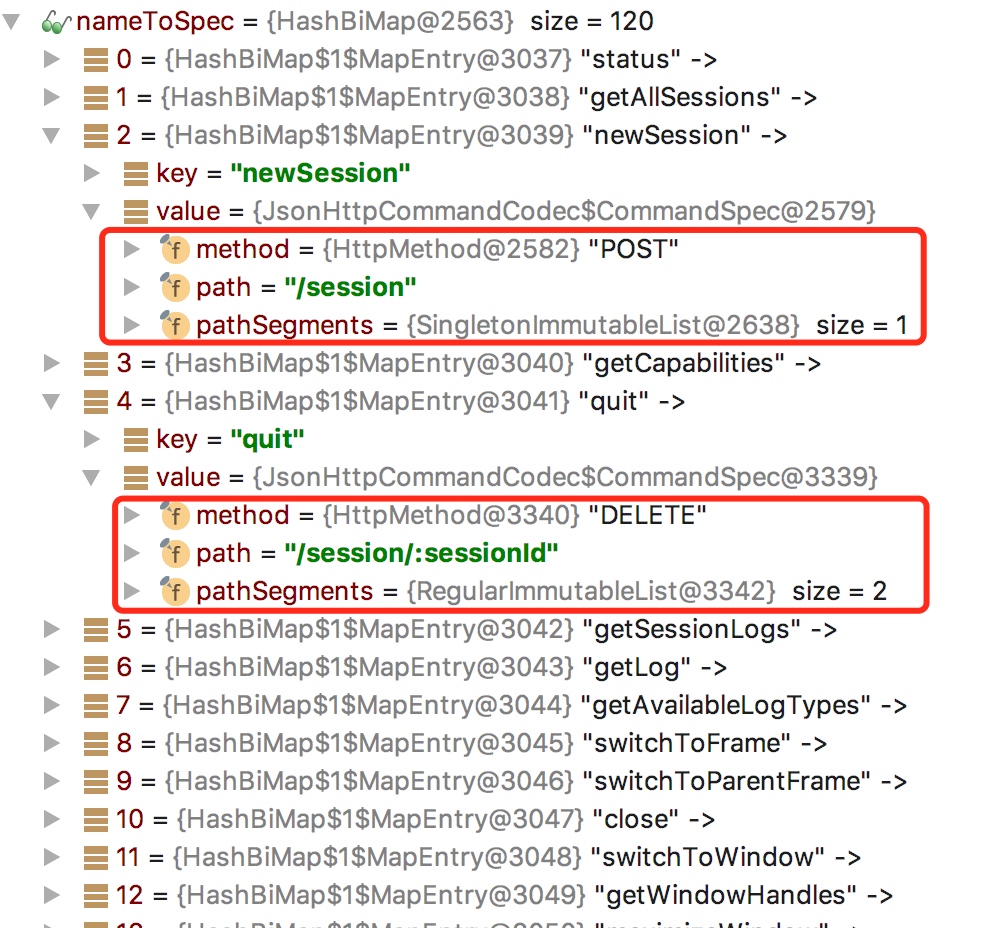
3.而具体一种 selenium command 转换成何种形式的 request,其关键则在于 command name 和 nameToSpec。可以看到 nameToSpec 是大小为 120 的 HashBiMap,其中的每一个元素的 key 对应 selenium command 的名称,value 则包含要转换的 request 的方法、路径等。new FirefoxDriver() 对应的 command 名称为 newSession,webDriver.get() 对应的 command 名称则是 get。二者对应的 request 方法均为 POST 请求,需要传递的数据则通过 beanToJsonConverter 转化成 byte 形式并存放在 entity 主体的 content 里。其他的 selenium command 也可以参考这种模式,如 quit 对应的方法为 delete。至此我想我已经解释清楚了 selenium 如何控制浏览器工作这一问题。
上一部分我解释了 selenium 通过添加 Firefox webdriver 插件的形式启动、控制浏览器的步骤,在 selenium 2 和 Firefox48 之前的版本中,如果出现无法用上述方法启动 Firefox 的情况,我们一般可以将原因归结为 selenium 提供的 webdriver 插件与对应版本的 Firefox 浏览器不匹配。但是对于 Firefox48 之后的版本,情况就不太一样了。
Starting from Firefox 53, no new legacy add-ons will be accepted on addons.mozilla.org (AMO) for desktop Firefox and Firefox for Android.
Starting from Firefox 57, only extensions developed using WebExtensions APIs will be supported on Desktop Firefox and Firefox for Android. Even before Firefox 57, changes coming up in the Firefox platform will break many legacy extensions. (https://developer.mozilla.org/en-US/Add-ons/Installing_extensions)
新版本的 Firefox 对插件做出了更严格的要求,这也影响了 selenium 开发的位于 selenium-server-stanalone.jar 以.xpi 形式运行的 webdriver。Firefox 和 selenium 团队进行商议,做出了新的安排。Firefox 不再搞特殊,它将和 Chrome、IE 等一样,由浏览器开发方提供独立的 webdriver,供 selenium 调用。
所以,当你用 selenium3.x 的版本启动 Firefox5X 时,会出现下面的错误提示。

这个错误消息明确提示需要设置 driver。但值得注意的是这里的 driver 不是 firefox.driver 而是 gecoko.driver,gecoko 指的是什么呢?
现在正确的声明 Firefox webdriver 的方式如下段代码所示。
System.setProperty("webdriver.gecko.driver","/.../geckodriver");
WebDriver driver = new FirefoxDriver();
webDriver.get("http://www.google.com");
照例,我们来看一下源码,与之前分析的 selenium2.53.0 的源码对比,分析一下区别是什么。
private static CommandExecutor toExecutor(FirefoxOptions options) {
DriverService.Builder<?, ?> builder;
if (options.isLegacy()) {
builder = XpiDriverService.builder()
.withBinary(options.getBinary())
.withProfile(options.getProfile());
} else {
builder = new GeckoDriverService.Builder()
.usingFirefoxBinary(options.getBinary());
}
return new DriverCommandExecutor(builder.build());
}
new FirefoxDriver() 调用的代码中生成 executor 时,上面这段判断语句是 selenium 2.53.0 中没有的。我们没有做更多的配置修改,此时 options.legacy 默认为 false,对应了一个 new GeckoDriverService.Builder(),这显然就是我们所说的 selenium 3 新出现的为配合 Firefox 新版本而采用的启动方式。
而与之对应的当 options.legacy 为 true 时,XpiDriverService.builder(),可以推测这应该是老版本 selenium 采用的通过添加 Firefox extension 的方式启动控制 Firefox 的方法。也就是说,目前的 selenium 还是可以不采用 gecko driver 的,只是需要修改 legacy 这个参数。我们在主程序需要写下的代码如下:
System.setProperty("webdriver.firefox.marionette", "false");
WebDriver driver = new FirefoxDriver();
webDriver.get("http://www.google.com");
而程序内部修改设置的代码为
public FirefoxOptions() {
String binary = System.getProperty(FirefoxDriver.SystemProperty.BROWSER_BINARY);
....
String forceMarionette = System.getProperty(FirefoxDriver.SystemProperty.DRIVER_USE_MARIONETTE);
if (forceMarionette != null) {
setLegacy(!Boolean.getBoolean(FirefoxDriver.SystemProperty.DRIVER_USE_MARIONETTE));
}
....
}
当然这种做法并不值得推荐,毕竟 geckodriver 是大势所趋,目前的 xpi 方法应该只是过渡时期的产物,我们当然要审时度势嘛。
可以预见 selenium 3 之后我们将逐渐告别 webdriver.xpi,再看一眼 selenium 启动的浏览器内的插件吧。虽然 Firefox 不再特殊,但一切都是为了更好的 selenium 嘛,是时候对 webdriver.xpi 说再见啦。