经常听说 selenium、WebDriver 了,但他们是什么,用来干什么的呢?今天借此课程查阅一些资料,原来是这样子的。
官方 API:http://www.seleniumhq.org/docs/03_webdriver.jsp#introducing-the-selenium-webdriver-api-by-example;
中文 API:https://wenku.baidu.com/view/6c03a2235acfa1c7aa00ccaf.html。
关于 Webdriver API 的学习以及使用方法:
WebElement 对象提供了多种定位元素策略:可通过 ID、Name、ClassName、TagName、LinkText、Xpath 等定位元素。
经常说 WebDriver、 RemoteWebDriver、AppiumDriver、AndroidDriver,那什么是 Driver ,它是用来做什么的呢?
各个 Driver 之间的继承(区别):http://discuss.appium.io/t/what-is-the-use-or-difference-between-androiddriver-iosdriver-appiumdriver-and-remote-webdriver/8750
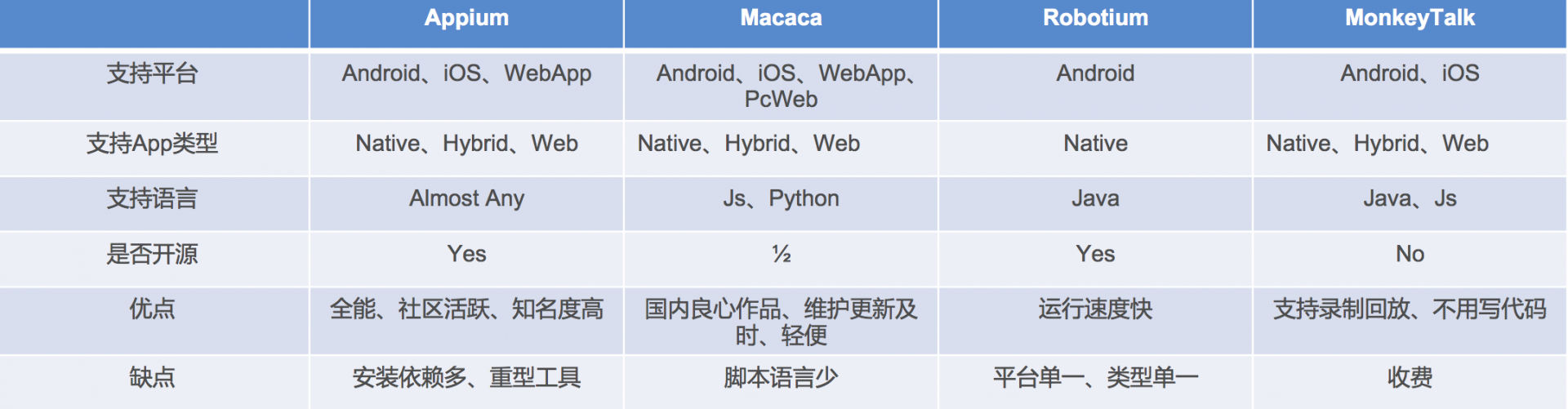
我们知道了 APP UI 自动化的实质,所以现在流行的几个自动化工具做 UI 自动化的实质都一样,都是上面的 3 个步骤。它们的区别是:
下面详细看看 Appium 原理。
自动化驱动框架有
- Android:UIAUTOMATOR 2、UIAUTOMATOR、INSTRUMENTATION;
- iOS:UIAUTOMATAION、XCUITESTING(WebDriverAgent)。 由于上面手机自动化驱动框架是由 Google(或 Apple)官方提供的,是跟 Android SDK 捆绑发布的,所以每次 Android 新的系统(SDK 升级)发布的时候,与 SDK 捆绑的自动化框架也会有升级(要么是对原有框架的优化如 Android 的 UIAUTOMATION 框架, 要么就是推出新的框架如 iOS 废弃 UIAUTOMATION 框架 推出 XCUITESTING)。
我们再回顾各个自动化测试框架之间的区别
那么 Appium 是如何实现的呢?
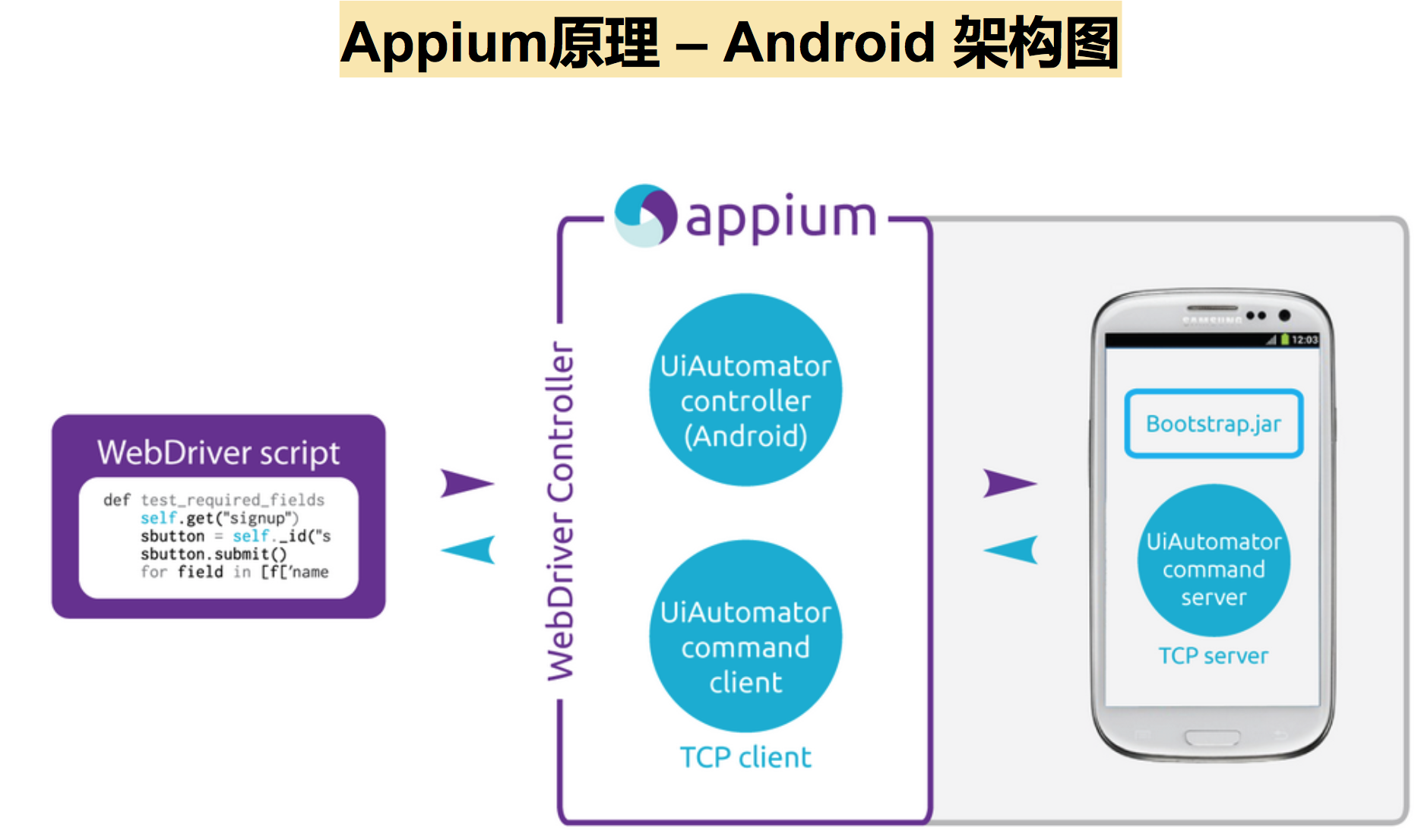
怎么发送指令?谁来把指令告诉手机?
Appium Client 端 脚本执行的时候,Client 端把每一行代码发送到 Appium server 端,Appium server 负责接收脚本发送过来的内容,把脚本发送过来的内容进行翻译,翻译成一个统一的指令。
- 不论你用什么语言编写的脚本都会翻译成统一的命令,所以 appium 支持多语言;
- 为什么能支持多语言呢,是因为 Appium 继承了 selenium/WebDriver 的 client 的类;
- 虽然支持不同的语言,但你只要学习不同语言的 API,只需要看不同语言的脚本文档。
我们知道 Appium 不是一个自动化驱动程序,不去操作手机做自动化,那是谁来操作指令,指令又是怎么传到手机上的呢?
Appium 提供了一个 bootstrap jar 包,Appium 会在运行的时候偷偷注入到手机上,Appium server 跟自己偷偷注入的这个 jar 包进行通信,jar 包拿到指令后,去调用手机的 UIAUTOMATOR 去做执行。
所以 Appium 是一个 server,起调度作用,把指令告诉手机里的 bootstrap.jar;真正执行自动化操作的是 Google 官方提供的自动化工具。
Android 的自动化框架 UIAutomator ,UIAutomator 框架提供了 3 个非常重要的类:
以 Python 为类
首先我们看看 setUp 方法 写了什么?
def setUp(self):
desired_caps = {}
desired_caps['platformName'] = 'Android'
desired_caps['platformVersion'] = '6.0.1'
desired_caps['deviceName'] = 'Android Emulator'
desired_caps['app'] = PATH(
'../../../sample-code/apps/ApiDemos/bin/ApiDemos-debug.apk'
)
self.driver = webdriver.Remote('http://localhost:4723/wd/hub', desired_caps)
setUp 方法先定义了 desired_caps,然后通过传入 desired_caps 实例化一个 self.driver,实例化过程做的事情有:
1.去 desired_caps 指定的手机机型系统删除原来手机里已有的 desired_caps 指定的 APP;
2.再重新安装 desired_caps 指定的 APP。
所以执行第 2 个测试用例时,登录态等会丢失(如果在第 1 个测试用例时登录了)。如果希望第 2 个测试用例不卸载重新安装,可以加一个参数配置:desired_caps['noRest']=true。但是这样又会有一个问题,下次执行第 1 个测试用例也不会卸载重装 APP 了。
desired_caps 设置的参数决定了 driver 启动时到底以什么状态来启动。那 desired_caps 设置的参数有哪些呢?可以在 Appium 的 GitHub 里查看:
输入 https://github.com/appium/appium,点击 docs 目录,点击 cn 目录,点击 writing-running-appium 目录,看到 caps.md 文件。
这里推荐另一个方法:python 装饰器 @classmethod
在 setUp 和 tearDown 方法前写上装饰器@Classmethod,表示该方法针对这个类只执行一次,那么脚本执行顺序就变成了:setUp -> method1 -> method2 -> tearDown。这样第 1 个测试用例执行前就会卸载重新安装,直到这次所有测试用例执行完。这时可以把登录等操作放在 driver 实例化好且测试用例执行之前,如下代码所示:
self.driver = webdriver.Remote('http://localhost:4723/wd/hub', desired_caps) loginAction()
3.self.driver = webdriver.Remote('http://localhost:4723/wd/hub', desired_caps), 这行代码什么时候执行完毕呢?
在手机上 APP 启动且能看到页面,这行代码才算执行完毕,即 self.driver 实例成功,才会执行测试用例。
有哪些 API 可以调用,查看 API 文档
如果不知道 Appium 提供了哪些可以 操作手机的 API ,可以查看 Appium 各个 Client 端 API 文档
输入 https://github.com/appium/python_client,点击 appium 目录,点击 webdriver 目录,看到 webdriver.py 模块。
这里是 Python Client 里面实例化的 self.driver 所能调用的所有的 API(也是 webdriver 的源码)。
知道有哪些 API 了,那怎么定位元素呢?
可借助 UIAutomatorviewer 工具进行元素定位(或者 Appium 的 inspect)。打开 UIAutomatorviewer 工具的方法是: 在命令行输入 uiautomatorviewer 即可启动。
常用来定位元素的信息有:id、text、class、content_desc,他们对应的 API 是:by_id、by_text、by_class_name、by_accessibilityId,如果前三者都不能定位到元素,可以请开发帮忙把元素的 content_desc 信息加上,这样可以用 by_accessibilityId 定位元素。
提高脚本流畅度和稳定的 2 个方法 — 摒弃 time.sleep 线程等待方法
确定页面有某个控件,但是脚本报错说找不到控件,这时候我们一般会在脚本里加 time.sleep 即线程等待。不建议用这种方法,更好的方法是:
- 隐式等待 implicitly_wait() 在 driver 生成的时候,设置隐式等待时间 self.driver.implicitly_wait(10),设置了之后,这个会在全局对所有 find_element_by_xxx 生效,如果某个控件没有马上找到,那么在 10s 以内循环的不停的去找这个控件直到找到,如果 10s 后仍然没有找到控件才会报错。
- Webdriver wait 指定等待,直到某个控件出现才会做 sth。
如何同时对多台设备执行自动化测试?
启多个 Appium server 就可以。
参数配置参考如下文档:输入 https://github.com/appium/appium,点击 docs 目录,点击 cn 目录, server-args 文件。
对 Hybrid 页面进行自动化操作有两种方式: UIAutomator 以及 UIAutomator + ChromeDriver 。
H5 页面是一个 WebView,UIAutomator 不支持操作 WebView 元素,一般情况下只认识 Android View(即 Native 页面)。
UIAutomator 会把 WebView 里所有元素转义成 Android View,但是大部分元素的 id、text 都为空,content_desc 内容 原 text 内容,所以这种情况下不能通过 id、text 信息来定位元素,可以使用 content_desc 信息定位元素。
但是这种方式并不是太通用,因为不同手机机型系统 UIAutomator 将 WebView 里元素转义元素的 content_desc 值不能保持一致的格式,如有的手机将某元素转义后的 content_desc 值为 “登录”,有的手机却是 “u 登录” 等等。
这里 Google 提供了一种更好的方法,即第二种方法。
在 Android 4.4 系统以后 Google 推出了 ChromeDriver,它跟 UIAutomator 是独立平行的,他是可以操作 WebView 的。
如果是 Hybrid 页面, bootstrap.jar 调起 ChromeDriver 完成自动化;如果是 Native 页面, bootstrap.jar 调起 UIAutomator 完成自动化。
所以 Appium 可以通过 bootstrap.jar 同时调起 UIAutomator 和 ChromeDriver 来完成 Hybrid 的自动化(只能针对 API > 4.3,是受 ChromeDriver 的限制)。
基本没什么区别,除了下面这一点。
前面提到:“如果是 Hybrid 页面, bootstrap.jar 调起 ChromeDriver 完成自动化,如果是 Native 页面, bootstrap.jar 调起 UIAutomator 完成自动化。” 那么在脚本里如何实现呢?
通过切换上下文 Context。
具体 API 可以查看 GitHub:https://github.com/appium/python-client/blob/master/appium/webdriver/webdriver.py
真机上 APP 的 WebView 的 debug 属性要打开。
一般 debug 包默认是打开的,如果没有打开找开发协助,模拟器没有这个限制。
Chrome 浏览器输入:chrome://inspect,点击页面上的 inspect 按钮
需要访问 Google 源,所以需要 ***!用右上角的定位工具(类似 chrome 网页定位元素)定位到元素,在右侧默认选择这块代码,右键选择:复制 - 复制 xpath。
不能 *** 又想精准定位元素的 xpath
print(self.driver.page_source)
如果你没有可能在 chrome 上打不开上述页面,也可以采用下面的方法:输出 h5 页面的 page_source,保存 html 文件,用 chrome 浏览器打开,右键选择 “ 检查 ”,再按照步骤 2 也可以获得元素的 xpath。最好能用步骤 2。
Native 与 WebView 之间的衔接
一定要记得当前在哪个 Context 下。
WebView Context 请不要乱用手势操作
由于在 WebView Context 下,自动化驱动框架是 ChromeDriver,而 flick、swipe(移动手机特有的操作)是 UIAutomator 框架支持的。 所以只能用 ChromeDriver 针对 web 端支持的手势 API 如 scroll 操作。
不要忘记 WindowHandle 的存在
列表页有 2 个商户,假设商户详情页都是 WebView 页面,进入第 1 个商户详情页是一个 WebView,进入第 2 个商户详情页可能不是一个同一个 WebView,可能新起了一个 WebView。这个其实很正常,和 Chrome 浏览器类似,可以是在当前 tab 打开第 2 个商户页,也可能是新起一个 tab 打开商户页。
如果明明切换了 Context 但是还是不能定位当前页面元素,有可能 Context 切换了,但是 WindowHandle 还留在上一个 WebView 页面,需要对 WindowHandle 做一个切换。
