:
我从 2016 年开始入行 AI 产品测试,到现在也有 9 个年头了。但其实也是最近 1,2 年才开始把 AI 用在自己的工作中。 其他时间大多都是研究怎么去测试 AI。
作为一名 AI 产品的测试工程师,我最近这半年开发的工具代码和自动化测试代码,95% 以上都是由 AI 生成的。
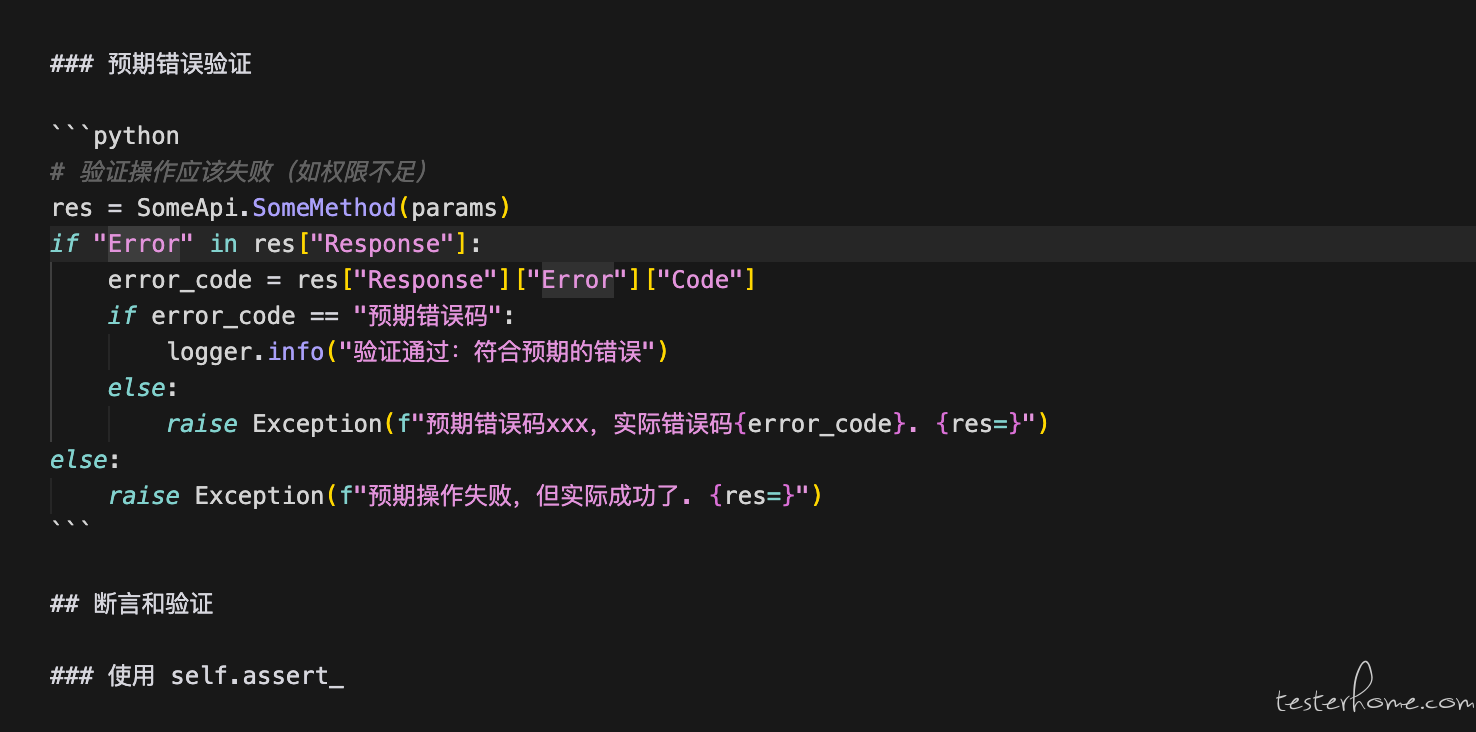
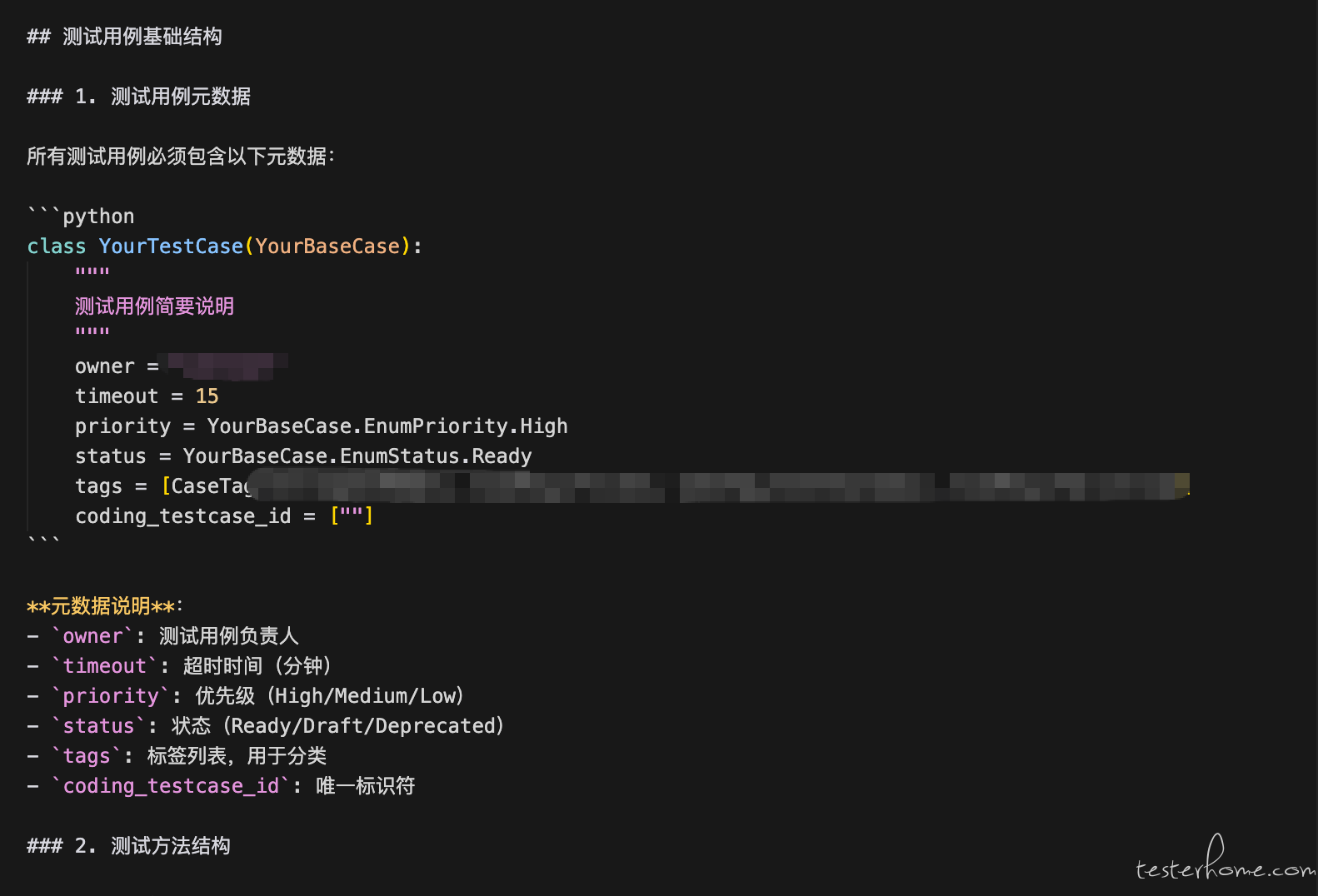
从最初对 AI 代码生成能力的怀疑,到现在的深度依赖,我也总结了一些心得。但我知道,其实很多小伙伴去尝试用 AI 生成用例的时候,都会吐槽 AI 像个智障一样。那是因为大家都用错了工具,想用扣子的智能体产品或者豆包这样的大模型产品都是不行的。因为它们解决不了知识库和上下文工程这两大难题。 即便你的模型再好,提示词再好都是无用的。 所以这也是为什么我们都推荐用 curosr,codex 或者 claude 这样的付费产品,当然很多同学一听付费就不想用了,或者有些同学要做自动生成用例是为了 KPI,是因为老板下了任务。直接用这些难以完成自己的 KPI。我今天都不说这些吧,只单独说怎么样才能生成质量高的测试用例和代码。
很多人可能会问:AI 真的能生成符合项目要求的测试代码吗?答案是肯定的,但前提是你需要掌握正确的方法。经过长期实践,我发现要想让 AI 生成高质量的代码,有几个关键点必须做到位。
AI 生成代码的核心在于"理解"——理解你的项目结构、编码风格、业务逻辑、测试规范等。如果 AI 对这些一无所知,它只能生成通用的、脱离项目实际的代码。
解决方案:建立项目知识库,实时将代码 Embedding 到知识库中
定期(建议每天或每次重要更新后)将项目代码同步到知识库,确保 AI 始终基于最新的代码上下文生成代码。
PS:cursor 这样的产品可以自动更新知识库。只要你写代码了,就会自动上传到服务器并进行 embedding
每个 AI 模型都有上下文限制。以 Cursor 为例,即使是最强大的模型,上下文上限也就在 200K token 左右。当对话内容超过这个限制时,早期的上下文就会丢失,AI 会"忘记"你之前的需求、代码逻辑、设计决策等重要信息。
Cursor 的.cursorrules文件是一个强大的上下文管理工具。你可以把它理解为"系统提示词"——文件中的内容会被自动加入到每次对话的 system prompt 中。
建议做法:
比如我的一个规则文件的一部分:
:
代码摘要:将复杂的代码逻辑通过大模型的摘要功能,总结成文档。这样既保留了关键信息,又大大减少了 token 消耗。
对话摘要:Cursor 支持在对话中将之前的上下文总结摘要。当对话内容过长时,及时使用这个功能,保留核心信息,丢弃冗余内容。
策略调整:根据实际效果,不断调整摘要策略。哪些信息需要保留,哪些可以丢弃,这需要在实际使用中不断优化。
虽然 AI 很强大,但它需要"参考"来理解你的具体需求。最有效的方式是:你先写一部分代码作为模板,让 AI 学习你的编码风格、注释规范、测试模式等。
代码注释是 AI 理解代码逻辑的重要途径。Cursor 的 Tab 功能(自动生成注释)非常强大,可以帮助你快速生成高质量的注释。
注释要点:
模板代码应该是一个完整的、可运行的示例,而不是片段。这样 AI 能够理解:
很多人对 AI 代码生成有一个误解:以为说一两句话,AI 就能生成完美的代码。这是不现实的。
我写一个测试用例时,中文描述经常写几百字,包括:
示例:
测试用例:验证Agent应用在添加Calculator插件后,能够正确进行数学计算。
前置条件:
- 创建一个Agent模式的应用
- 应用已配置Calculator插件
- 插件配置了结构化输出参数:Code(整数)、Msg(字符串)、Data(对象)
测试步骤:
1. 在评测端输入问题:"使用Calculator计算100*100"
2. 验证Calculator插件被正确调用
3. 验证返回结果包含10000
4. 验证返回结果为结构化格式,包含Code、Msg、Data字段
5. 发布应用到用户端
6. 在用户端输入相同问题,验证功能一致
边界情况:
- 输入无效的数学表达式
- 输入超大的数字
- 插件配置错误的情况
验证点:
- 插件调用次数为1
- 返回结果格式正确
- 计算结果准确
经过大量实践和对比,我最推荐的是 Cursor、Codex、Claude 这类产品。目前我主要使用 Cursor,但如果大家完要完成自己的 KPI,不能直接用这样的付费产品。那么我建议小伙伴们,好好想想实时构建知识库和上下文工程的问题,解决不了这两样,你们的 AI 生成代码一定是智障的
我最近在星球内更新各种智能体测试实践, 感兴趣的朋友可以加入。