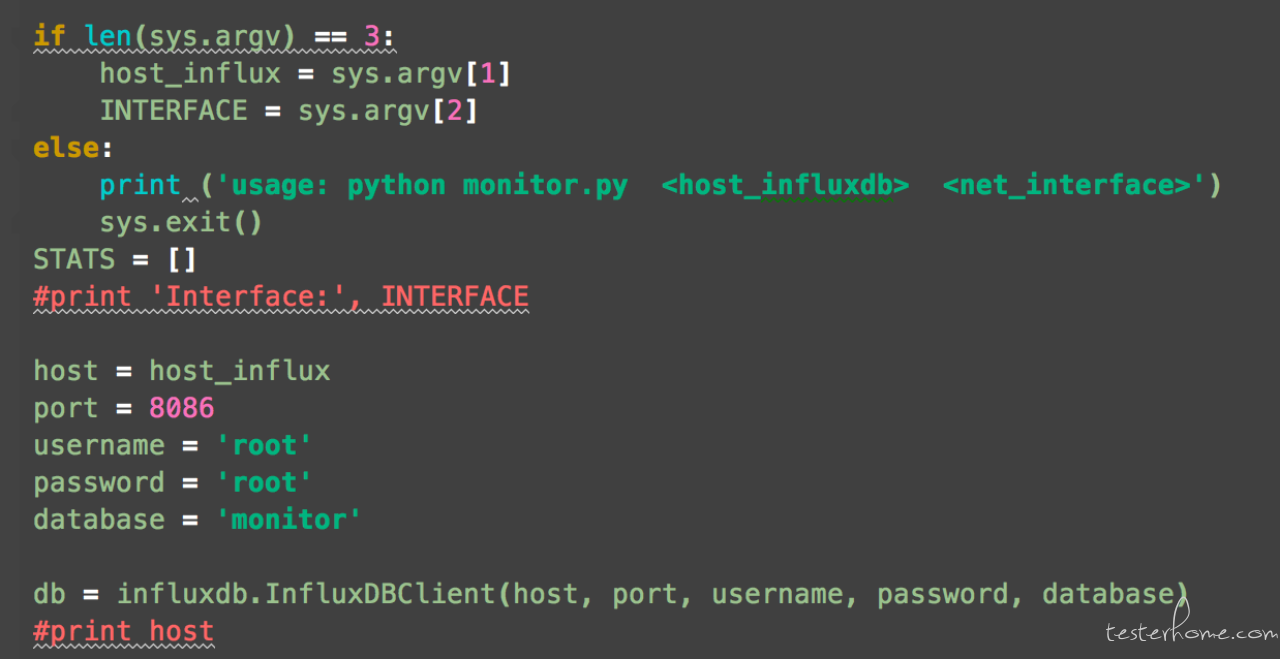
众所周知,InfluxDB 是一个开源的时序数据库,使用 GO 语言开发,特别适合用于处理和分析资源监控数据这种时序相关数据。而 InfluxDB 自带的各种特殊函数如求标准差,随机取样数据,统计数据变化比等,使数据统计和实时分析变得十分方便。
所以它有三大特性:
1、时序性(Time Series):与时间相关的函数的灵活使用(诸如最大、最小、求和等);
2、度量(Metrics):对实时大量数据进行计算;
3、事件(Event):支持任意的事件数据,换句话说,任意事件的数据我们都可以做操作。
Influxdb 由于其独特性,所以 influxdb 里面有一些独有的重要概念,不同于一般的关系型数据库,例如: timestamp,field key, field value, field set,tag key,tag value,tag set,measurement, points,retention policy。
timestamp:每条数据记录的时间(utc 时间戳),也是数据库自动生成的主索引;
measurement:类似于数据库中的表;
fields:各种记录的值,由 field key 和 field value 组成,在 influxdb 中,字段必须存在;
tags:各种有索引的属性,可选的,但是强烈建议你用上它,因为 tag 是有索引的,tags 相当于 SQL 中的有索引的列。
points:表里面的一行数据。
retention policy:指数据保留策略。
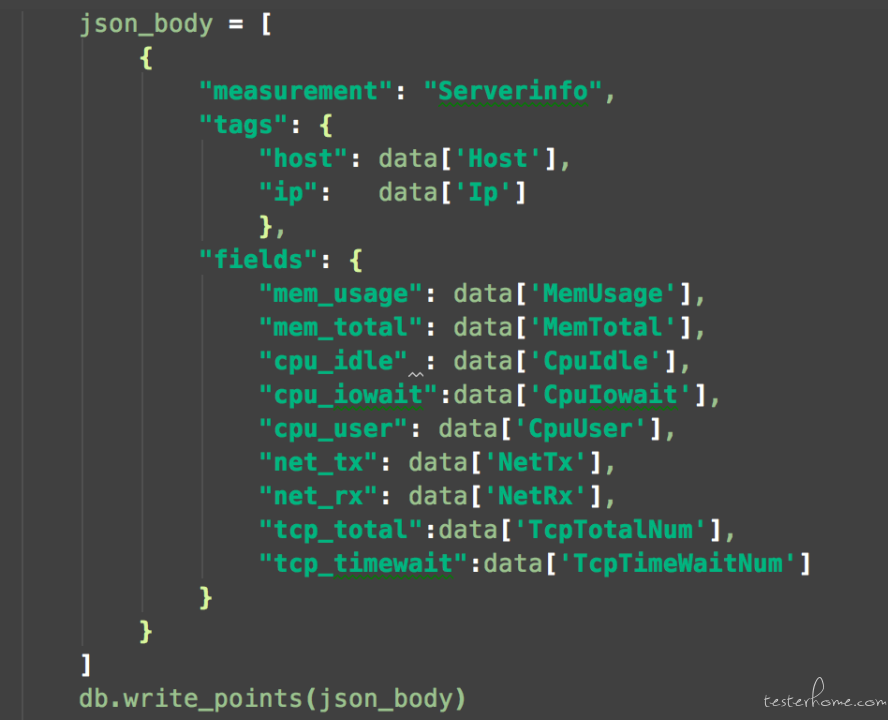
Python 中有现成的 infludb 库,安装好后,即可调用对应的接口。如下 influxdb. InfluxDBClient(host, port, username, password, database)。另外我构造了 json 字符格式,里面存储的事服务器监控的一些指标,如 cpu/内存/网络/连接数等,根据自己的需要。而这些具体数值的获取,你可以通过很多方法。最后通过调用 write_points 接口即可写入到 influxdb 中。
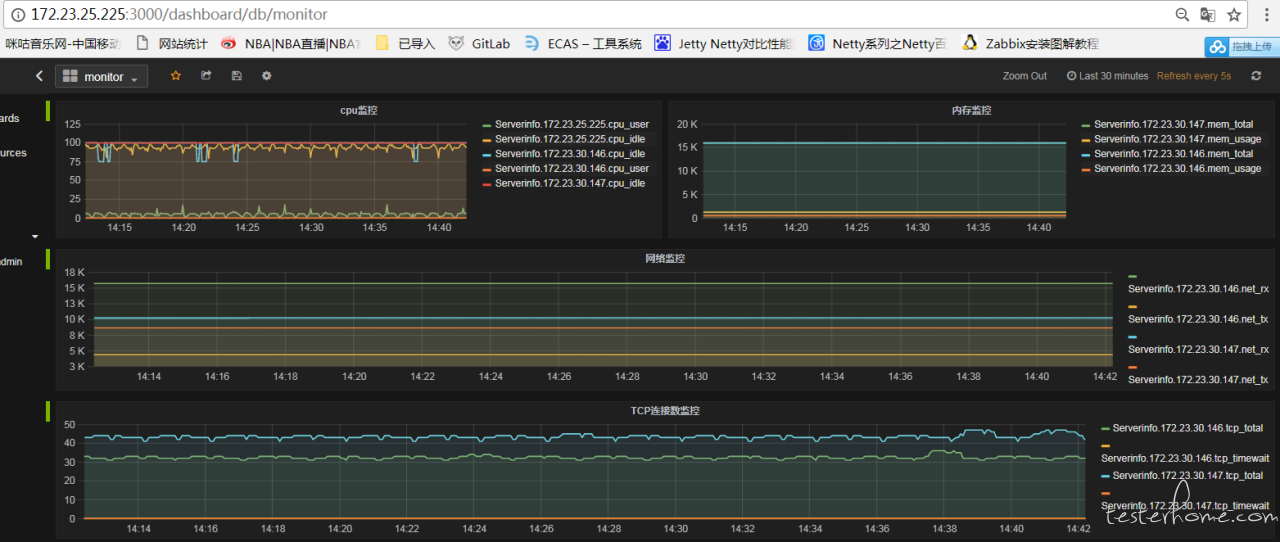
你可以通过 grafana 开源可视化工具,把数据直观的图表化,如下,这个就可以根据自己定制化监控的需求了。
以上个人学习《测试工程师 Python 开发实战》书籍后实践应用的内容,希望能带给你一点启发和帮助。
