图片检索在生活中应用广泛,常见的图片检索包括基于文本内容搜索和基于图片内容搜索。基于文本内容搜索图片是通过给图片打标签,然后通过搜索标签来实现对图片的搜索;而基于图片内容搜索即以图搜图,用户通过输入图片在海量的图片库中快速找到同款或者相似图片,这种搜索方式被广泛应用于电商、设计、媒体咨询、智能监控以及搜索引擎等热门领域。
本文基于 Milvus 和图片特征提取模型 VGG,借助 SQL 快速搭建了一套以图搜图端到端解决方案,为本地化进行海量图片相似度量实施工作提供可能。
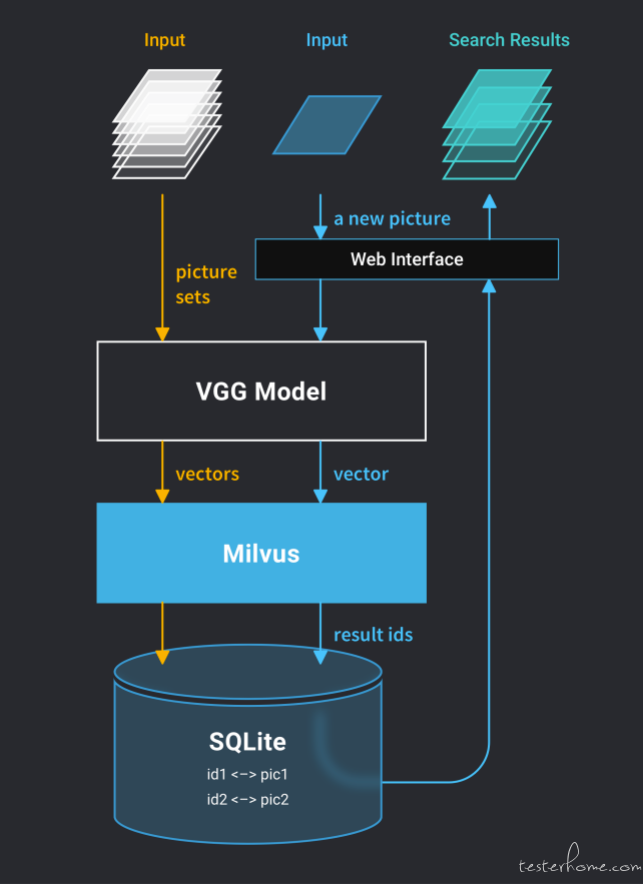
图为基于 Milvus 的以图搜图系统架构,webclient 通过一组 web interface 接收用户请求并发送给 webserver,webserver 接到 webclient 发来的 http 请求后进行处理并返回处理结果。webserver 由图片特征提取模型 VGG 和向量搜索引擎 Milvus 组成,VGG 模型负责将图片转换成向量,Milvus 负责存储向量并进行相似向量检索。
SQLite 负责存储原始图片数据,Milvus 存储向量后生成的唯一向量 id 与原始图片数据建立关联关系,在图像检索时通过向量 id 找到对应的原始图片信息。
VGG 于 2014 年由牛津大学视觉几何组 (Visual Geometry Group) 提出,其突出贡献是证明了增加网络的深度能够在一定程度上影响网络最终的性能。VGG 模型在多个迁移学习任务中的表现要优于 GoogLeNet,从图像中提取 CNN 特征,VGG 模型是首选算法。
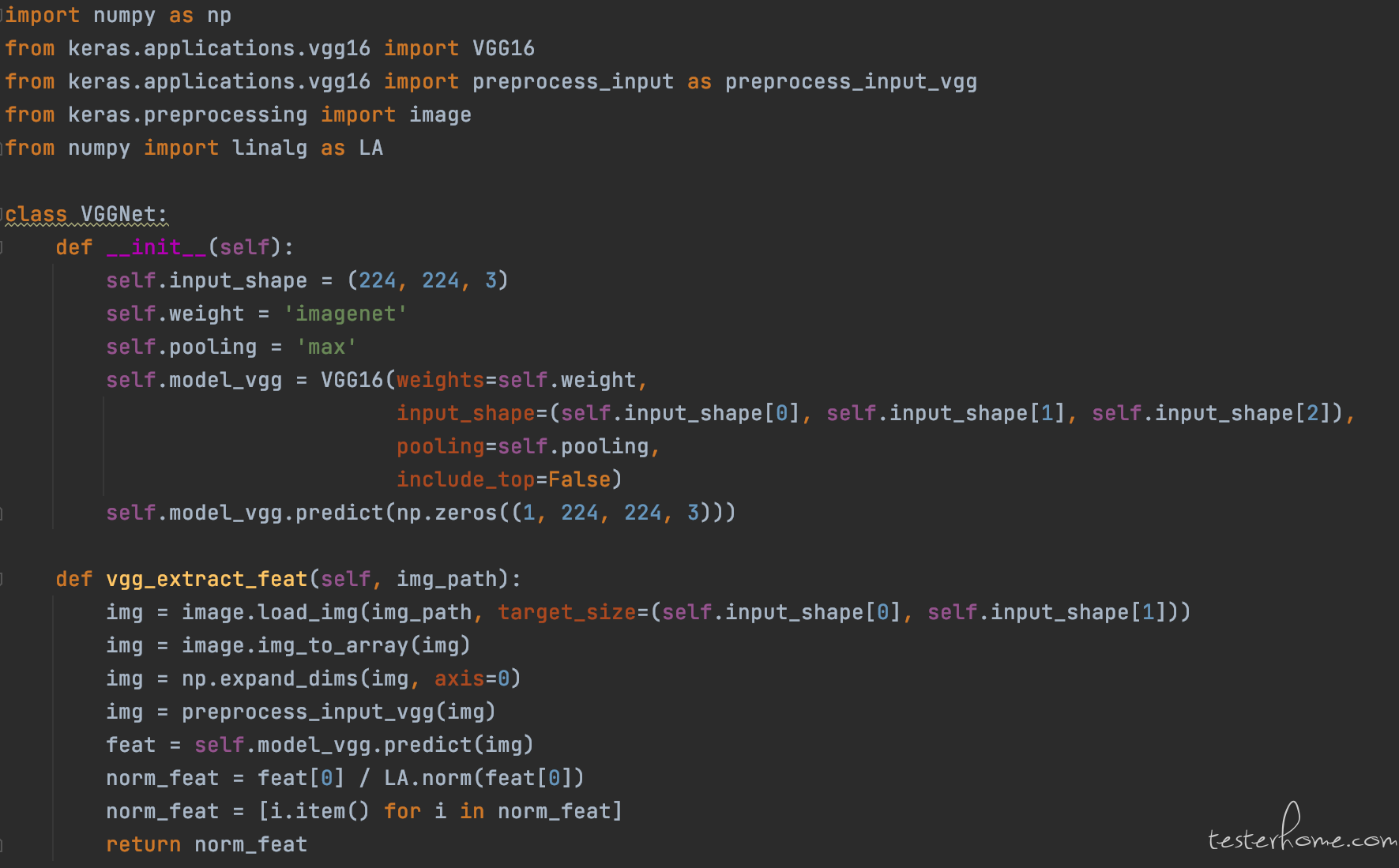
VGGNet 探索了 CNN 的深度及其性能之间的关系,通过反复堆叠 3*3 的小型卷积核和 2*2 的最大池化层,VGGNet 成功地构筑了 16-19 层深的 CNN。本文使用 VGG16 模型 ,技术实现上使用 Keras+TensorFlow:
Milvus 是一款开源的向量数据库,赋能 AI 应用和向量相似度搜索。Milvus 为海量向量搜索场景而设计,它不但集成了业界成熟的向量搜索技术如 Faiss 和 SPTAG,Milvus 也实现了高效的 NSG 图索引。同时,Milvus 团队针对 Faiss IVF 索引进行了深度优化,实现了 CPU 与多 GPU 的融合计算,并完成单机环境下 SIFT1b 十亿级向量搜索任务。具有使用方便、实用可靠、易于扩展、稳定高效和搜索迅速等特点。
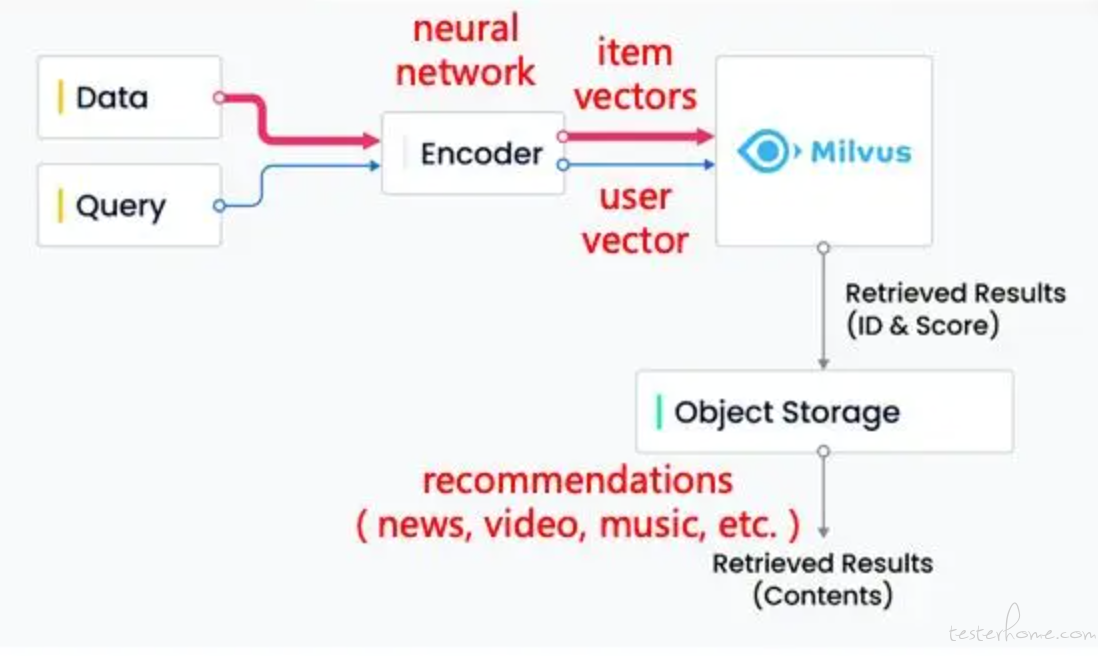
图是 Milvus 在整个系统链路中的位置及应用场景。数据进入系统大致分为两类:一类是需要比对的数据,另一类是需要真正去做查询的数据。这些数据通过 Encoder(如神经网络或深度学习模型)生成 vector 向量,然后这个向量就会写入或通过 Milvus 去做查询。所有的写入过程在 Milvus 中都会转化成文件,存储在对象存储上面;而在查询过程中基本是纯内存操作,利用内存索引去找到距离比较近的向量,再对这些向量去做读盘的 retrived 操作,获取原始数据。
在整个以图搜图系统中,webserver 对外提供 5 个 api 调用: train、process、count、search、delete,基本包含了系统的全部基础功能。
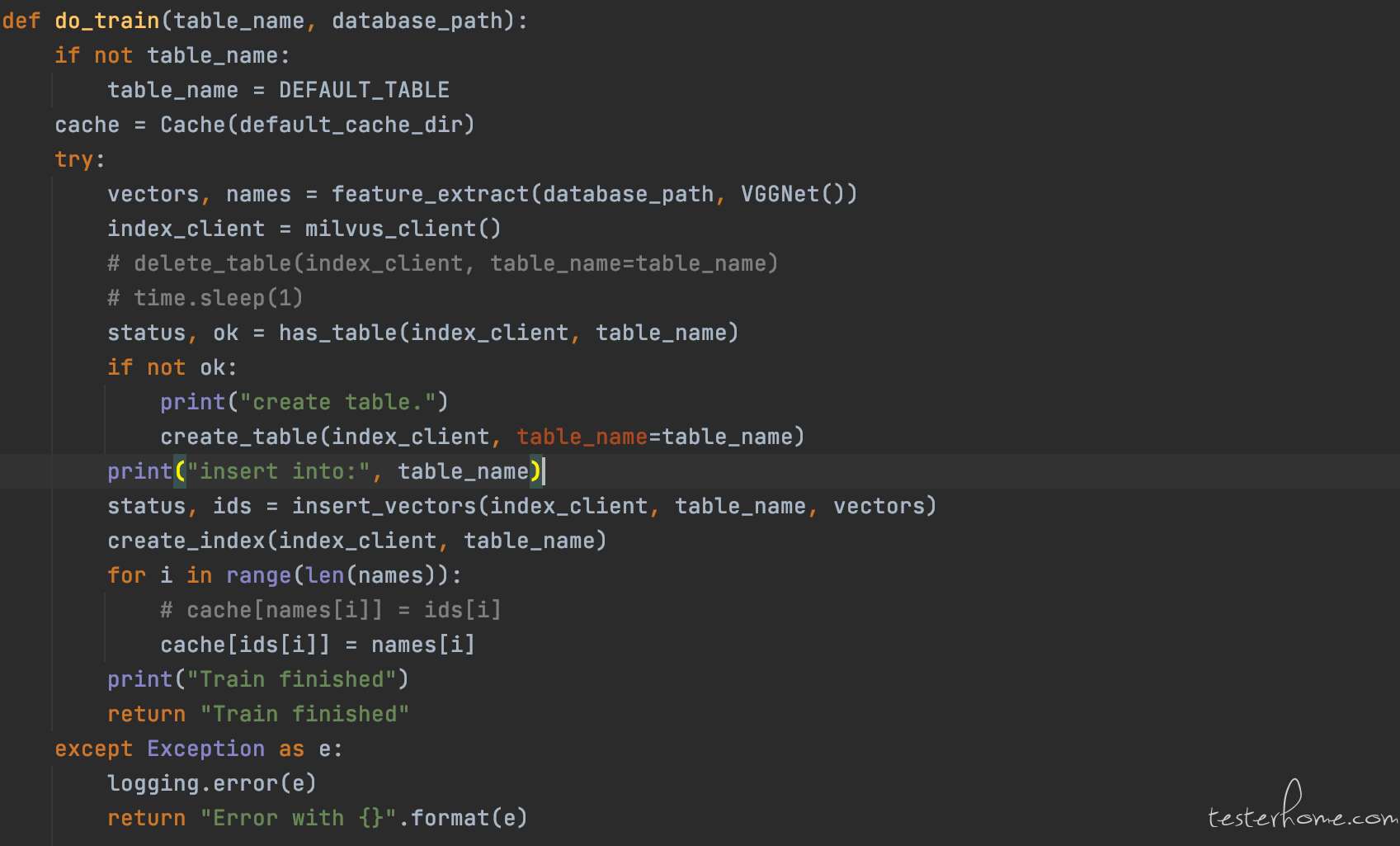
train api
train api 为图片加载接口,通过 post 请求接收图片的路径并传入系统。在预处理阶段,即图片检索之前,需要将图片库加载进数据库 Milvus,由于 Milvus 仅支持向量数据的检索,需要将图片转化为特征向量,先通过 train api 加载图片库路径,再通过调用 VGG 模型的 vgg_extract_feat() 实现特征提取,获取特征向量;然后通过 insert_vectors() 的接口导入 Milvus 数据库。特征向量存入 Milvus 数据库后,Milvus 会为每个向量分配一个唯一 id,并将此 id 反射存储到源数据库 SQL 中,与源图片建立关联关系。在后续图片检索时,通过特征向量 id 查找对应图片的特征向量。
process api
process api 为 get 请求,提供查看图片加载的进度。调用可以看到 train api 运行过程中已经加载进 Milvus 库的图片数及总图片数。
count api
count api 为 post 请求,提供查看当前 Milvus 库的向量总条数,一条向量即表示一张图片。
search api
search api 为 post 请求,在图片相似检索时调用。待搜索图片传入系统后,先通过 VGG 模型的 vgg_extract_feat(img_path) 转化为特征向量,然后调用 search_vectors() 在 Milvus 库中进行向量相似检索,返回 top_k 结果。
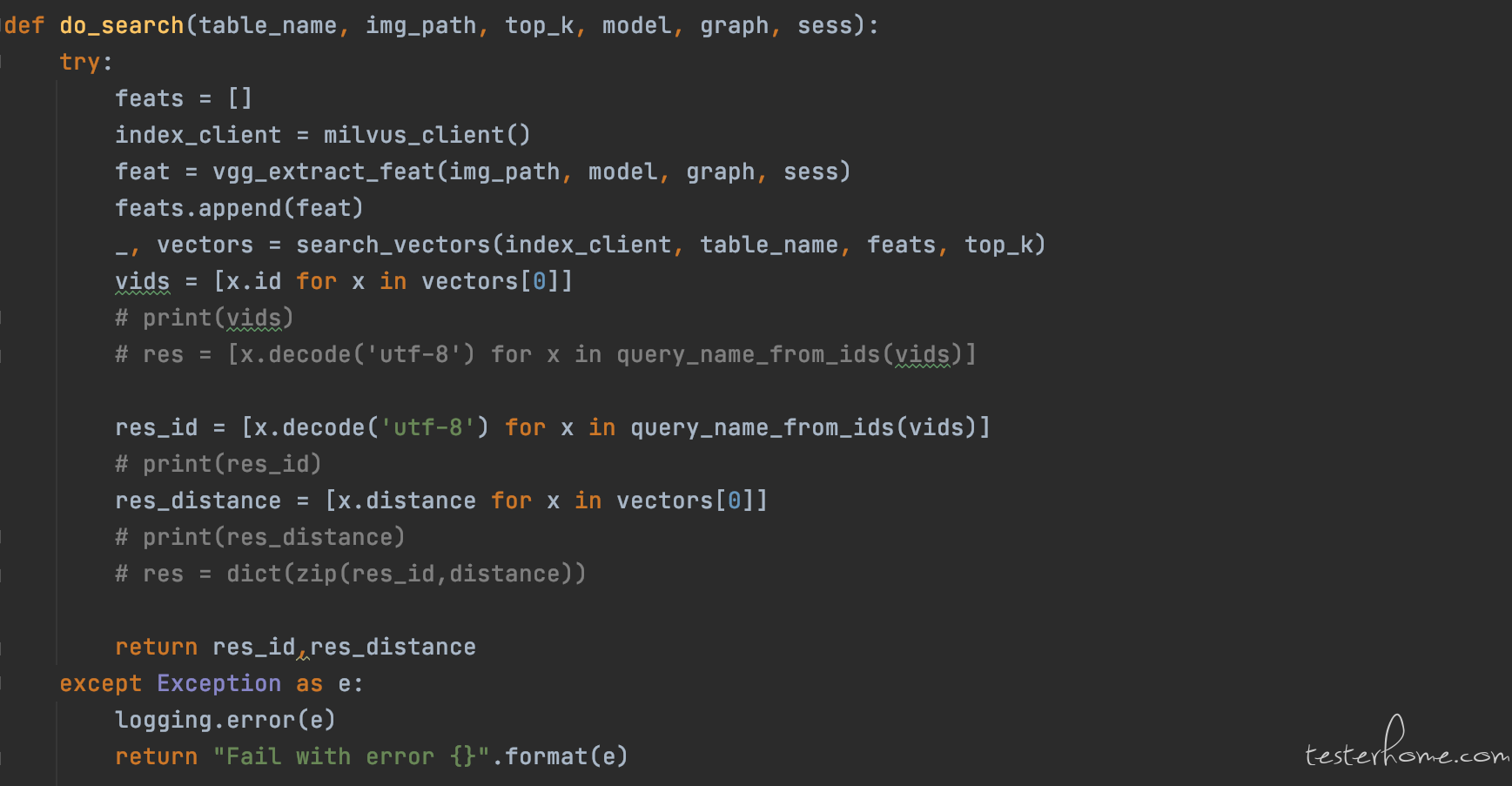
通过 search 接口拿到前 top k 相似结果的向量 ids,通过与 SQL 库中保存的向量 id 进行比对获取与源图片的对应关系。

delete api
delete api 为 post 请求,用于删除 Milvus 库里面的表,清空之前导入的向量数据。
基于 Milvus 搭建的以图搜图系统,通过容器化服务进行部署,主要包含 Milvus docker 部署、webserver docker 部署和 webclient docker 部署三部分 (详情可参见附录)。部署完成后,浏览器输入 ip:port(如 localhost:8001) 即可访问。
下图是抽取 PASCAL VOC 图片集部分图片(约 10000 张图片,涵盖人物、动物、交通等 20 多个目录)为例的以图搜图系统界面,输入查询图片 “飞机” 得到的搜索结果,通过调整 top_k 参数,右侧结果栏即可更直观的展示相似结果信息。

本文介绍了基于 Milvus 搭建以图搜图系统过程,能让测试人员不必掌握 tensorflow, pytorch 等深度学习框架,及 opencv 之类的视觉算法库即可快速感知图片的相似情况并给出更直观的判断,从而降低测试门槛。另外,基于云 AI 而生的 Milvus 特征向量库,也为后续基于 kubernete 的部署提供了可能。
附录:
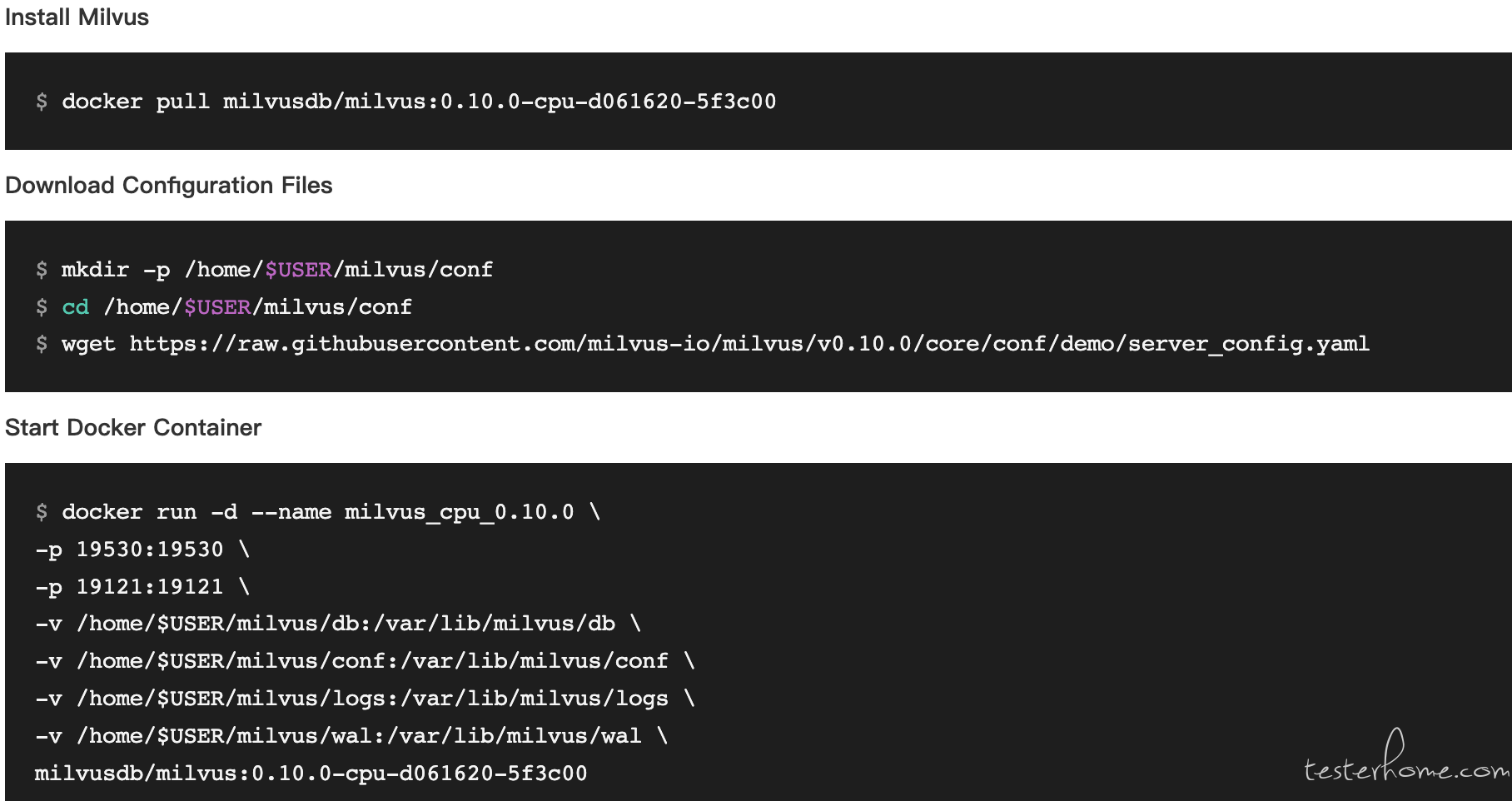
启动 Milvus Docker
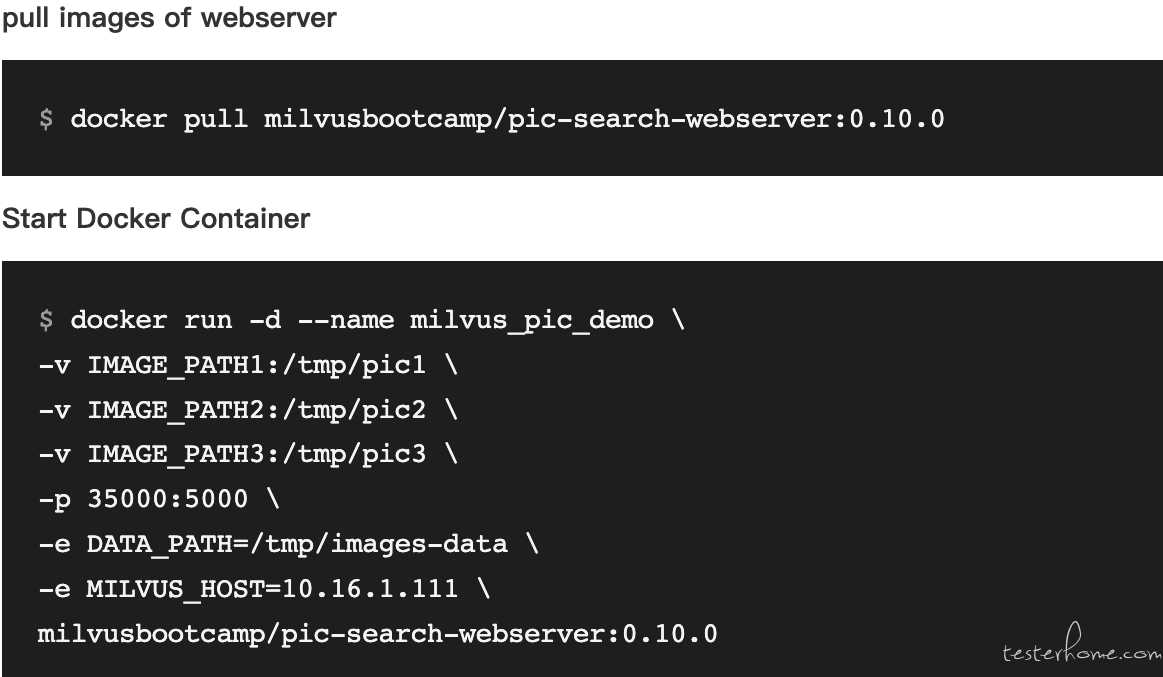
启动 Server Docker
启动 Client Docker