在混沌工程理论知识记录 -- CAP中我记录了在高可用设计中非常重要的 CAP 和 BASE 理念。基本上所有的分布式系统在高可用上都逃不开这两种理念的指导,在测试过程中我们也使用它们作为指导进行场景设计。而在 CAP 和 BASE 中最重要的一点就是数据一致性。各个分布式系统为了达到强一致性或者最终一致性都下了很大的苦工。这里我总结一下常用的方式和对应的测试手段。
在当代分布式系统中是很少会存在单点的服务。也就是说为了提高系统的性能和可用性,会将同样的服务部署多个来一起抗住业务压力。而同样的为了保证数据的性能和可用性,系统也会选择把数据存放在多台机器中。在众多数据分布式存储的设计中,也会按存储方式分为两类:数据集中式和数据分散式
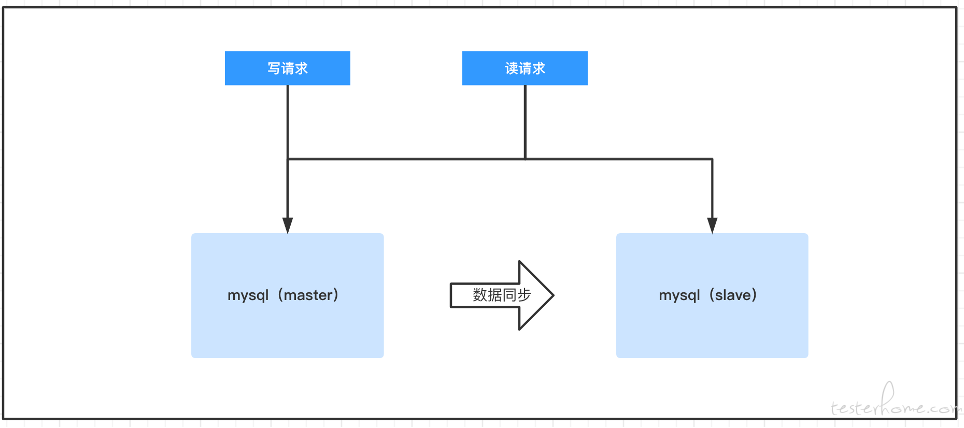
集中式架构指的是虽然数据是存放在多个节点上进行保存的,但每台机器中仍然保存的是全量的数据。我们熟知的 mysql 使用的就是这种架构,mysql 的主备/主从/多主的部署方案中都是在每台 mysql 节点中都保存了全量的数据的。所以 msyql 才能完成著名的读写分离架构。
在读写分离架构中,用户所有的写请求全部发送到 master 节点中,这是为了保证数据的一致性,因为如果写请求可以随意的请求各个节点,那么数据就会出现混乱。而在主节点保存的数据会有机制同步给从节点以保证节点之间数据的一致性。从而用户的读请求就可以请求任意节点。 当 master 节点故障后,salve 节点也可以被选举成为新的 master 节点以支持业务的运行。这种读写分离的架构拥有良好的性能与一定程度的高可用能力。是非常多的数据库产品的选择方案。
与集中式架构不同的是,分散式架构不会把所有的数据都保存在同一个节点上。它会根据一定的算法计算出一份数据应该保存在哪台节点上,这种架构会尽量的让数据均匀的分散在集群中的各个节点中。目前大量的分布式存储系统使用的就是此种设计。其中最具代表性的就是 HDFS。
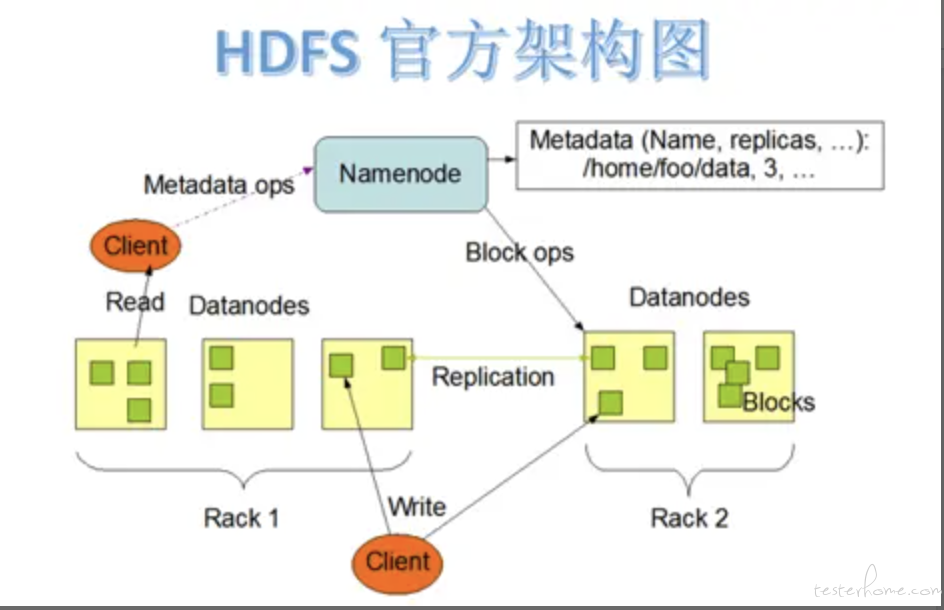
在 HDFS 集群中存在一个 Name Node 节点与多个 Data Node 节点。Name Node 负责存储数据的元信息,客户端所有的读写请求都要先到 Name Node 中进行查询,这样客户端才能知道请求的数据保存在哪里(因为数据是分散在多个节点中的)。这样会导致 Name Node 挂掉后,整个集群都会不可用。所以一般都会有至少再部署一台 standby 的 Name Node 节点,当处于 ready 状态的节点挂掉后,standby 节点就会代替成为新的 Name Node。
虽然数据分散式架构是把数据分散在集群中的每台节点上的,但这并不代表它不会像 mysql 那样把数据同步给其他机器。因为数据仍然是要保证安全的,如果不把数据进行备份的话,那么随便一台机器下线都会导致数据丢失。所以一般这种架构的产品都会选择一份数据在多台机器中进行备份。比如在 HDFS 中,默认会将一份数据保存 3 份(有参数控制)。其中一份数据为 leader,用户的读写请求都是访问这个数据。其他两份数据一般会保存在与 leader 不同的节点中(尽量是 3 份数据保存在 3 台节点中),一旦 leader 数据挂掉,Name Node 会选择一个备份的数据成为 leader 继续为用户提供服务。
可以看出不管是哪种存储架构,在集群中一定都会存在一个 master 节点。而一旦 master 节点挂掉,会需要一定的时间才能让 slave 节点被选举成为新的 master 节点。也就是会有一定的不可用时间。而另外一个问题是数据分布式存储势必会带来数据同步的问题,而数据同步问题则带来数据一致性问题。
总的来说数据同步设计一般分为三种:异步复制,半同步复制和全同步复制。
异步复制简单来说就是用户的写请求发送到 master 节点,在 master 把数据保存后就直接返回了,并不会等待数据同步到从节点上,整个数据同步是异步执行的。这种设计的优缺点都特别的明显。优点是性能最大化(不会等待数据同步到从节点)。缺点是存在很大的数据不一致问题。即便我们假设在生产环境中没有任何故障发生。这种异步的数据同步方式也会存在至少几十毫秒的延迟才会把数据同步到从节点。如果网络状况或者从节点性能状况不是很好的话,这个延迟会更大。所以用户读取数据时可能读取的是旧的数据。而当主节点和从节点之间发生了网络故障时,更是会导致数据同步完全失败。如果在主节点与从节点之间的数据存在较大不一致的情况下,master 节点的磁盘再放生损坏(没有做 raid),那就会导致数据的彻底丢失。如果做了 raid 或者磁盘没有损坏,只是主节点 Down 机。那么在从节点被选举为主节点后,也会因为与原主节点中的数据不一致,导致数据仍然是缺少的(只不过可以从原主节点中找到数据并恢复)。
异步复制的方案是为了性能放弃了数据的一致性。所以如果选取这个方案的业务一定要确定是对数据一致性不敏感的。并且虽然默认数据会发生不一致,但我们也不应该摆烂躺平,一旦因为发生故障主从切换导致数据不一致了,我们也应该有手段人工的把数据进行恢复。所以在测试的过程中,我们一般会设计这样的场景:
模拟出这种场景的故障后,让相关人员按手册进行操作,看看是否能在规定时间内把数据恢复回来。当然异步复制也会有一些设计是为了保护数据一致性的。在 redis 中,也存在主从同步读写分离的部署方案,而它有两个参数分别是 min-replicas-to-write 和 min-replicas-max-lag。第一个参数表示连接到 master 的最少 slave 数量,第二个参数表示 slave 连接到 master 的最大延迟时间。所以如果 min-replicas-to-write 设置为 3,min-replicas-max-lag 设置为 10。这就要求至少 3 个 slave 节点与 master 的网络是畅通的,且数据复制和同步的延迟不能超过 10 秒,否则的话 master 就会拒绝写请求来维护数据一致性。 这种设计可以极大的减少数据不一致的情况,降低对用户的损失。
全同步复制比较好理解,master 节点会在数据同步到所有的 slave 节点之后(数据在从节点也提交完事务)才会返回给用户。只要有一个从节点同步失败,都会导致数据写入失败。这是一种完全的 CP 方案,放弃了可用性,也放弃了性能,毕竟需要等待所有从节点提交完事务,这样的性能是很差的。所以在 mysql 中几乎很少有场景会采取这种方案。如果要测试这个方案本身也很简单。随便在 master 和 slave 之间注入网络分区故障后,要是用户的写请求成功了,那就说明当前不是按这个方案实现的。
全同步复制由于其不保证可用性并且性能太差,很少有人会用。所以 msyql 又退出了半同步复制,半同步复制的特点是:
半同步复制是一种在性能和一致性中取的折中方案,这种方案算是目前最流行的解决方案了。这种折中方案能很大程度的解决主从数据不一致的问题,即便 master 及诶单 Down 机也不会丢失数据,因为 slave 节点的 log 中已经记录了相关数据,只需要少量的时间就可以从日志中将数据提交。但由于不是等待数据完全提交后才返回,所以数据同步还是会存在一定的延迟。所以它仍然不是一个强一致性的解决方案。在读写分离的设计下,用户仍然可能会在一个极短的时间内读取到旧的数据。这在大部分情况下其实也没什么问题,就像在微博里明星发个动态一样,它的粉丝晚那么一会才看到偶像的动态其实一点问题没有。但对于另外一些数据来说,即便是毫秒级别的延迟都是不被准许的,比如商品的库存和用户的余额。所以对于这种数据,就不能搞读写分离了。而是强制所有请求都发送给 master 节点查询。这时候测试人员要测试的就是研发同学确实是把这部分的请求发送给了 master 节点查询了。 可以使用如下的测试方法:
一般来说数据同步方案大体上就是上述 3 种选择,测试人员需要根据不同的选择来设计特定的测试场景。而数据分散式架构中,数据同步往往会更加的复杂。比如在 HDFS 中,有一个参数是设置一份数据保存几个副本(默认是 3),这是为了保证数据安全的。 但是仍然有一个参数是 dfs.namenode.replication.min(默认为 1),代表着只要有多少个数据保存成功后就可以直接返回给客户端成功的消息了。这样不必等待所有数据都保存成功才返回,剩下的数据异步同步即可,提升了质量。当然系统默认的 1 这个值就不是很安全的,很多系统里都会选择把这个值设置为 2 来避免数据丢失的情况。不仅仅是 HDFS,向是 ceph 这种分布式存储的设计也是类似的,它也有个参数是 min size,代表一份数据最少保存了几份之后就可以返回成功消息给客户端了。同时它们的数据同步也不是简单的把一份数据全部保存完成后才开始同步给其他节点的,他们存储的都是大数据,肯定不能这么搞。他们会按各自的设计把数据进行切分,切分成非常小的块之后再针对这些块进行保存,然后异步的同步。最后客户端只要等待 min size 个数据都保存成功后就返回成功。当然这些分布式存储系统的写流程肯定没有我说的这么简单,我只是简化了一下进行描述而已。
每次做混沌工程,感觉最难的就是测试数据一致性,稍微一不注意就漏测一个场景。我做面试官的时候其实很喜欢问这种问题,因为我一直认为故障注入工具很简单,开源的有那么多,没几个人是从 0 到 1 的自研故障注入工具的,连能针对 chaos-mesh 或者 chaos-blade 二次开发的我几乎都没怎么见过。所以我就感觉考察故障注入工具没什么必要。反而是考察这些高可用的这些原理和测试场景的设计挺能看出来一个人的水平的。
