好久没写文章了, 自从换工作以后整天就忙着熟悉新公司的项目了。 趁着这两天有时间我就继续更新一下大数据测试系列。 上一次我们聊过流计算场景一般的测试方法,而流计算是在线业务。 那今天我们聊聊离线业务的场景。 不知道大家有没有接触过大数据平台产品, 这类产品以 TO B 公司居多, 当然也有一些大厂内部也会有大数据平台去支撑业务线, 比如阿里的好像叫 odps 吧(有点忘了), 腾讯也有 tbds 这样的大数据产品。 或者一些 AI 平台也有着大数据平台的特性。 它们的特点是产品属于平台类的, 没有自己的业务, 或者说他的业务就是提供算力去支撑客户的业务。 也就是大数据平台类的产品提供的是一些原始算力, 用户需要调用这些算力来满足他们的业务。 这就跟互联网不太一样了, 接触过大数据的同学比较熟悉的应该还是在业务层的数据处理逻辑, 比如测试一些研发提供的 ETL 程序, 或者数据组的同学提交的一些 hive sql。 这些都是带着强烈的业务属性的,属于业务层的东西。 而大数据平台的产品并没有这些属性, 可以理解为它属于中台层。
上面说的过于抽象,我们用个例子来说明一下。 一般企业在发展到一定程度,数据积累到一定量级都会发展出数仓(数据仓库)应用, 数仓一般用来做类似 BI 的业务帮助企业分析数据以做出决策, 我用知乎上一个仁兄举的例子来说, 比如需求会从最初非常粗放的:“昨天的收入是多少”、“上个月的 PV、UV 是多少”,逐渐演化到非常精细化和具体的用户的集群分析,特定用户在某种使用场景中,例如 “20~30 岁女性用户在过去五年的第一季度化妆品类商品的购买行为与公司进行的促销活动方案之间的关系”。这类非常具体,且能够对公司决策起到关键性作用的问题,基本很难从业务数据库从调取出来。 主要原因我觉得有 3 点:
所以综上所述, 到了这个阶段的企业不会再用 mysql 这种关系型数据库来构建数据仓库了, 而是使用诸如 hive 这样的技术来构建数仓。 因为数仓的要求一般为:
一般的大数据平台都会提供数仓的能力。 而构建数仓的第一步就是如何从各种数据源中把业务数据导入到数仓中(这其中还需要清洗过滤数据, 多表拼接, 规范 schema 等 ETL 流程)。 所以很多大数据平台会提供从各种数据源中把数据导入到平台自身系统存储的功能。 并且这些导入功能要保证功能的前提下也要保证性能,一致性,高可用等等。
好了, 上面说的都是背景, 是为了引出我们的测试需求而存在的。 现在我们知道了, 对于大数据平台类产品来说, 一般都得提供从非常多的数据源中导入数据的能力以应对客户的需求。 毕竟客户自己使用的数据存储花样层出。 那么对于测试来说, 如何能保证所有平台支持的数据源都是没有问题的是一个挑战。 这里面的难点有二:
专门针对上面第二点说,其实测试就是要保证所有数据源在导入的时候功能和性能都是合格的。 所以为了测试这种场景你就需要一个比较强大的造数工具, 可能有些同学会问干嘛不直接用线上数据。 当然如果有线上数据我也倾向于采集线上数据, 但是很多大数据平台其实都没有线上这个概念, 因为它们都是私有化部署在客户场地内的, 客户的数据是不会交给你的。当然不止这一个原因,我们有时候会碰到各种原因而无法使用线上数据。 所以我们在有些情况下,是需要这个造数工具的。 而这个造数工具有几个难点:
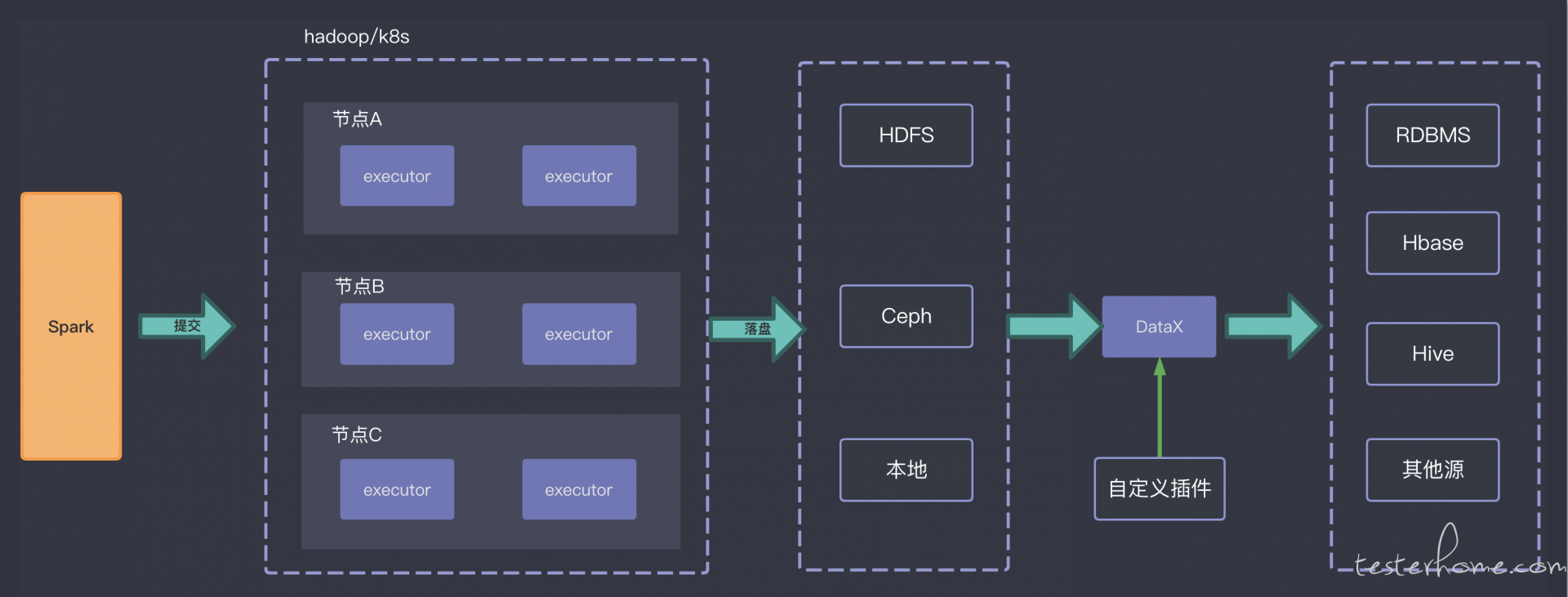
考虑到这 3 个难点, 所以我们在设计造数工具的时候采用了下面的方案
上面说的其实都是结构化数据, 那我们看看更复杂的场景, 比如我们把数据仓库扩展成数据湖, 数仓的特点是数据都是结构化的, 每个字段都是规定好的。 在导入数仓的时候就做过一轮处理了。 但数据湖的特点是不会对原始数据做处理, 而是直接导入系统中, 这些数据可能是结构化的也半结构化的也可能是非结构化的。 后续会有各种业务需要这些数据。 比如我们已经很熟悉的 AI 平台。 我们的产品对根据不同的数据提供不同的算子(数据处理程序), 有些时候是 ETL 程序, 有些时候是机器学习或者深度学习算法,针对机器学习算法来说做性能测试不仅仅要求数据的量级,也要求数据能抽取特征的维度。 我们可以通过在 spark 程序中控制数据分布来达到精准的控制特征维度的目的。 比如我们再造数的时候给某一列分配 1W 个唯一值, 也就是不管造多少行,都是在这 1w 值里面取的。 那么这一列就是精准的能抽取 1W 维特征出来。所以通过上面的造数工具我们是可以制定规则来满足这些算法的数据需要以测试其性能的。 问题在于非结构化数据, 比如图片,音频和视频。 我们如何能在短时间内造出海量的非结构数据呢? 比如我们之前接到过一个需求, 客户目前已经达到了几十亿张图片的量级。 虽然后面我们讨论过后决定只模式 2 亿级别的数据量,但这也是一个很大的挑战。 我们需要先生成一张图片, 再根据一定算法计算出图片的保存路径和其他元数据, 再把这些元数据保存到数据库中。 在这里面我们能想到的性能瓶颈在于:
后面经过讨论, 最后的方案是使用 golang 语言, 用协程 + 异步 IO 来进行造数:
原谅我懒了, 上面这个方案的架构图我实在是不想画了, 大家见谅。
在大数据产品的测试里, 经常会有这种造数的需求。 当然不是所有场景都是要造数测的。 如果大家不是在 TO B 产品中工作并且身处业务层,而不是数据中台层。 那么其实更多的就是直接用线上数据了。
