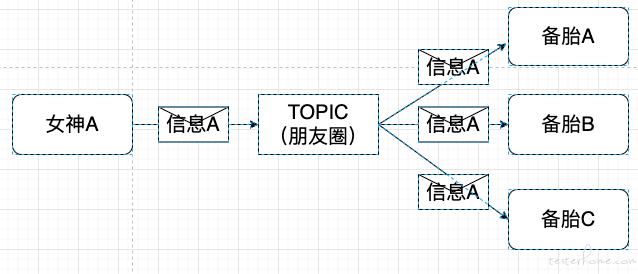
女神想找备胎 A 聊天,就单聊备 A,这就是点对点,只有一个人能收到消息
根据某科的介绍,MQ(message queue),叫消息队列,是基础数据结构中先进先出的一种数据机构。
一般用来解决应用解耦,异步消息,流量削锋等问题,实现高性能,高可用,可伸缩和最终一致性架构。
| 名词 | 解释 |
|---|---|
| 解耦 | 简单说就是积木化,每个东西都相互独立,比如汉堡包,面包跟肉饼是相互独立,可以单独使用,也可以组合成一个食物 |
| 异步 | 去买汉堡包,下单之后就去玩手机,等服务员叫号通知领取,这就叫异步;而同步是下单后,什么都不能干,直到服务员叫号才能做其他事 |
| 限流 | 大家 9 点上班,地铁进不去,门口做限流 |
| 削峰 | 遵从最后落地到数据库的请求数要尽量少的原则,比如让 1/2 的人下午开始上班、局部停电,感兴趣可以查看削峰填谷 |
| 消息 | 要传输的内容,比如说话、写信,形式不重要,按照双方约定的格式即可 |
| 队列 | 是一种先进先出的数据结构,排队打疫苗,从队尾入队,从队头出队 |
MQ 主要产品包括:RabbitMQ、ActiveMQ、RocketMQ、ZeroMQ、Kafka
通过上述的内容,不难发现,MQ是一种跨进程的通信机制,用于上下游传递消息,而个人觉得MQ有点像中介, 房东发布出租信息,信息放在中介处,租客来通过中介来租房子。
举个通俗点的例子:
面试官希望 HR 早点招聘到合适的人选,于是一开始是这样的:
HR 问面试官什么时候有空,把候选人资料送过去,并且亲自看到面试官看完并给出结论后才离开,时间一长,大家都觉得很麻烦,HR 觉得候选人不错,面试官觉得不合适,容易发生争执。
后面,HR 跟面试官说,我把资料放在桌子上,你有空记得看,然后每次面试官看到桌子有资料后,都会拿起来看。
在这个场景上,HR就是生产者,面试官就是消费者,桌子就是MQ。
使用MQ带来的好处是解决应用解耦,异步消息,流量削锋:
| 名词 | 解释 |
|---|---|
| 引入复杂度 | 「桌子」这东西是使用 MQ 后多出来的,需要有地方放桌子,而且流程会变长,更复杂 |
| 不一致性 | HR会以为面试官应该看了资料,但实际面试官可能还没开始看,这就导致了不一致性的问题,但在约束好的时间内,面试官最终的查阅状态与HR的认知必须是要一致的,这就是所谓的最终不一致性 |
| 系统可用性降低 | 如果桌子坏了,后面的流程是不是就中断了 |
当然,使用MQ还有很多问题要解决,比如资料无辜丢了、一样的资料,给了好多份、资料被抢、本来资料给面试官 A,结果给到面试官 B等场景都是需要处理的。
| 名词 | 解释 |
|---|---|
| 生产者不需要从消费者处获得反馈 | 面试官到底看了没有,HR 根本不需关注,默认面试官是看了,否则就只能采取监督看完的方式 |
| 容许不一致性 | HR 可能会发现有时候面试官说看了资料,但实际没看的情况,只有 HR 愿意相信面试官最后看了即可 |
| 有效 | 解耦、提速等带来的收益大于放置书桌是有成本的,那说明是有效的。比如一个月甚至半年才有一份简历,那还不如直接当面给更高效 |
Java 消息服务指的是两个应用程序之间进行异步通信的 API,它为标准消息协议和消息服务提供了一组通用接口,包括创建、发送、读取消息等,用于支持 JAVA 应用程序开发。
在JAVA中,如果两个应用程序之间对各自都不了解,甚至这两个程序可能部署在不同地方上,那么它们之间如何发送消息呢?
举个例子,一个应用程序 A 部署在印度,另一个应用程序部署在美国,然后每当 A 触发某件事后,B 想从 A 获取一些更新信息。
当然,也有可能不止一个 B 对 A 的更新信息感兴趣,可能会有 N 个类似 B 的应用程序想从 A 中获取更新的信息。
在这种情况下,JAVA提供了最佳的解决方案-JMS,完美解决了上面讨论的问题。
在该模型中,有下列概念:
消息队列 (Queue)、发送者 (Sender)、接收者 (Receiver)
每个消息都被发送到一个特定的队列,接收者从队列中获取消息。队列保留着消息,直到它们被消费或超时。
如果希望发送的每个消息都应该被成功处理的话,那么就需要点对点模型。
女神想找备胎 A 聊天,就单聊备 A,这就是点对点,只有一个人能收到消息
消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到 topic 的消息会被所有订阅者消费。。
在该模型中,有下列概念:
主题(Topic)、发布者(Publisher)、订阅者(Subscriber)
客户端将消息发送到主题。多个发布者将消息发送到 Topic,系统将这些消息传递给多个订阅者。
如果希望发送的消息可以不被做任何处理、或者被一个消费者处理、或者可以被多个消费者处理的话,那么可以采用 Pub/Sub 模型。。
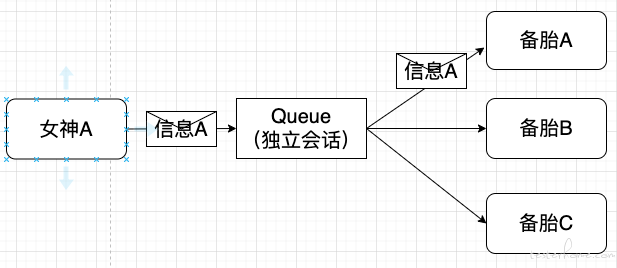
女神发了个朋友圈,她的备胎们都能看到,这就是发布/订阅。
点对点模型下,不可重复消费。
点对点下,一个队列可以有多个消费者,生产者发送一条消息到队列,消费者能用队列取出并且消费消息,一旦消息被消费后,队列不再有存储,所以其他消费者不能消费到已经被消费的消息,如果一直没有消费者处理,这条消息就会被保存,直到有可用的消费者为止。
发布订阅模型,可以重复消费。
发布订阅下,发布者发送到 topic 的消息,只有订阅了 topic 的订阅者才会收到消息,注意是所有订阅这个 topic 的服务都能收到,所以能达到消息拷贝的效果
虽然上面以一个招聘的例子来讲解 MQ 的应用场景,但可能还是会有疑问,不知道工作上是如何的,因此再讲讲工作上的场景。
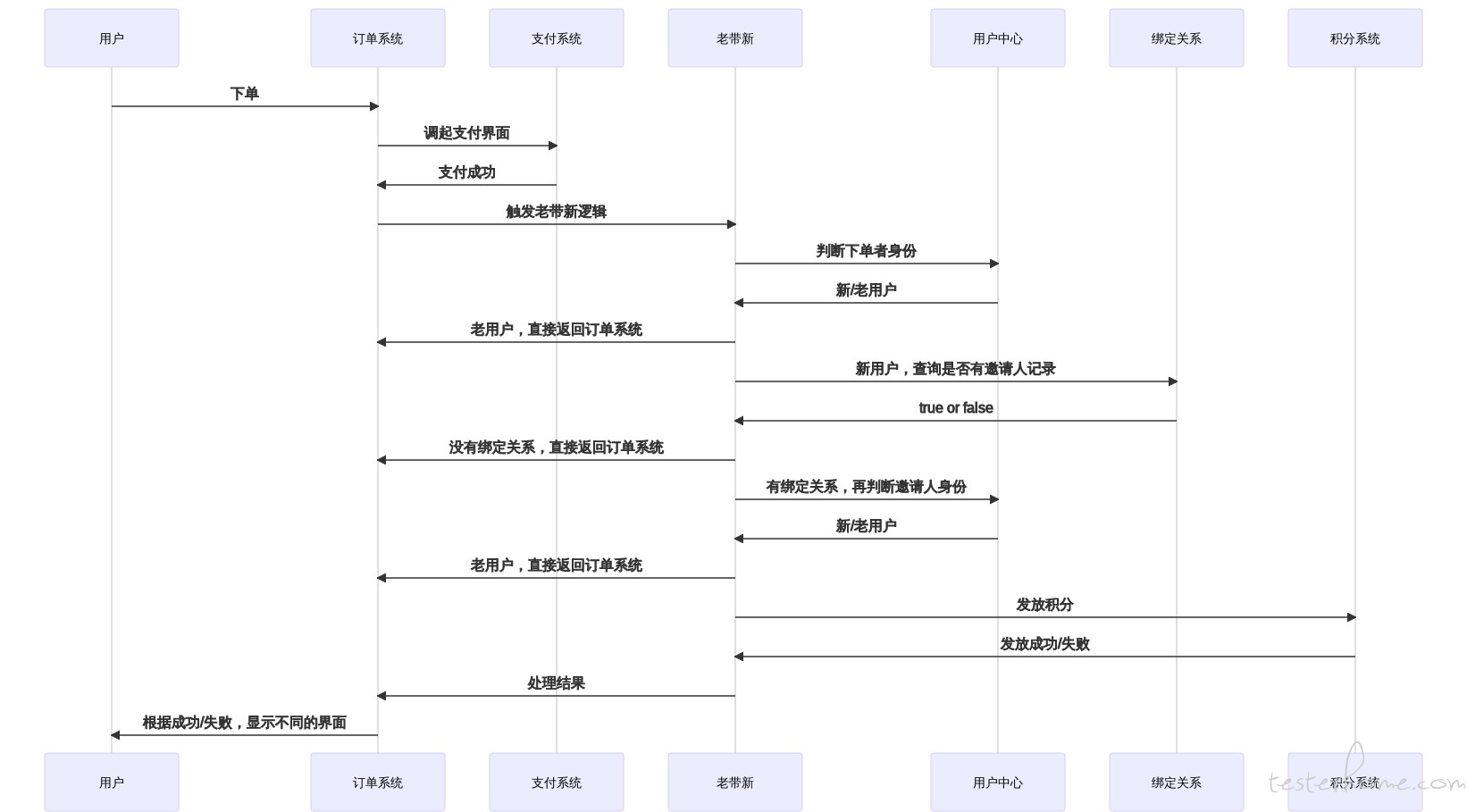
之前负责的一个需求叫老带新,大致流程如下:
1)用户下单后,会先判断下单者身份
2)如果是新用户,再判断是否有邀请人
3)如果有,再判断邀请人身份
4)如果是老用户,就给双方发积分
这样的话,用户的流程就会发生变化:
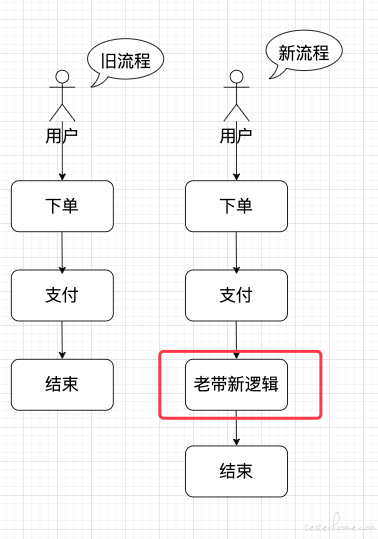
很明显,这样做的问题是:新增的逻辑存在堵塞下单主流程的风险。
既然同步处理会有问题,那就改异步吧,改完变成这样:
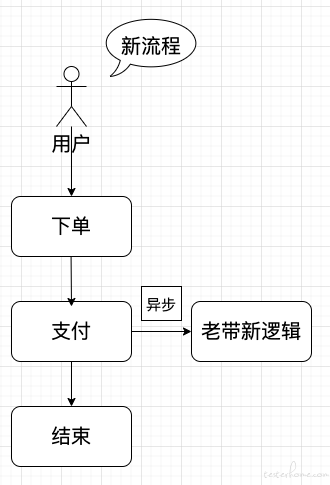
异步的好处是,即使老带新逻辑有问题,也不会堵塞下单流程。
这样的好日子没过几天,问题又来了:老带新业务频繁改动,导致下单系统频繁发版本,存在质量隐患。
由于依赖订单系统的业务越来越多,为了保证下单系统的稳定性,业务层面必须解耦,只需要把支付成功的消息告诉别的业务,他们收到了通知后自行处理,我们只管自己的流程,后续还有其他业务系统,直接订阅我们发送的支付成功消息。
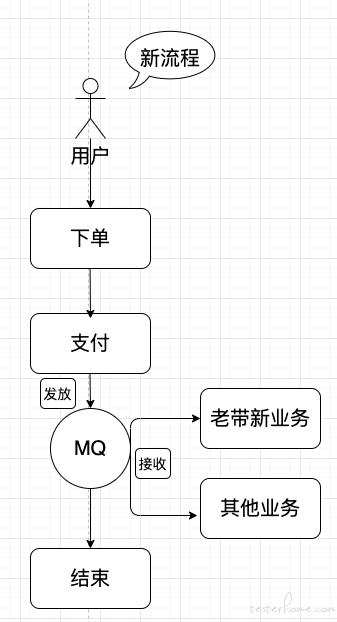
上面这些问题,都是实际工作上会遇到的,往往也都是测试点,下面也会有提及到,简单了解下即可。
| 产品 | 单机吞吐量 | 时效性 | 可用性 | 消息可靠性 | 功能支持 |
|---|---|---|---|---|---|
| ActiveMQ | 万级 | 毫秒级 | 高 | 较低概率出现丢失数据 | 极其完备 |
| RabbitMQ | 万级 | 微妙级 | 高 | 基本不丢 | erlang 开发 |
| RocketMQ | 十万级 | 毫秒级 | 非常高 | 可配置 0 丢失 | 分布式 |
| Kafka | 十万级 | 毫秒级 | 非常高高 | 可配置 0 丢失 | 分布式 |
而在选择上,一般公司都是用Kafka跟RocketMQ较多。
来来去去,花了一周的时间来整理这堆信息,之前有测过mq,但没有太了解这玩意,从介绍、选型、测试点,加深了对 mq 的印象,但由于没做过 mq 的性能测试跟自动化测试,所以这块暂时没有心得能输出,如果后续有类似的经历,也会分享下。
本文留下了一个悬念,针对消息不一致的问题,大家是怎么解决的,这边非常好奇,所以下篇计划会写分布式事务,想深入了解下细节~