
视频帧的黑、花屏的检测是视频质量检测中比较重要的一部分,传统做法是由测试人员通过肉眼来判断视频中是否有黑、花屏的现象,这种方式不仅耗费人力且效率较低。为了进一步节省人力、提高效率,一种自动的检测方法是大家所期待的。目前,通过分类网络模型对视频帧进行分类来自动检测是否有黑、花屏是比较可行且高效的。然而,在项目过程中,视频帧数据的收集比较困难,数据量较少,部分花屏和正常屏之间差异不够明显,导致常用的分类算法难以满足项目对分类准确度的要求。因此本文尝试了一种利用目标检测算法实现分类的方式,帮助改善单纯的分类的算法效果不够理想的问题。
一般分类任务的流程如下图,首先需要收集数据,构成数据集;并为每一类数据定义一个类型标签,例如:0、1、2;再选择一个合适的分类网络进行分类模型的训练,图像分类的网络有很多,常见的有 VggNet, ResNet,DenseNet 等;最后用训练好的模型对新的数据进行预测,输出新数据的类别。
目标检测任务的流程不同于分类任务,其在定义类别标签的时候还需要对目标位置进行标注;目标检测的方法也有很多,例如 Fast R-CNN, SSD,YOLO 等;模型训练的中间过程也比分类模型要复杂,其输出一般为目标的位置、目标置信度以及分类结果。

由于分类算法依赖于一定量的数据,在项目实践中,数据量较少或图像类间差异较小时,传统分类算法效果不一定能满足项目需求。这时,不妨考虑用目标检测的方式来做 ‘分类’。接下来以 Yolov5 为例来介绍如何将目标检测框架用于实现单纯的分类任务。
除了分类之外,目标检测还可以从自然图像中的大量预定义类别中识别出目标实例的位置。大家可能会考虑目标检测模型用于分类是不是过于繁琐或者用目标检测框架来做单纯的分类对代码的修改比较复杂。这里,我们将用一种非常简单的方式直接在数据标注和输出内容上稍作修改就能实现单纯的分类了。接下来将介绍一下具体实现方法:
1.数据的标注
实现目标检测时,需要对数据中的目标进行标注,这一过程是十分繁琐的。但在用于纯粹的分类上可以将这一繁琐过程简单化,无需手动标注,直接将整张图作为我们的目标,目标中心也就是图像的中心点。只需读取整张图像,获得其长、宽以及中心点的坐标就可以完成标注了。并定义好类别标签,正常屏为 0,花屏为:1,黑屏为 2。具体实现如下:
OBJECT_DICT = {"Normalscreen": 0, "Colorfulscreen": 1, "Blackscreen": 2}
def parse_json_file(image_path):
imageName = os.path.basename(image_path).split('.')[0]
img = cv2.imread(image_path)
size = img.shape
label = image_path.split('/')[4].split('\\')[0]
label = OBJECT_DICT.get(label)
imageWidth = size[0]
imageHeight = size[1]
label_dict = {}
xmin, ymin = (0, 0)
xmax, ymax = (imageWidth, imageHeight)
xcenter = (xmin + xmax) / 2
xcenter = xcenter / float(imageWidth)
ycenter = (ymin + ymax) / 2
ycenter = ycenter / float(imageHeight)
width = ((xmax - xmin) / float(imageWidth))
heigt = ((ymax - ymin) / float(imageHeight))
label_dict.update({label: [str(xcenter), str(ycenter), str(width), str(heigt)]})
label_dict = sorted(label_dict.items(), key=lambda x: x[0])
return imageName, label_dict
2.训练过程
该过程与目标检测的训练过程一致,不需要进行大的修改,只需要根据数据集的特性对参数进行调整。
# 加载数据,获取训练集、测试集图片路径
with open(opt.data) as f:
data_dict = yaml.load(f, Loader=yaml.FullLoader)
with torch_distributed_zero_first(rank):
check_dataset(data_dict)
train_path = data_dict['train']
test_path = data_dict['val']
Number_class, names = (1, ['item']) if opt.single_cls else (int(data_dict['nc']), data_dict['names'])
# 创建模型
model = Model(opt.cfg, ch=3, nc=Number_class).to(device)
# 学习率的设置
lf = lambda x: ((1 + math.cos(x * math.pi / epochs)) / 2) * (1 - hyp['lrf']) + hyp['lrf']
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
# 训练
for epoch in range(start_epoch, epochs):
model.train()
3.损失的计算
损失由三部分组成,边框损失,目标损失,分类损失,具体如下:
def compute_loss(p, targets, model):
device = targets.device
loss_cls, loss_box, loss_obj = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device)
tcls, tbox, indices, anchors = build_targets(p, targets, model)
h = model.hyp
# 定义损失函数
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.Tensor([h['cls_pw']])).to(device)
BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.Tensor([h['obj_pw']])).to(device)
cp, cn = smooth_BCE(eps=0.0)
# 损失
nt = 0
np = len(p)
balance = [4.0, 1.0, 0.4] if np == 3 else [4.0, 1.0, 0.4, 0.1]
for i, pi in enumerate(p):
image, anchor, gridy, gridx = indices[i]
tobj = torch.zeros_like(pi[..., 0], device=device)
n = image.shape[0]
if n:
nt += n # 计算目标
ps = pi[anchor, image, gridy, gridx]
pxy = ps[:, :2].sigmoid() * 2. - 0.5
pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]
predicted_box = torch.cat((pxy, pwh), 1).to(device) giou = bbox_iou(predicted_box.T, tbox[i], x1y1x2y2=False, CIoU=True)
loss_box += (1.0 - giou).mean()
tobj[image, anchor, gridy, gridx] = (1.0 - model.gr) + model.gr * giou.detach().clamp(0).type(tobj.dtype)
if model.nc > 1:
t = torch.full_like(ps[:, 5:], cn, device=device)
t[range(n), tcls[i]] = cp
loss_cls += BCEcls(ps[:, 5:], t)
loss_obj += BCEobj(pi[..., 4], tobj) * balance[i]
s = 3 / np
loss_box *= h['giou'] * s
loss_obj *= h['obj'] * s * (1.4 if np == 4 else 1.)
loss_cls *= h['cls'] * s
bs = tobj.shape[0]
loss = loss_box + loss_obj + loss_cls
return loss * bs, torch.cat((loss_box, loss_obj, loss_cls, loss)).detach()
4.对输出内容的处理
进行预测时,会得到所有检测到的目标的位置(x,y,w,h),objectness 置信度和分类结果。由于最终目的是对整张图进行分类,可以忽略位置信息,重点考虑置信度和分类结果:将检测到的目标类别作为分类结果,如果同时检测出多个目标,可以将置信度最大的目标的类别作为分类结果。代码如下:
def detect(opt,img):
out, source, weights, view_img, save_txt, imgsz = \
opt.output, img, opt.weights, opt.view_img, opt.save_txt, opt.img_size
device = select_device(opt.device)
half = device.type != 'cpu'
model = experimental.attempt_load(weights, map_location=device)
imgsz = check_img_size(imgsz, s=model.stride.max())
if half:
model.half()
img = letterbox(img)[0]
img = img[:, :, ::-1].transpose(2, 0, 1)
img = np.ascontiguousarray(img)
img_warm = torch.zeros((1, 3, imgsz, imgsz), device=device)
_ = model(img_warm.half() if half else img_warm) if device.type != 'cpu' else None
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float()
img /= 255.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
pred = model(img, augment=opt.augment)[0]
# 应用非极大值抑制
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
# 处理检测的结果
for i, det in enumerate(pred):
if det is not None and len(det):
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], img.shape).round()
all_conf = det[:, 4]
if len(det[:, -1]) > 1:
ind = torch.max(all_conf, 0)[1]
c = torch.take(det[:, -1], ind)
detect_class = int(c)
else:
for c in det[:, -1]:
detect_class = int(c)
return detect_class
为了将视频帧进行黑、花屏分类,测试人员根据经验将屏幕分为正常屏(200 张)、花屏(200 张)和黑屏(200 张)三类,其中正常屏幕标签为 0,花屏的标签为 1,黑屏的标签为 2。
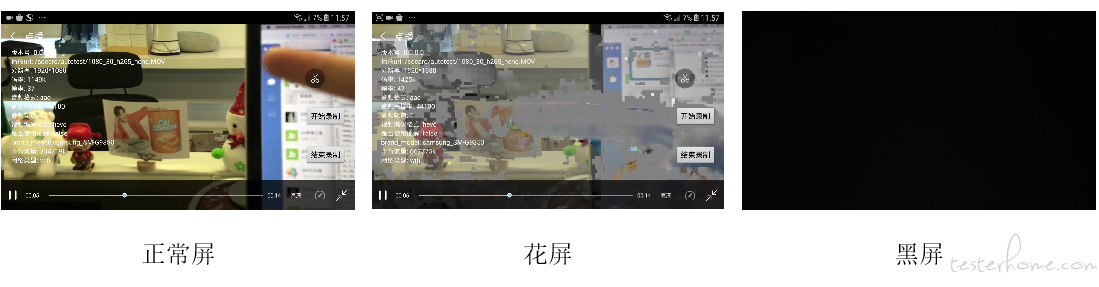
为了进一步说明该方法的有效性,我们将基于 Yolov5 的 ‘分类’ 效果与 ResNet 分类效果做了对比。根据测试人员对 ResNet 分类效果的反馈来看,ResNet 模型容易将正常屏与花屏错误分类,例如,下图被测试人员定义为正常屏:

ResNet 的分类结果为 1,即为花屏,显然,这不是我们想要的结果。

基于 Yolov5 的分类结果为 0,即为正常屏,这是我们所期待的结果。

同时,通过对一批测试数据的分类效果来看,Yolov5 的分类效果比 ResNet 的分类准确度更高,ResNet 的分类准确率为 88%,而基于 Yolov5 的分类准确率高达 97%。
对于较小数据集的黑、花屏的分类问题,采用 Yolov5 来实现分类相较于 ResNet 的分类效果会更好一些。当我们在做图像分类任务时,纯粹的分类算法不能达到想要的效果时,不妨尝试一下用目标检测框架来分类吧!虽然过程稍微复杂一些,但可能会有不错的效果。目前目标检测框架有很多,用它们完成分类任务的处理方式大致和本文所描述的类似,可以根据数据集的特征选择合适目标检测架构来实现分类。本文主要介绍了如何将现有的目标检测框架直接用于单纯的图像分类任务,当然,为了使得结构更简洁,也可以将目标检测中的分类网络提取出来用于分类。
