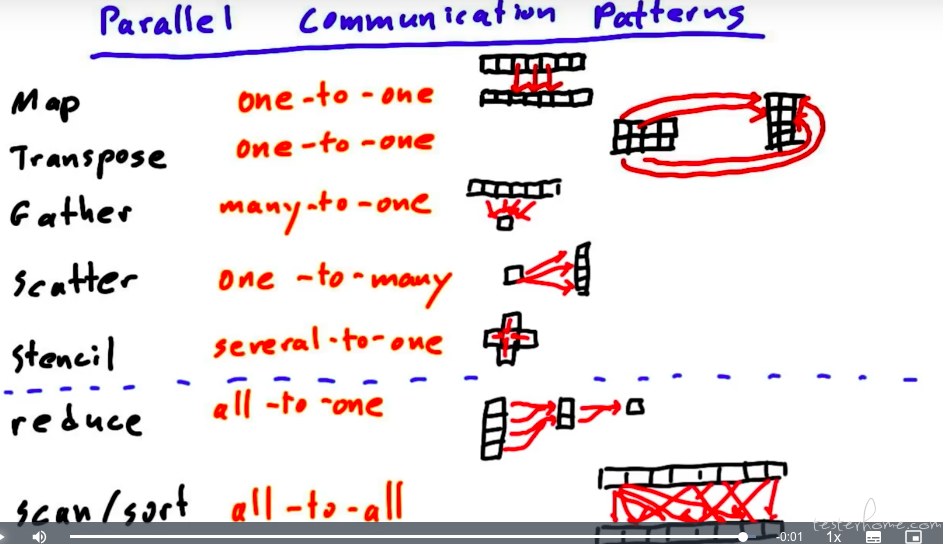
1->1 map
多->1/多 gather(求和/求平均,等等)
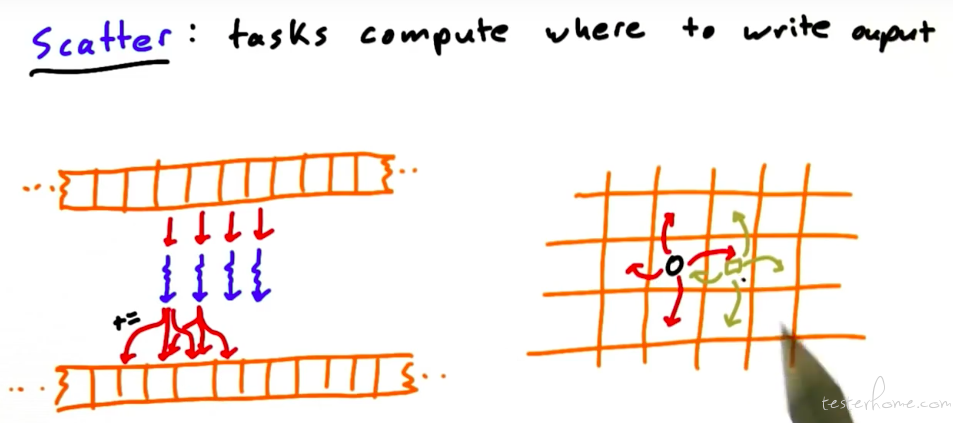
gather 的逆操作 scatter,这里得有个图解释下了:
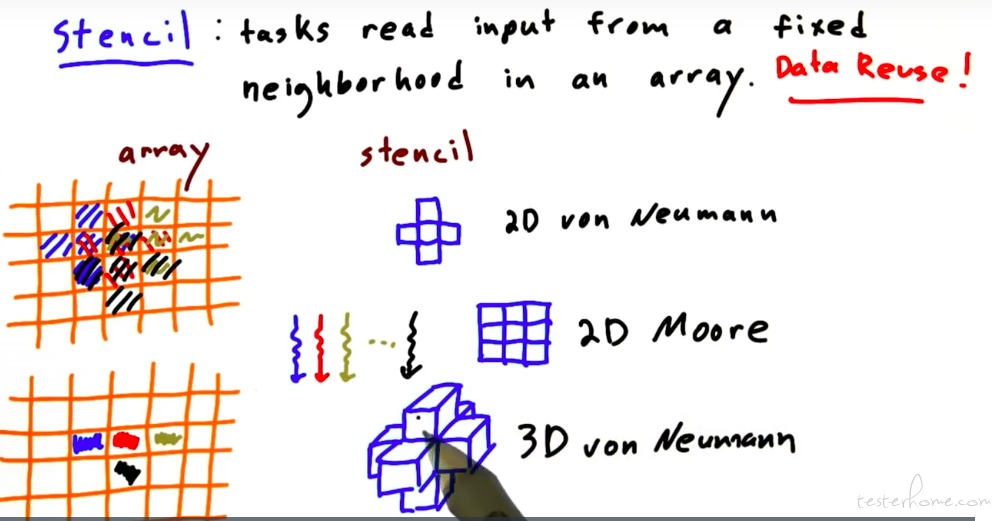
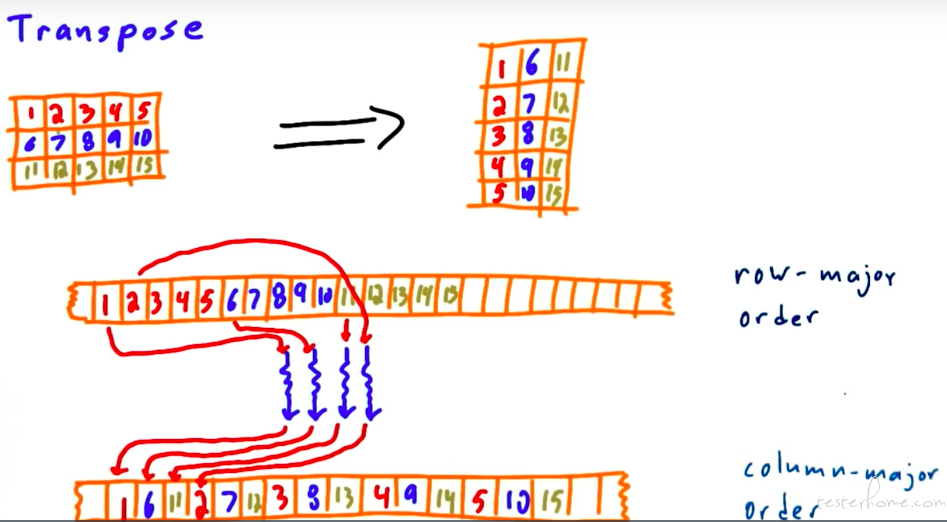
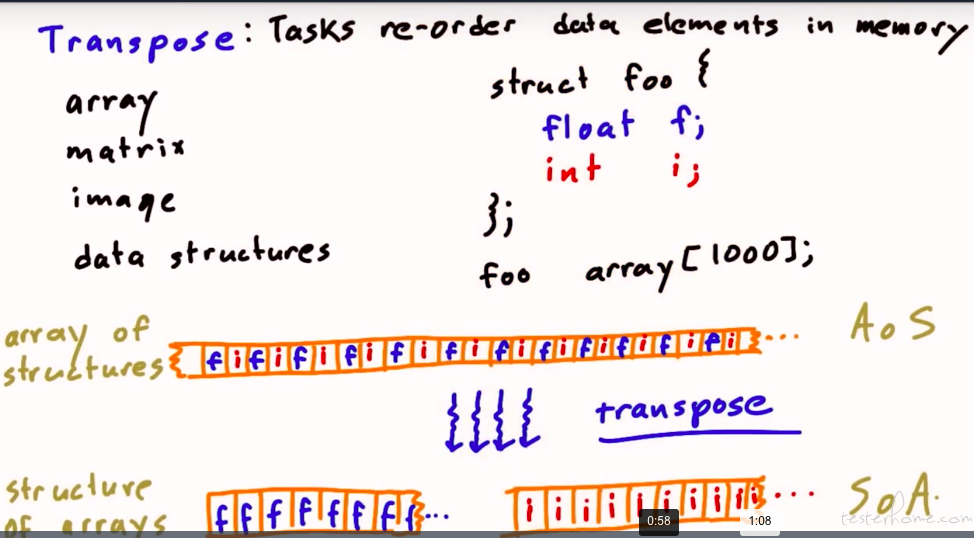
本节理论化做的很不错的。
在我自己的实际工作中也会经常用到。
主流的神经网络工具:tensorflow 默认的是 NHWC 的数据流,而 pytorch 是 NCHW 的数据流。
不同的排布意味着不同的内存分布。(端侧还是以 NCHW 的排布更多一点,虽然 RGB8888 的排布是 HWC 的,但是神经网络一般运算在 HW 维度重用的概率更高)。
运算类型总结:

不同于串行,并行对性能、安全的要求会更高。所以需要了解基础的硬件架构。
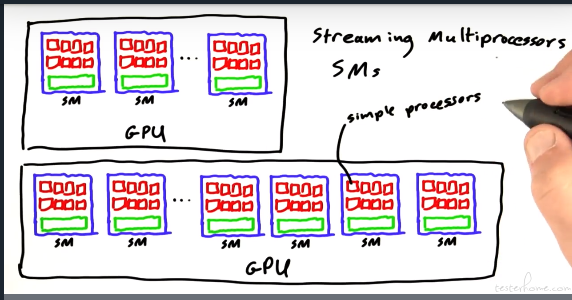
这里推荐一篇博文:
https://blog.csdn.net/junparadox/article/details/50540602
并行程序需要并行的内容没有顺序,没有交互:

这也是异构计算产生的原因。O(∩_∩) O
GPU 逻辑运算是不擅长的。
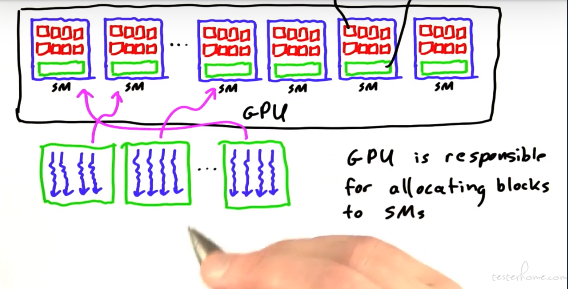
GPU 内部在并行执行的过程中,也会进行约束。
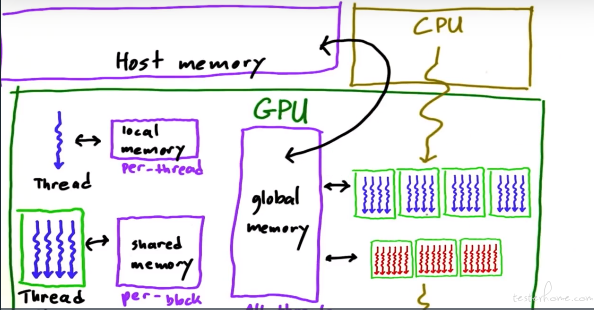
相比于 CPU 的 L1,L2,L3,GPU 的内存对应 local memory,shared memory,global memory。通常说的显存是 global memory,global memory 可以和 CPU 的内存进行交互。
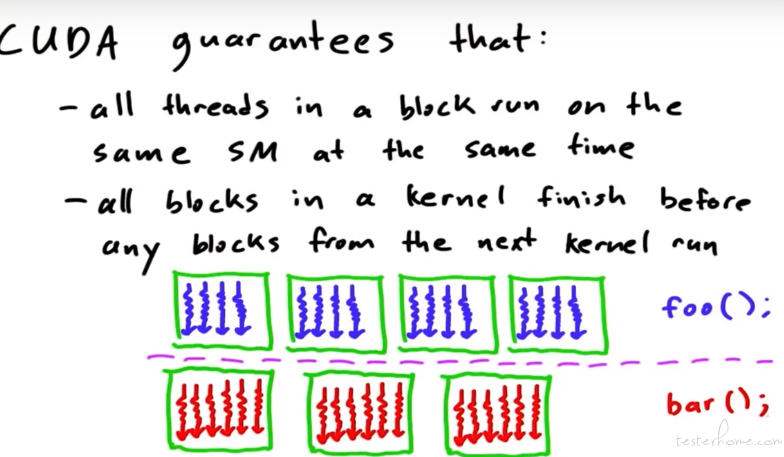
同步的引入:

Barrier:

并行操作会有同步操作
例子:
数组每个元素左移一位:

这里的同步 thread,当所有 thread 结束某行代码后,才会执行后面的代码。
补充一个例子来说明 syncthread:

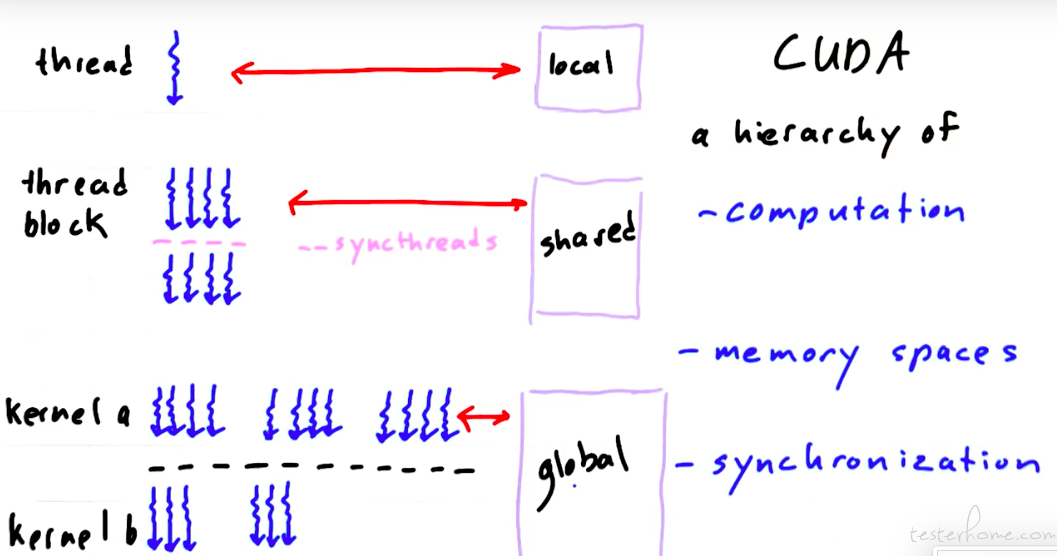
CUDA 正是基于内存、计算、同步而来的架构。
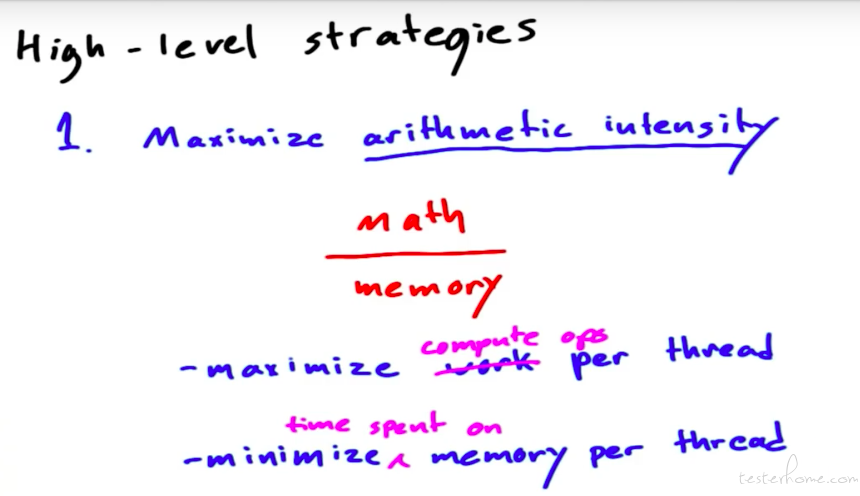
在实际的并行计算中,会有两种算子:1.运算密集算子,2.访存密集算子。在实际设计中,这算力和 IO 吞吐量这两个因素是相辅相成的。

可以看到内存的访问时间也远远小于 host 的访问时间,因此我个人理解:gpu 需要有足够的外部存储存储数据,一次输入一次输出,除此之外不要有和 host 的交互。
这里看一下 cuda 内存的应用:
1.本地内存:


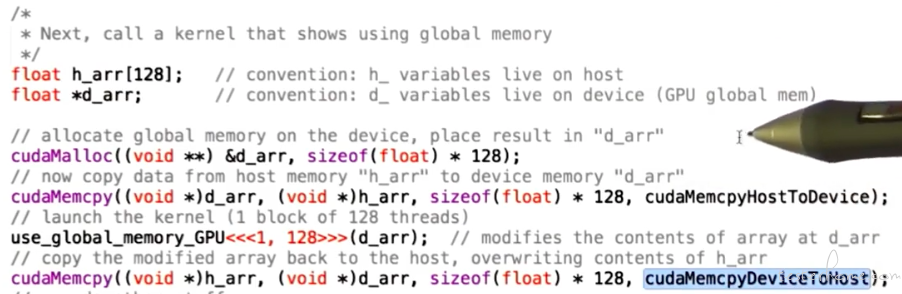
2.全局内存:

注意这里的入参是指针。
主程代码:
3.共享内存:

block 内部的可以通过 shared memory 进行操作,shared memory 的访问比全局内存快。
共享内存会有自己的生命周期,其生命周期就是 block,因此结果数据需要存储在全局内存中。
主程序中的实现和全局内存一致。
内存访问连续最好,因为可以成块预取。现代的计算机都是这样。

多个 thread 同时操作同一个内存区域,会出现内容错误的情况。
和 cpu 一样,这种需要原子操作。

CAS 是 compare and swap 的缩写。
原子操作的修改:
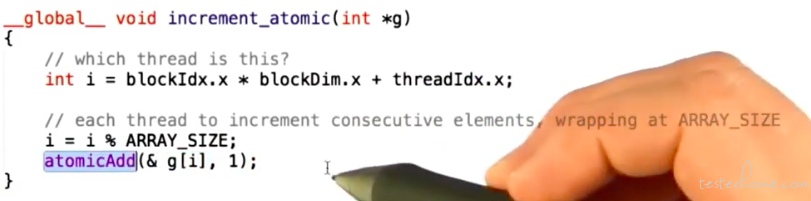
原子操作的缺陷:


but 没讲怎么解决啊。。。。
实际中可以把条件语句进行拆分,把一个运算根据 loop 的条件拆分成两个运算。
比如 1-30 做 A,31-60 做 B,拆分成两个独立的算子。
本节总结:

