
现代编译器中功能最多最复杂的部分是第四步优化。
编译主要有 5 部分组成:
现代编译器中功能最多最复杂的部分是第四步优化。
这里先从词法分析开始:

英语里每个词对应了动词、名词、形容词、副词。在程序中没有那么复杂。主要内容有:

这里会将程序需要中的每个标识符进行分类,然后传递给 Parser
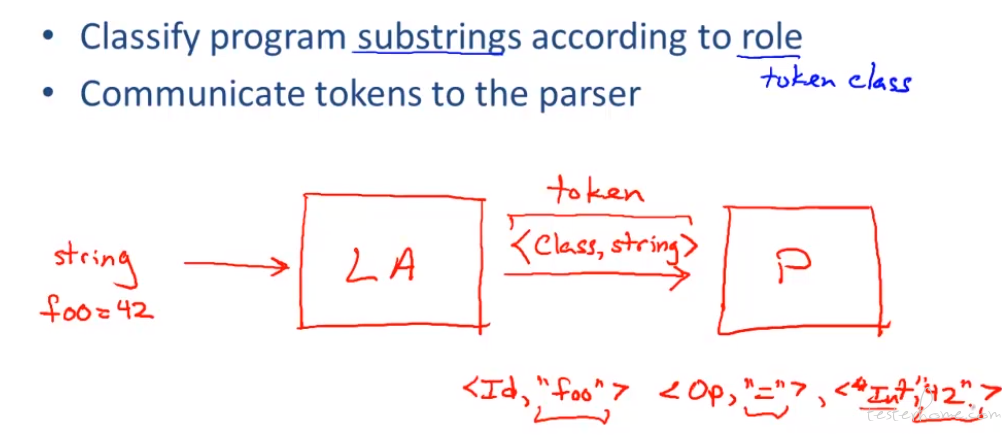
这里举了个例子:
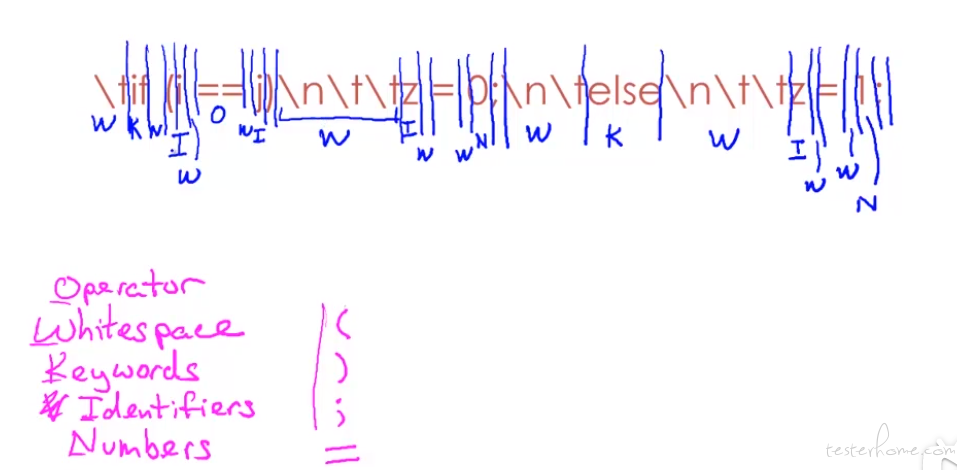
其中();等语言固定的标识符保持不变。


在 C99 的环境下,vector >中两个>之间需要有空格,这就是编译器的锅。

这里提了一个概念叫 lookahead,对于 look-to-right scan 要往长远看一些。
这里看一下正则的三种标准操作:
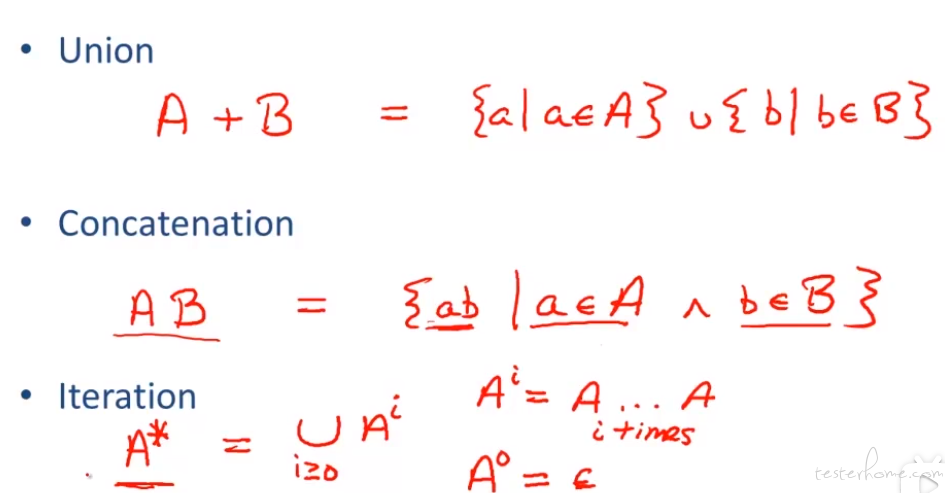
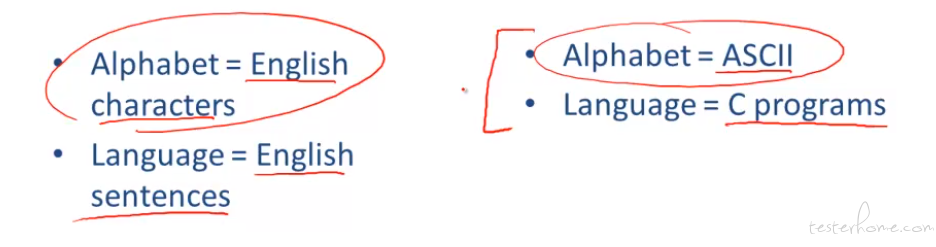
sigma 的定义

这里举了个例子来说明 sigma 的正则表达式

定义:

那么在字符集到语义的转化工程中会有一个转化函数:

这里介绍了怎么将表达式转化成语义:

需要关注的点:

转化语义的意义在于:

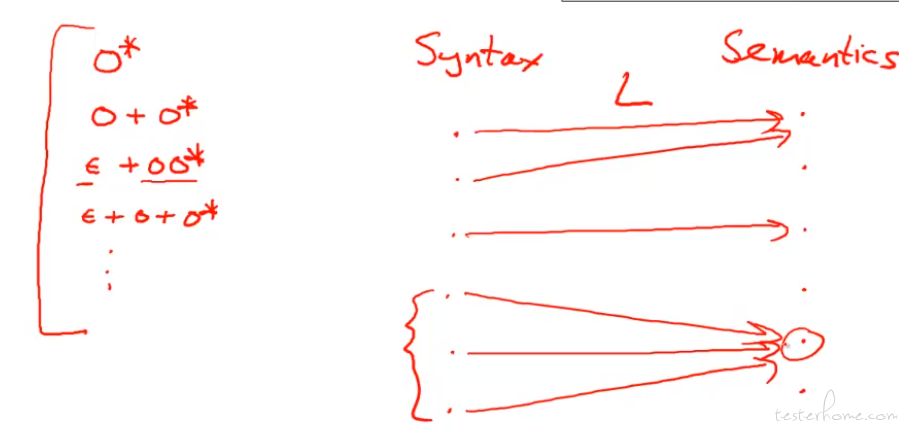


这里的正则是用来描述某个规则,这个规则对应的是一种类型。

正则的表示:

那么如何设计一种语言 L,让转化 ok 呢?
第一步,写下每一种类型的转化正则表达式:

第二步,把所有正则拼起来,组成一个大的 R。

后续步骤:

问题 1,=和==怎么区别?

使用 “Maximal Much” 的原则,匹配最长的优先级最高,如 R1 比 R2 优先级高,R1 匹配 3 字符,R2 匹配 4 字符,那么选择 R2
问题 2,if 同时满足关键字和变量的表达式,选哪个?

选优先级高的,关键字优先级高。
问题 3,如果没有匹配项怎么办?

做异常处理。
正则表示语言的总结:


正则表示式是转化语言的规范,有限状态机则是具体的实现。
有限状态机的图示:
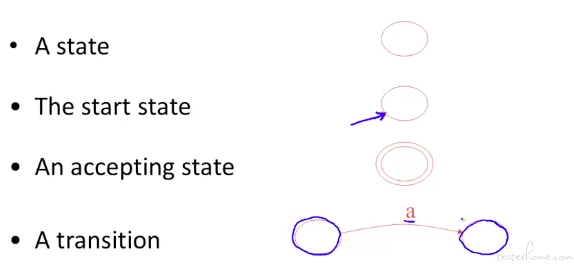
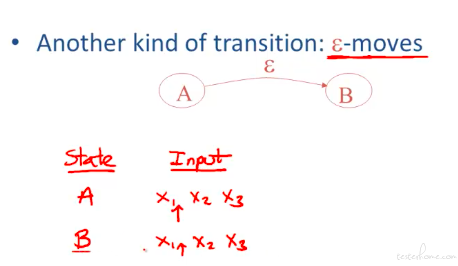
状态机有空转化的概念。


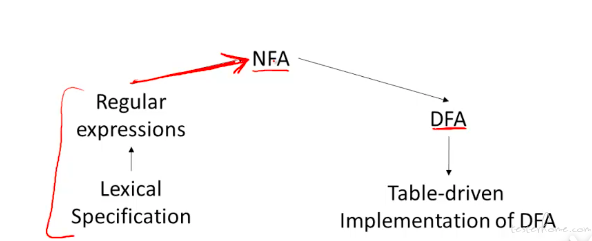
转化总的流程,这里主要介绍从正则表达式到 NFA 的操作:
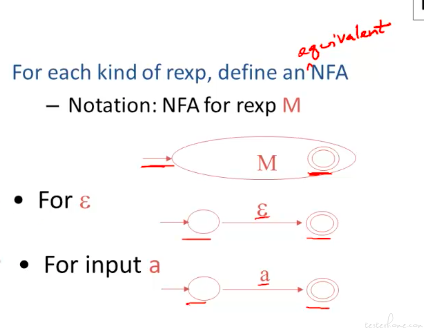
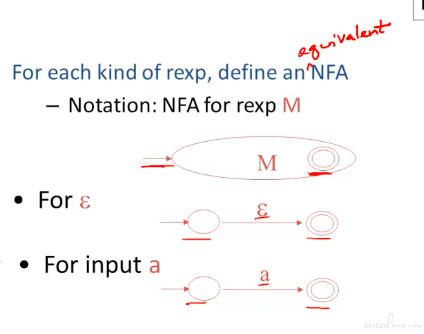
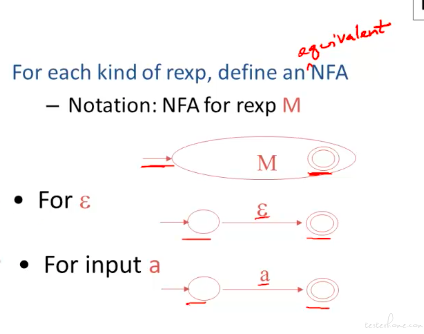
这里举了个例子将运算综合到了一起:
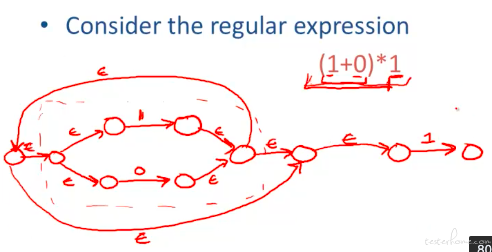
首先是一个概念 epision closure。
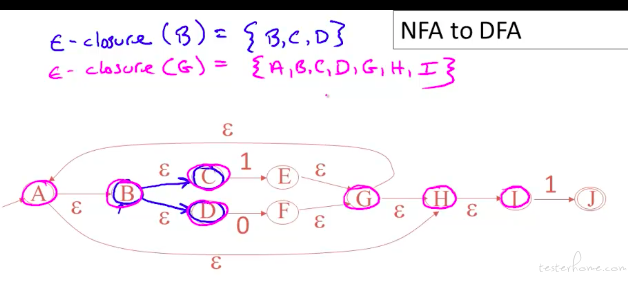
这是上一节例子的示例。

因为状态是有限的,所以状态组合也是有限的,因此虽然 DFA 可能很大,但是是一定存在的。
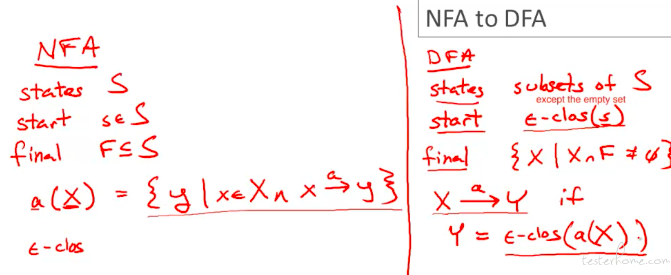
举例说明,用状态闭包替换原先的单一状态,还是前面的例子:
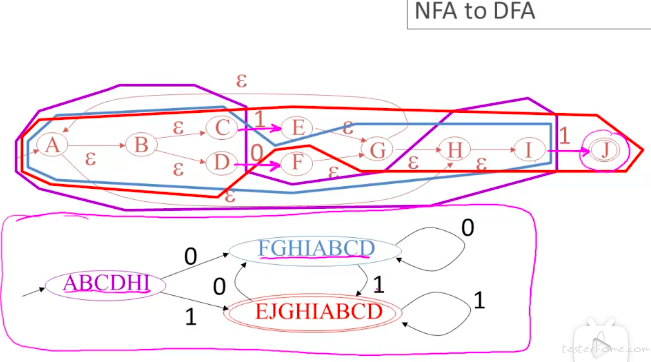

实际情况下,可以从 NFA 直接转
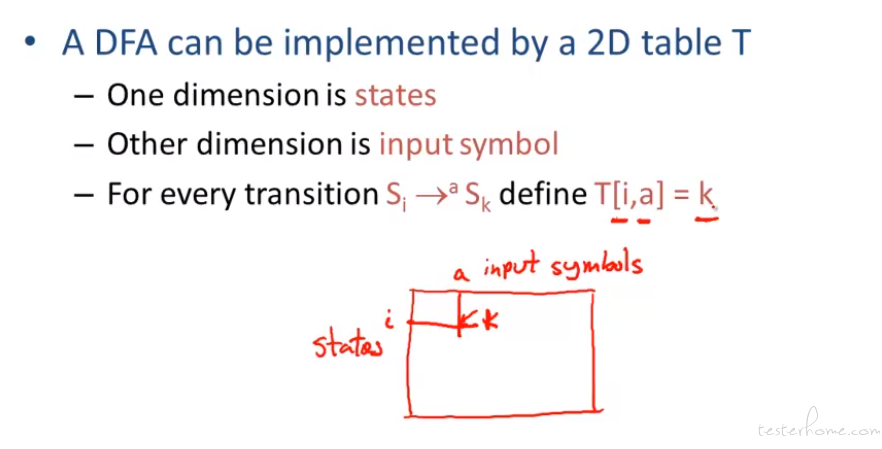
例子:
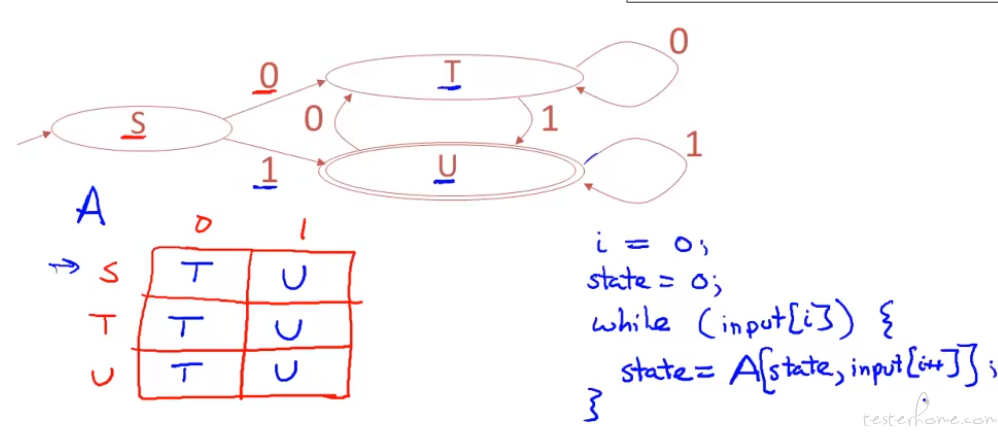
如果重复项较多,可以用 1 维 state 指向相同的指针

效率会稍低一些。
总结:

