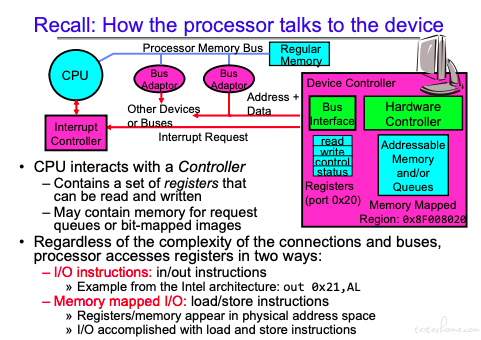
两种方式:
 在前面的章节中,又提示过,I/O 的这块映射内存独立且只有内核可以操作。
在前面的章节中,又提示过,I/O 的这块映射内存独立且只有内核可以操作。传递方式主要可以分为两种:
1.程序 I/O 控制
2.DMA
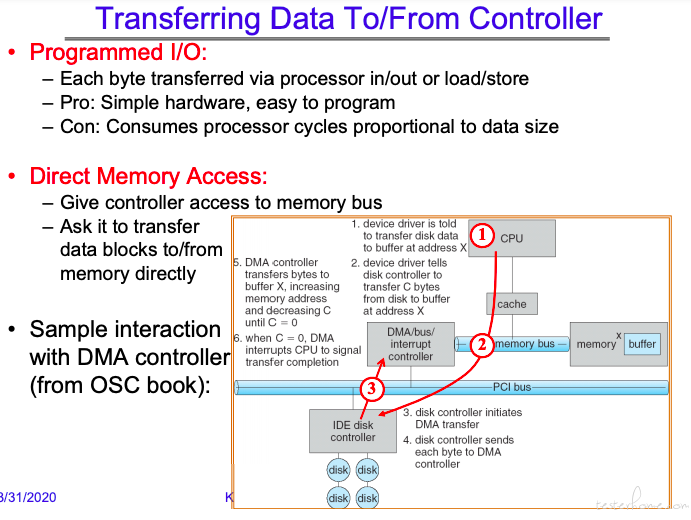
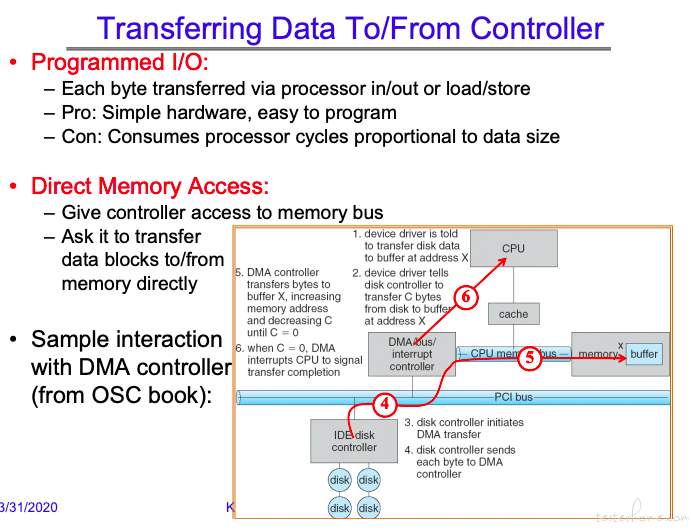
对于高速 I/O,使用 DMA 的情况更多一些。
这里又有两种方式:


最下面就是设备需要和 os 完成交互,完成 I/O 操作。


主要包括三个指标:
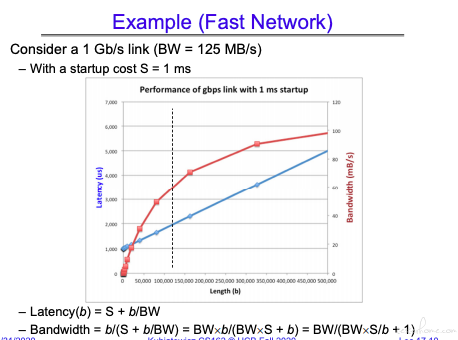

我目前理解计算机的体系结构是一种平衡,比如性能的瓶颈是由从总线到磁盘读写,到内存访问到网络访问等多个环节共同决定的,需要能够统一抽象的去理解设计思想和可能存在的问题
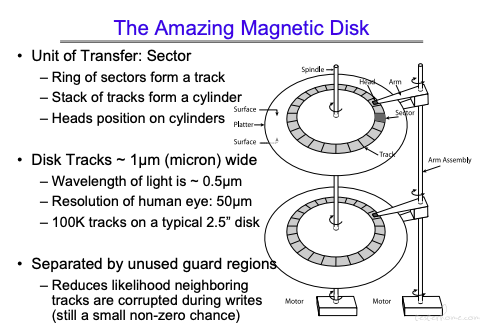
一个 sector 的大小是 512 字节,前面知道 page 的大小是 4kb,一般来说会把多个 sector 组成 block(一般也是 4K)进行数据传递
磁盘密度需要保持一致,这个应该可以理解。因为这个原因,同时要保证每个 track 的大小一致。
外部的磁道只有一半的空间是真正使用的
SMR 技术可以增加连续数据的存储容量:

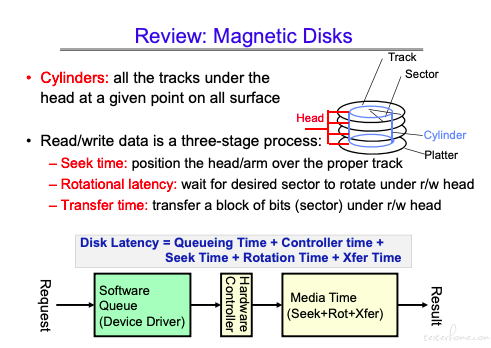
当下的磁盘性能指标:


计算机体系中的 locality 无处不在。

磁盘控制器做了不少事情,对于操作系统来说,它所要获取的信息是逻辑空间,具体的物理操作由 controller 完成。
这是历史积累下来的东西。
知乎看过一篇大佬的回答,想真正学好 cs,计算机基础概念 + 计算机发展历史

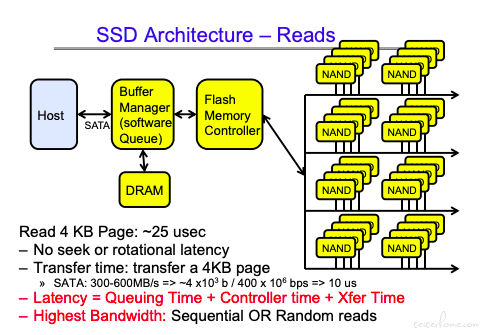
SSD 的结构:
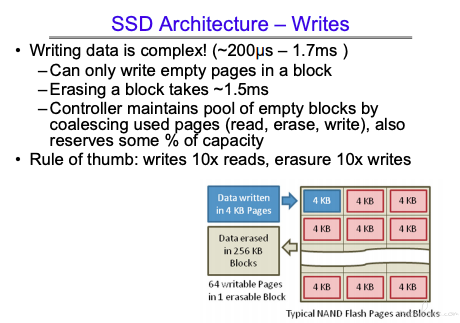
闪存最大的问题在于写盘的次数是有限的,因此擦写的时候需要使用不同的区块就行写操作。
写入的时间会稍长,主要是 SSD 的擦除机制,一次要擦除一个 block。
还要考虑 page 搬移的问题。所以相对较慢。
当前的 SSD:

这里还有 PCIE 的 SSD,我孤陋寡闻了。


# 队列和磁盘调度
I/O 的性能不仅仅在于具体的物理部件性能,同时也需要软件参与。
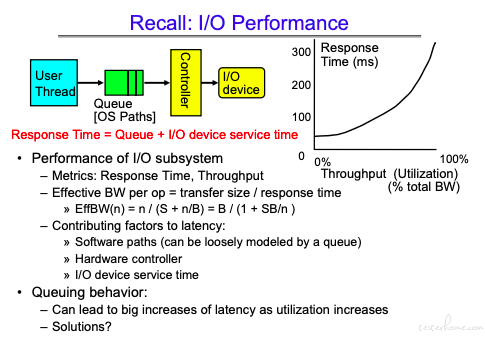
这里需要理解响应时间和吞吐量没有完全的匹配关系。因为可以通过流水线的并行设计方式,来增加吞吐量。
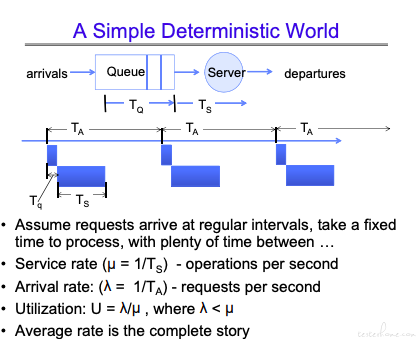
可以看到当进入 queue 队列的数据大于服务处理数据时,会进入饱和状态。在饱和状态下,利用率保持 1,但是队列会不断增长。

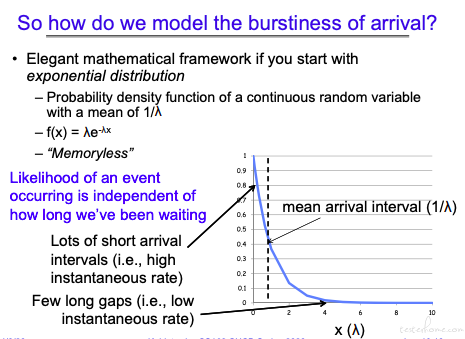
会认为事件的密度是一个指数分布,关于指数分布的解释:
https://baike.baidu.com/item/%E6%8C%87%E6%95%B0%E5%88%86%E5%B8%83
还是需要理解一下泊松过程和指数分布
变异系数:


稳态的时候,输入吞吐量=输出吞吐量
https://baike.baidu.com/item/%E5%88%A9%E7%89%B9%E5%B0%94%E6%B3%95%E5%88%99/
如何计算等候事件?
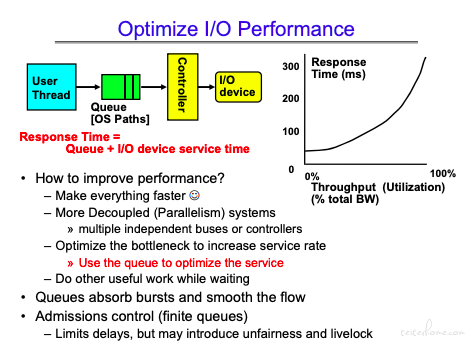
计算 Tq 和 Lq
可以看到当 u 趋近于 1 时,Tq 趋近于无限大。
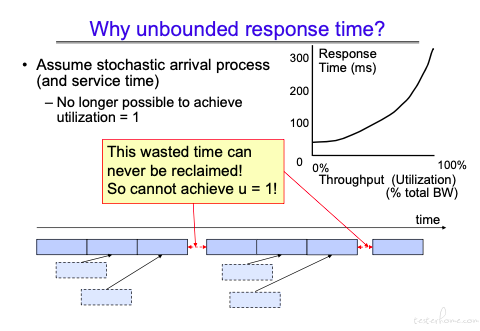
当存在突发的情况下,利用率是不可能达到 1 的,service 处理时终究会有处理间隔。
一个计算的例子:

可以看到利用率低的时候,负载比较小。
队列也是有专门的理论研究的,不过是以前看不到罢了😓
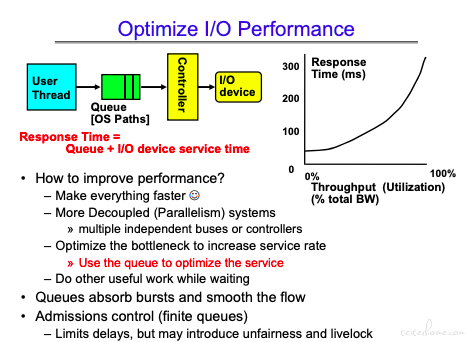
这里看到,更大的吞吐量会造成更大的等待延迟。(利用率越高,队列时间越长,balance forever)
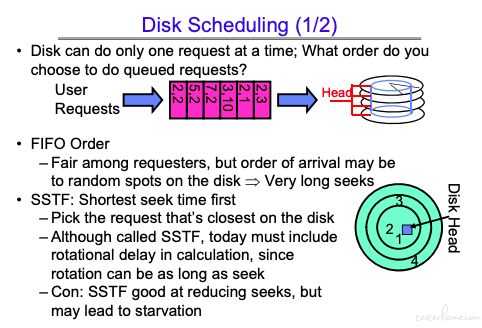
FIFO 移动的次数太多。
SSTF: Shortest seek time first 会导致饥饿现象
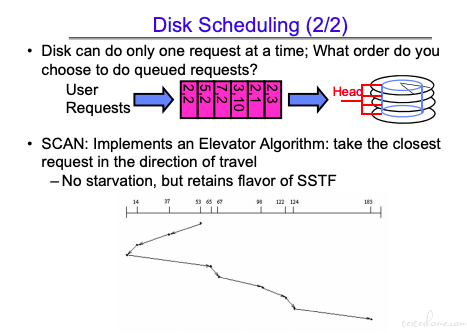
这也有缺点,缺点在于两边的数据调度间隔可能会很长。
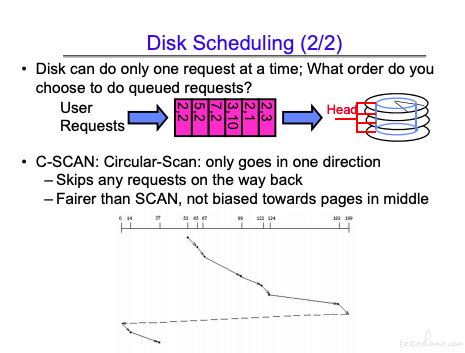
这个方法兼顾了效率和公平。
