
可以看到 Page Fault 是一个同步陷阱,是不能被屏蔽的。
发生陷阱时,会跳入内核态的处理程序并禁止中断。
前面说完了地址转化的流程。
从代码的逻辑地址到 CPU 的虚拟地址到内存的物理地址。
地址的转化依赖于物理地址已经实际存在,从这讲开始介绍内存申请相关的流程。
可以看到 Page Fault 是一个同步陷阱,是不能被屏蔽的。
发生陷阱时,会跳入内核态的处理程序并禁止中断。

现代的操作系统对于流水线、非顺序执行已经可以清楚的定位异常点了。
但是这个对于设计者来说依然是很难很容易出错的地方。
怎么解决的?不知道。。。这是因为 handler 的处理机制需要适配不同的硬件么?

1.权限错误的问题,是无法修复的。
2.指令错误的硬件问题(指令 fetch/data access)通过软件(OS)来处理。OS 处理完成后,再重试。这里是反转的概念。
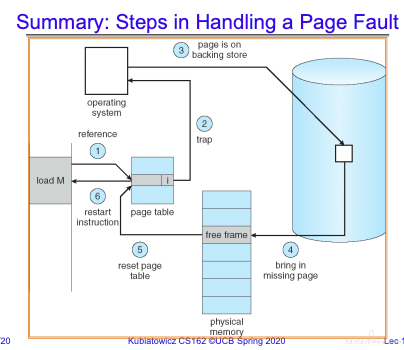
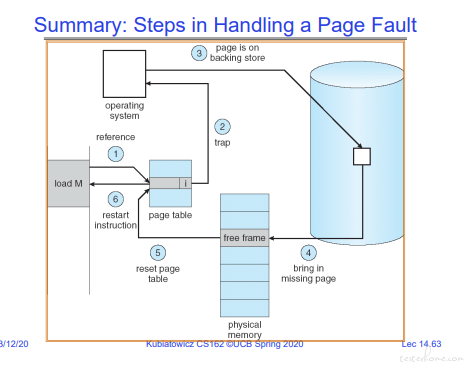
page fault 的主要流程:
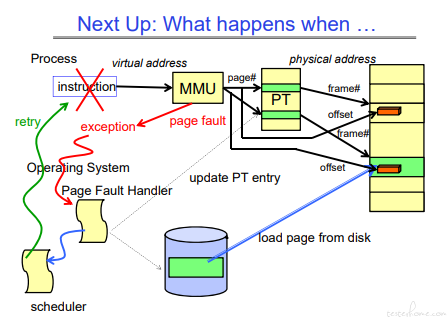
步骤如下:
1.当页表没找到的时候,触发 page fault,走上图红线的部分,触发 Page Fault Handler.
2.Page Fault Handler 将磁盘中的内容加载到内存中,然后更新页表。
3.接着走蓝色部分的操作,重新执行原指令。这时页表已加载,可以正常执行。

page fault 的过程中,不仅仅需要操作内存,还会更新 cache。
通常情况下,虚拟内存的空间会比物理内存大。(可以想想 64 位,虚拟内存 48 位有多大)
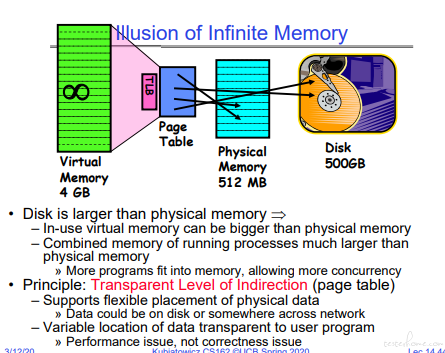
这里 TLB 只映射实存,page table 会映射磁盘等其他存储介质。
说到细节需要和 PTE(Page Table Entry) 的数据结构结合起来看,重点关注 P 位和 D 位:

机制如下:

这里的处理机制和 cache 的实现机制是基本一致的。
这里稍微难理解的一点是为什么需要把 TLB 置为无效,因为 TLB 无效后,才会去读取 Page Table。
当前的操作系统和原来的操作系统有了很大的区别。有大量的共享内存使用,用于线程间交互。(共享库的大量使用?)



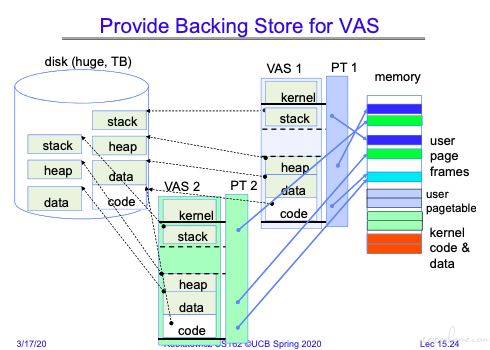
这里的 VAS 是 Virtual Address Space 的缩写。
磁盘中的文件会在磁盘的交换区分段做映射,页表中的无效页指向的是磁盘的交换区,有效页指向内存。
无效页指向磁盘交换区的操作由 os 完成而非硬件完成。
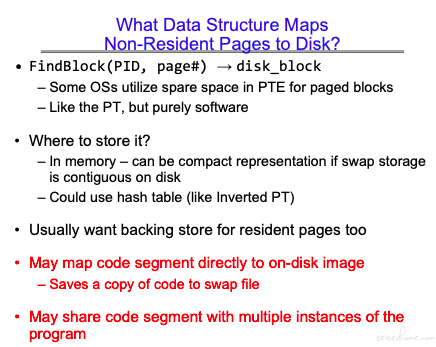
可以看到无效页的存储是通过 os 完成,同时有效页的内存也会映射到磁盘缓冲区。
同时对于相同的代码,可以转化成二进制文件,由多个进程共享。(这就是共享库)
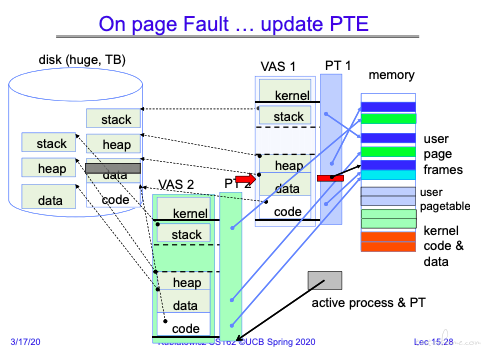
当进程 1 的 data 发生 page fault.触发陷阱,将磁盘中的数据 copy 到内存中。
同时切换进程由其他进程得到调度。
当进程 1 的磁盘数据 copy 完成后,通知进程 1 就绪。
当进程 1 得到调度时,重新执行触发 page fault 的指令。
这张总结图更容易理解一些:
一般国内的课程没讲到这里就结束了。。。
这课接着又问了三个问题:

工作集模型
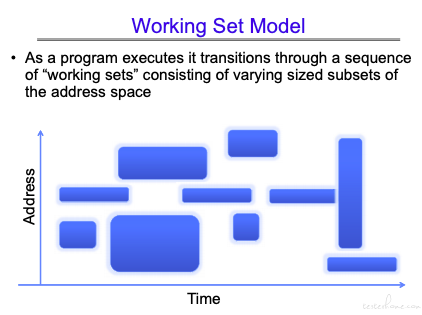
有兴趣的可以看:
https://blog.csdn.net/qq_28602957/article/details/53821061?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.control
Zipf 模型

按频率挑选数据,由于这个方法有长尾效应。
因此小 cache 它表现不错,但是大 cache 情况下也会比较糟糕。
从下图可以看到 page fault 对性能影响极其重要。


需要说明的是:
当并行任务导致内存不足时,可以将并行任务变成串行。内存不足导致的数据搬移时间要远远超过并行执行的时间。(Trashing)

这里需要理解一下 TLB 是因为需要在一个时钟周期内在硬件上完成,所以使用了 Random 的方法。
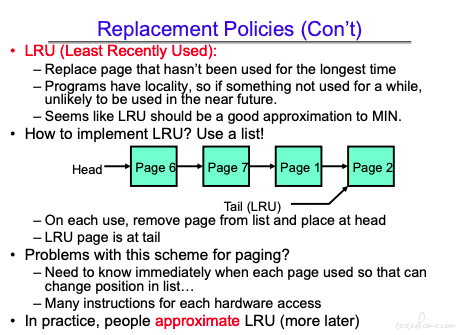
这里 LRU 并不适用。因为要判断一个页面是否是最近更改的需要具体分析内存操作的指令。同时,LRU 需要进行队列的搬移,频繁的指针操作并不快。
增加内存对替换策略的影响。

当然也总有些极限的情况,会导致 LRU 一直出现被替换的情况。


其算法思想是将最远使用的节点降低要求,将 page 分为最近使用和最近未使用两类。
这样就不需要频繁操作链表,只需要维护状态即可。
当触发 Clock Algorithm 的时候,必须要访问磁盘了,这里稍微慢一点也可以接受。而 LRU 需要一直维护链表,相比 LRU,Clock Algorithm 的执行效率更高。
只在最近未使用的链表中寻找页表,如果没有满足条件的,则使用 fifo 策略。

针对脏页需要更多的处理流程,这里使用 Nth Chance version of Clock Algorithm 做了部分优化。
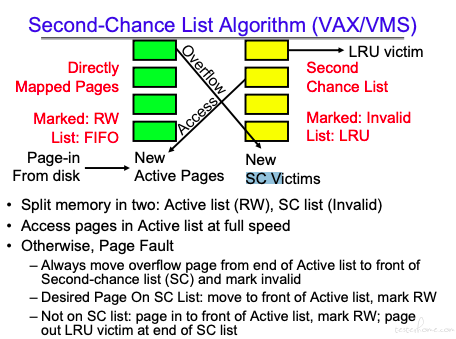
将内存分为两类:Active list 和 Second-Chance List
和前面策略都不同的是:Second-Chance List 里的内容是放在 DRAM 里的,但是标记为 Invalid,因此依然会触发 page fault.
在 Active list 的数据可以直接读写。
Active list 的队列策略是 FIFO,Second-Chance List 的队列策略是 LRU。
当发生 page fault 时,首先将 Active list 的队尾移入 Second-Chance List 队首。
如果在 Second-Chance List 找到对应的页,则将对应的页从 Second-Chance List 移除,移入 Active list 的队首。
当前申请页不在内存里,申请一个新的活动页,将该页移至 Active list 的队首,Second-Chance List 的队尾移除(该操作可能会触发写回操作)。

可以看到操作系统里,全是工程,很多都是各方的妥协。
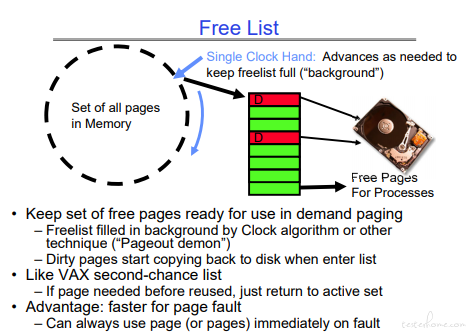
这里会使用一个 Pageout demon 的守护进程去扫内存,当有足够资源的时候,会尝试将脏页写回磁盘,完成后该页的 dirty 标志会被清除。

为什么需要物理地址的反向映射呢?
因为资源会有共享。。。释放共享资源需要快速找到对应的逻辑资源。
关于 Linux 的实现可以参考这篇文章:
https://blog.51cto.com/15015138/2557286
细节太多了,我就暂时先 pass 了。

系统需要至少给进程分配启动所需的内存页。
在内存交换的策略上,有全局内存替换和局部内存替换两个策略,后者对实时性要求更高,也增加了系统开发难度。

动态分配 page frame 的思想:
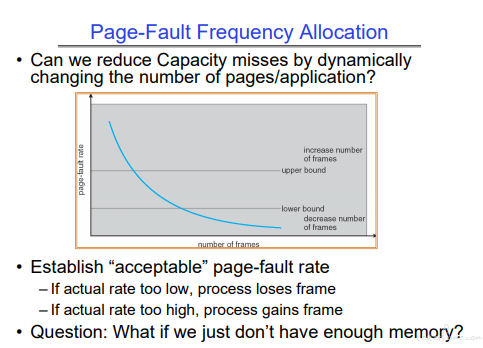
Trashing:
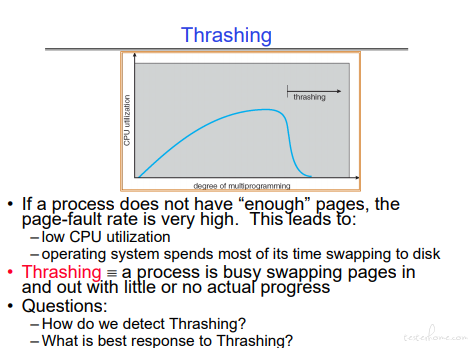
长期方案:加内存
短期方案:sleep 一些进程或者设置进程获取内存的上限同时缩减部分进程的内存占用。
通过 working-set model 分析内存占用情况,可以极大的改善 Trashing:


主要方法时多读几页内存。

可以看到真实申请的过程比前面讲的流程还要复杂。

这是 2017 年之前的结构

有兴趣的可以看看知乎这个问题:
https://www.zhihu.com/question/265012502/answer/347154598
# 总结

页面申请整体上又分全局和本地两个策略。
实际的操作系统只会更复杂。
