
掌握 sql 查询增删改查、子查询、关联查询、分组查询、分组过滤
但凡有职场经验的兄弟都知道,大厂的面试真是一言难尽,不光看你面试时的临场发挥能力,还要分 N 次考你对公司业务核心技术的熟悉度。
你要没有扎实的基本功,想忽悠住面试官可太难了。你去翻翻大厂那些 30、40K 的岗位就懂了:
关于数据库,我认为是软件测试工程师第一个要学的技术也是最重要的基础。
不仅你做功能测试要用到数据库;接口测试、很多接口的返回值它是动态的,那么你要去数据库拿数据来校验;还有自动化,怎么去做一些数据驱动,都要从数据库里去拿。你做性能测试是不是也和数据库有关。比如慢查询,都和数据库有关。
所以说,你要去面试软件测试工程师。数据库这一关你得要有底。
掌握 sql 查询增删改查、子查询、关联查询、分组查询、分组过滤
1.说一下你常用的 sql 优化方式?为什么 select* 效率低?
2.什么是索引?索引为什么能增加查询效率
3.索引是建的越多越好吗?
4.什么是 ORM?为什么要用 ORM?
5.如何将查询的数据汇总到 excel,txt 文件?6.关系型数据库和非关系型数据库的区别?
首先如果你要去面试,你得首先保证你掌握了 sql 的基本查询
增删改查
第一部分:软件测试基础理论、流程还有项目管理
增删改查大家基本都会吧,Select、Delete、Update、还有一个子查询、关联查询、分组查询、分组过滤。
子查询:就是一个嵌套在查询语句中的查询
关联查询:内连接、外连接(左连接、右连接)
我相信每次去面试的时候很多小伙伴都会去百度。搜素什么是什么子查询?什么是关联、分组查询?什么是分组过滤……经过熬夜看完了几篇 “深度好文” 可能面试官问,你也会胸有成竹。
如果以上的内容都不熟悉,就不要在简历中写:“我熟悉数据库的语句”
大家可能比较陌生的可能是分组查询 ( group by) 和分组过滤 (having)
分组查询 ( group by) 是一个按照表中一个或者多个字段,将数据进行分组,一般用于数据进行分类汇总。
如果读这一块还不是很熟悉的伙伴,可以去观看我录制的分组查询教学视频。https://www.bilibili.com/video/BV1E5411W7gX?p=99
第二部分:数据库
1.说一下你常用的 sql 优化方式?为什么 select* 效率低?
优化方式比如说你用到了 select*,那么我就会问你为什么 select* 效率低?
可能你会说因为 * 是查询所有的。
面试官:那还有呢?还有什么要补充的吗?
我:(抓抓头发,手儿无处安放)面试官,你干脆把简历还给我吧,我都不想再说下去了。
有很多时候是这样子的 ,当面试官问到你一个问题,如果你只知道一点点,你说出来一点点,面试官问你还有没有其他要补充的……
select* 为什么效率低?
第一个你需要根据你理解的原理,具体分析。有时候做测试你会去看一些 Mysql 的书籍,它会告诉你,一律不要用 * 作为查询的字段的列表。
为什么呢?
第一个,不需要的列会增加数据传输时间和网络开销。有些数据库和应用不在一台服务器。
比如我的应用数据库肯定是有一个服务器的,那你的后端前端可能不在同一台服务器上,会有很多网络开销。因为有时候我们在前端的操作都会用到数据库,如果你都用 select* 那么就大大增加了网络开销,它会去解析很多的内容。特别一些 select 语句比较复杂解析比较多的时候,会给数据库造成沉重的负担。
特别有一些大类型的字段,比如有一个叫做 text 、 它是非常大的
varchar(字符串类型)比如还有一些加密的、日之类的字段,增加网络消耗是非常明显的。即使这个 Mysql 服务器和客户端在同一台机器上,使用的协议 tcp 通信也需要额外的时间,所以说这个传输时间和网络开销肯定会加大。
那么对于这些无用的大字段,可能还会增加一些 IO 操作。(如果长度超过一定字节,它会把一些超出的速率数据化到另一个地方,然后再去读取这些记录就会增加一次 IO 操作)
其实还有一个非常重要的点,Mysql 有一个概念:覆盖索引(业界极为推崇的查询优化方式)
如果你用到了 select*,你将失去 Mysql 优化器覆盖索引策略优化的可能性。
2.什么是索引?索引为什么能增加查询效率
索引是和性能息息相关的一个东西
如果我们把数据库当做一本 “新华字典” 索引就是这个字典的目录。一般会针对 where(id 等于多少)条件后面的字段
索引既然是一个目录,那么它就可以分为很多级。(目录下面又有一个目录)
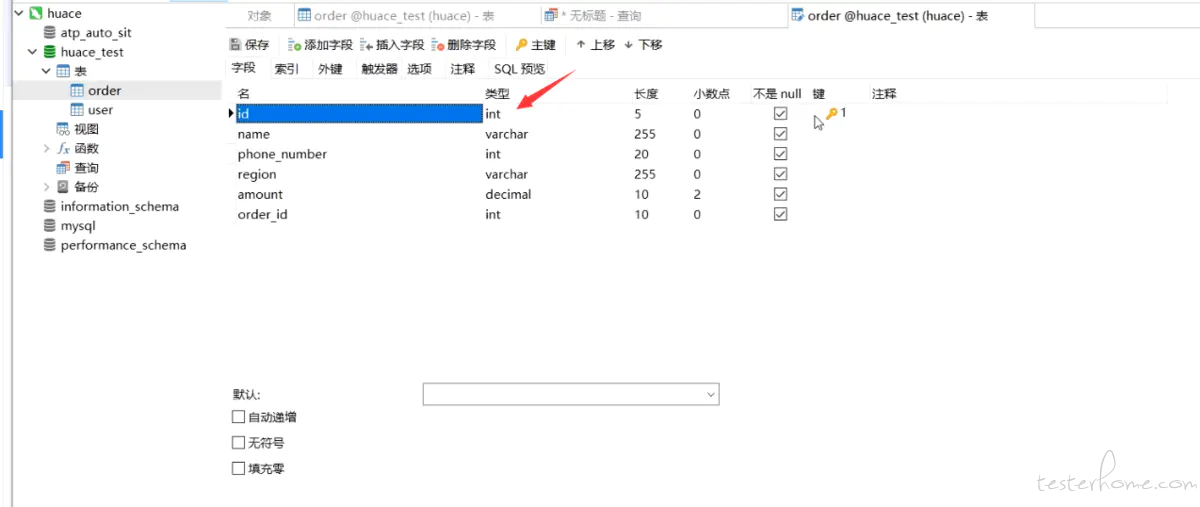
图中的 id 是一个 int 类型,那么图中的 “钥匙” 代表什么?主键。所以说 id 可能是主键,其他的一些就是字段名称、字段类型、字段的长度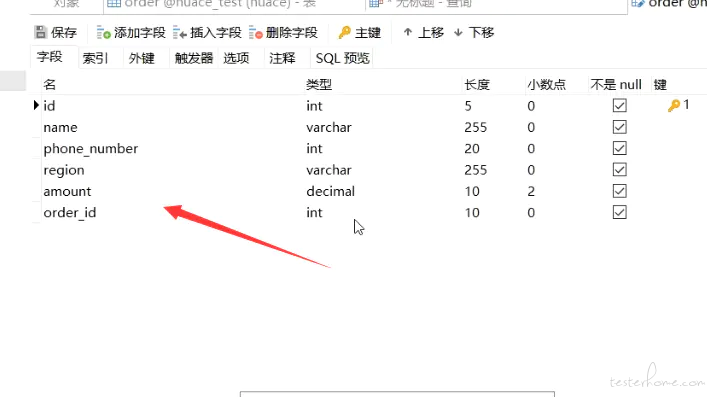
HON INDEX from orderl(查询某个表索引语句)
大家记住一个概念,主键本身就是一种唯一索引。
比如你要去查询 select * from where id=4 id 等于多少,它就用到了一种索引。所以说索引就是这个字典的目录,一般会针对 where 条件后面的字段。
所以说这样去查,如果你不是主键,那么会慢很多,如果你是主键是索引,就会快很多。
为什么索引能让查询变快?
数据结构
btree:二叉树算法
举个例子:
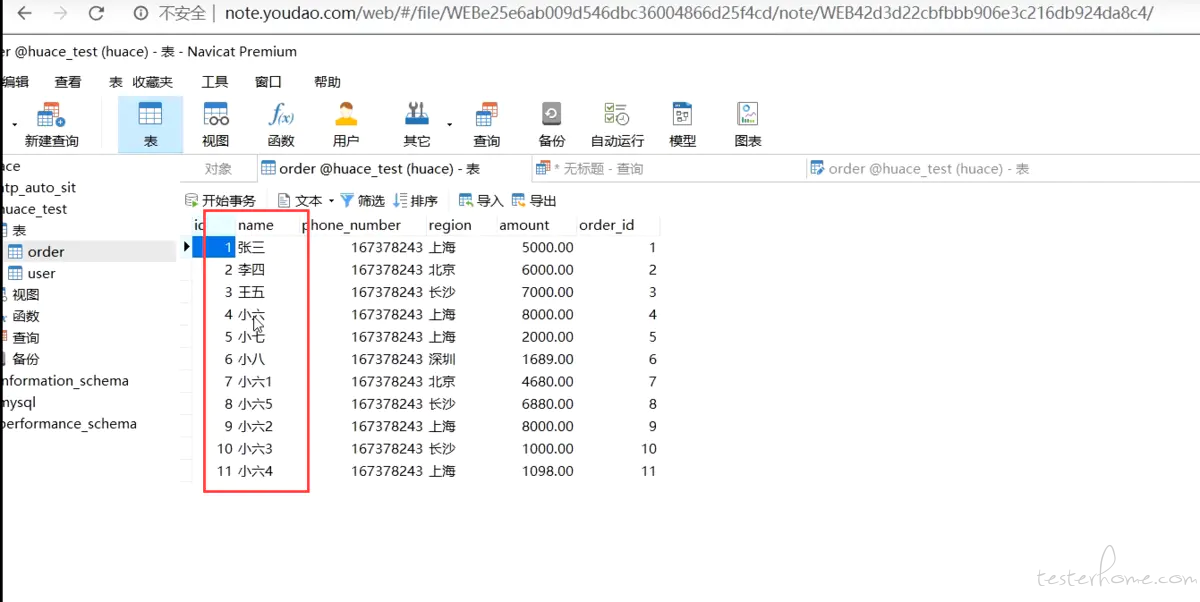 这个数据库表刚好有 11 行,当我想查询小六,比如说 select * from where id=4 的时候,这个时候如果不加索引。执行这行语句做的什么动作?就是一个一个查下去,查到 4 的时候还会往下查询,查 11 次。
这个数据库表刚好有 11 行,当我想查询小六,比如说 select * from where id=4 的时候,这个时候如果不加索引。执行这行语句做的什么动作?就是一个一个查下去,查到 4 的时候还会往下查询,查 11 次。
如果一般的有百万级的数据,它就会去查百万次。
如果我们用二叉树算法(索引)它会去查询多少次呢?
二叉树的原理:取中间一个数,大于的右移,小于的左移。每次减半。
11 个数据,二叉树的一个经典的算法,取中间的一个数,11 最中间的一个数是什么?是 6 对吧。那么它会把小于 6 的 12345 放一边,然后这里 7891011 也会放一边,他就会这样去进行。
我们来看一看如果它加了索引,它会查询几次。比如它第一次查 id 等于 4,它会取中间一个数等于 6,我们要的不是等于 6。根据原理,它就又会去取中间一个值,大于的右移,小于的左移 6 的中间值是 3,12 放左边,45 放右边。
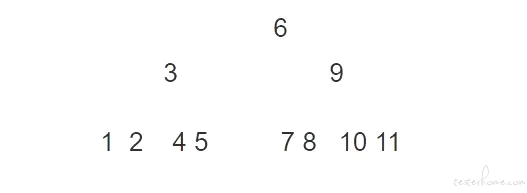
那么它可能查三到四次就可以查到了。这就是索引的效率,是不是会快很多?数据量大的时候提高效率可想而知。
更多测试教学视频资源可以来群里找我,备注公众号。
还有很多问题,比如什么是 ORM?为什么要用 ORM?(难度四颗星)大家不仅仅要说出这个概念,你要把它们的底层原理理解透彻。
面试中高级测试,往往三颗星的面试问题就刷了一大批人。
如果你这样从底层原理开始讲,面试官对你竖大拇指!你开一个工资吧,什么时候来上班?
听说点赞的人都拿了大厂 offer
絮叨
另外,一凡把自己的面试文章整理成了一本电子书,共 216 页!目录如下,还有我复习时总结的面试题以及简历模板
现在免费送给大家,链接: https://pan.baidu.com/s/10w3q4agGVh4R--HOvEYV-w 提取码: 3y8t
文章首发于公众号:程序员一凡
絮叨
如果你想去一家不错的公司,但是目前的硬实力又不到,我觉得还是有必要去努力一下的,技术能力的高低能决定你走多远,平台的高低,能决定你的高度。
如果你通过努力成功进入到了心仪的公司,一定不要懈怠放松,职场成长和新技术学习一样,不进则退。
一凡发现在工作中发现我身边的人真的就是实力越强的越努力,最高级的自律,享受孤独
