XML文件解析分四类方式:DOM 解析;SAX 解析;JDOM 解析;DOM4J 解析。其中前两种属于基础方法,是官方提供的平台无关的解析方式;后两种属于扩展方法,它们是在基础的方法上扩展出来的,只适用于 java 平台。目前已经完成一种方式的封装基于 DOM 的 XML 文件解析类。
语言我依然采用了Groovy模式,有兴趣的同学可以去看看:从 Java 到 Groovy 的八级进化论。还有更多高级特性实践可以在公众号里面搜Groovy即可,包括在JMeter中支持Java(即Groovy)脚本。
xml文件内容(已删节);
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<root path="/xdfapp">
<zknode name="DCSS" value="38d9ab9f3e7bfab1127cea3e42fb1237f9e73bdb">
<zknode name="v1.0$">
<zknode name="unchange">
<zknode name="datadb.database"
value="Export from zookeeper configuration group: [/xdfapp/DCSS] - [v1.0] - [unchange]."/>
<zknode name="redis.host"/>
<zknode name="db.host.w"/>
<zknode name="datadb.password" value="127.0.0.1"/>
<zknode name="datadb.host.r"/>
<zknode name="db.host.r"/>
<zknode name="datadb.host.w"/>
</zknode>
</zknode>
<zknode name="v1.0" value="10.10.1.3">
<zknode name="unchange" value="10.10.1.3">
<zknode name="db.database" value="******"/>
<zknode name="db.password" value="***"/>
<zknode name="dbdata.password" value="***"/>
<zknode name="dbdata.database" value="****"/>
<zknode name="redis.port" value="**"/>
<zknode name="datadb.username" value="****"/>
<zknode name="db.host.r" value="******"/>
<zknode name="dbdata.port" value="***"/>
<zknode name="datadb.database" value="********"/>
<zknode name="datadb.password" value="dsjw2015"/>
<zknode name="db.port" value="3306"/>
<zknode name="pgc.resources.url" value="http://*******"/>
</zknode>
<zknode name="change" value="10.10.1.3"/>
</zknode>
</zknode>
<zknode name="ailearn-work-svr" value="******">
<zknode name="v1.0$">
<zknode name="unchange">
<zknode name="v3.db"
value="Export from zookeeper configuration group: [/xdfapp/ailearn-work-svr] - [v1.0] - [unchange]."/>
<zknode name="work.host"/>
<zknode name="v3.host"/>
</zknode>
</zknode>
<zknode name="v1.0" value="*******">
<zknode name="unchange" value="*****">
<zknode name="v3.port" value="****"/>
<zknode name="work.passwd" value="*****"/>
<zknode name="work.port" value="3306"/>
<zknode name="v3.host" value="*********"/>
<zknode name="work.user" value="*********"/>
<zknode name="v3.db" value="******"/>
<zknode name="v3.user" value="******"/>
<zknode name="work.db" value="**********"/>
</zknode>
</zknode>
</zknode>
</root>
工具类:
package com.fun.utils.xml
import com.fun.base.exception.FailException
import com.fun.frame.SourceCode
import org.dom4j.*
import org.dom4j.io.SAXReader
import org.slf4j.Logger
import org.slf4j.LoggerFactory
/**
* 基于dom4j解析xml工具类
*/
class XMLUtil2 extends SourceCode {
private static Logger logger = LoggerFactory.getLogger(XMLUtil2.class)
static List<NodeInfo> parse(String path) {
SAXReader reader = new SAXReader();
try {
Document document = reader.read(path.startsWith("http") ? new URL(path) : new File(path));
Element rootElement = document.getRootElement();
def iterator = rootElement.elementIterator()
List<NodeInfo> info = new ArrayList<>()
while (iterator.hasNext()) {
info << parseNode(iterator.next() as Element)
}
return info;
} catch (DocumentException e) {
logger.error("解析文件${path}失败!", e)
}
FailException.fail("解析文件${path}失败!")
}
static NodeInfo parseNode(Element e) {
if (e.getNodeType() != Node.ELEMENT_NODE) return null;
def info = new NodeInfo()
List<Attribute> attributes = e.attributes();
List<Attr> attrs = new ArrayList<>()
attributes.each {
attrs << new Attr(it.name, it.value)
}
info.setAttrs(attrs)
List<NodeInfo> children = new ArrayList<>()
def iterator = e.elementIterator()
if (iterator.hasNext()) {
children << parseNode(iterator.next() as Element)
}
info.setChildren(children)
return info;
}
}
后续会进行优化和改进,最新代码请移步我的 git 地址:https://github.com/JunManYuanLong/FunTester,点击阅读原文也可以。
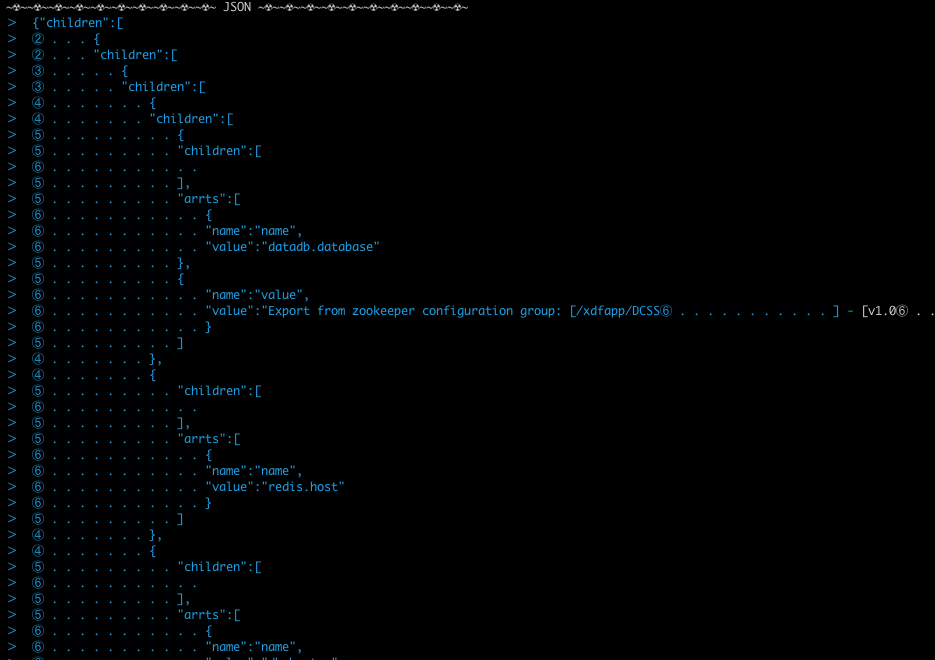
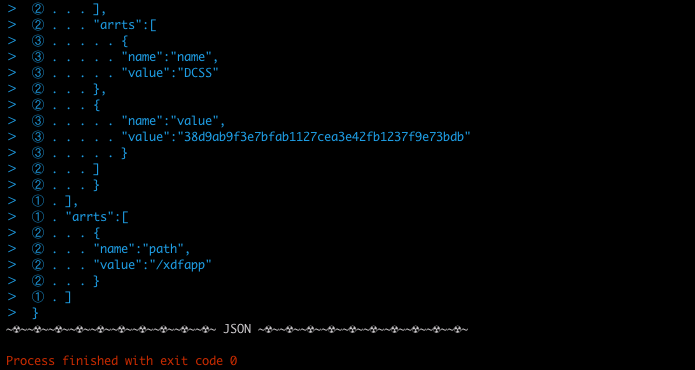
控制台输出:
内容较多,分成了头尾两张。
公众号FunTester首发,原创分享爱好者,腾讯云和掘金社区首页推荐,知乎七级原创作者,欢迎关注、交流,禁止第三方擅自转载。
