大致描述如下:并发上传 10 个文件的时候,接口完全没有响应,通过看服务器日志发现,请求根本没有到服务端,直接被某个地方拦截了。
这是一个给第三方压测之后,第三方反馈的性能问题。
大致描述如下:并发上传 10 个文件的时候,接口完全没有响应,通过看服务器日志发现,请求根本没有到服务端,直接被某个地方拦截了。
按道理来说,10 个并发数量不是很大,jmeter 不会卡住的,于是让他们排查线程池队列,nginx 队列,mysql 队列,都没有发现问题
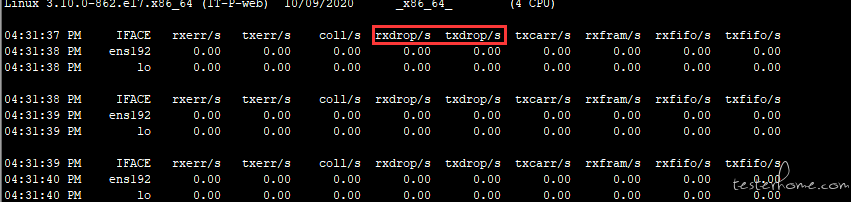
唯一的问题是这十个文件都比较大,大约是 14 兆左右的 pdf 文件。同时上传可能会对网络有影响。于是排查一下网络环境,看看有没有丢包
监听了一会,发现根本没有网络流量,所以不存在丢包坏包等现象
纠结了一会,一筹莫展,连运维都一起拉进来研究这个问题

正在没头绪的时候,突然想到看一下日志,于是实时打印了一下设备日志,发现了一条奇怪的日志
watch "dmesg | tail -20"

感觉是 gro 导致的 tcp 异常,看到 GRO,就突然想起了一个熟悉的词mtu。这两个有什么关联?
mtu 是最大传输单元
如果 I P 层有一个数据包要发送,而且数据的长度比 M T U 值还大,那么 I P 层就需要对数据进行切片,把数据包分成若干片,这样每一片都小于 M T U 值
现在网卡都有 LRO/GRO 功能。网卡收包时将小包合并成大包,然后交给内核协议栈。LVS 内核模块在处理>MTU 的数据包时,会主动丢弃。
因此,如果我们用 LVS 来传输大文件的时候传输速度会极其慢。
/sbin/ethtool -k eth0 |grep offload查看 gro 是否打开,发现果然是打开的。
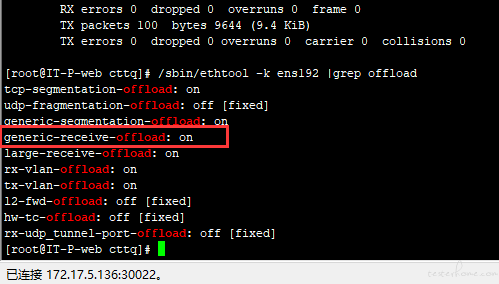
我的思路是,要么把 gro 关了,要么把 mtu 加大。考虑到机器还有别的用户,关闭 gro 可能会有其它影响,于是就决定把 mtu 放大到 4000
mtu 默认值是 1500

修改到 4000
echo "4000" > /sys/class/net/ens192/mtu
结果显而易见,请求过去了
最后就是万众瞩目的商业互吹环节了
问题的解决思路就在于日志,以及平时的一些经验积累,看到 gro 就想到了 mtu,继而就想到了可能是文件过大导致的切片失败
