去年的华为发布会,大家应该都听说了吧,这么受关注,主要是因为发布了万众期待的鸿蒙操作系统,不过随后就有人质疑它使用微内核的性能问题了。
话说我也是第一次听说微内核和宏内核的概念,不管是不是吹水吧,我算是长知识了。
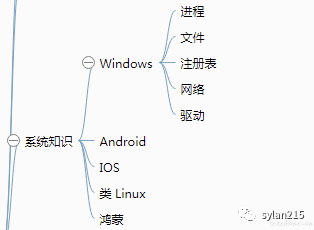
其实对于我们测试人员来说,掌握足够的系统知识一直都是很有必要的,可能深度上不要求专精吧,广度上有覆盖一样可以让测试用例覆盖率得到有效提升,不信?今天我就借助知识图谱之系统知识来说说我的看法。
知识图谱的前序系列文章,请点击如下链接回顾:
《软件测试经验图谱硬技能之测试技能》
《软件测试经验图谱硬技能之业务逻辑》
《再谈软件测试经验图谱》
《如何借助测试经验图谱完成三个月总结?》
下面是我写的系统知识部分的脑图(公众号后台回复「图谱」获取最新完整版):
下面我分别从两个角度来说明系统知识对于测试的作用。
一、系统知识是拿来用的,要输出
怎么理解这句话呢?我举一个例子你就明白了。
比如某次需求中有这么个逻辑「判断 Windows 系统版本是 Windows 10 就走最新逻辑 A,否则走老逻辑 B。」
逻辑看起来很简单,实现应该也很简单吧,if 判断下系统版本,然后走不同分支就行了。
但是,如果你对系统知识有了解的话就不会认为这么简单了。
首先,系统提供的 API 只是获取的数字版本号,并且还分为 MajorVersion、MinorVersion 和 BuildNumber 几个部分, 组合后的结果如 5.1.2600.256.1.3、6.1.7601、10.0 这种格式,代码需要进行二次处理才能得出我们所说的 Windows 10 系统。
其次,同样的 10.0 是包含了 Windows 10 和 Windows Server 2016 这两个系统的,如果不处理 Server 系统的话,还要判断是 WorkStation 才判为 Windows 10。
这还不算完,常用的获取系统版本号的 GetVersion API 在 Windows 8.1 之后会获取兼容模式的系统版本,所以尽量要求开发统一使用 RtlGetVersion 来获取真实版本号。
当然,如果考虑更周到一些,还有一些细节需要注意,比如开发使用的 == 10.0 来进行的判断,还是使用的 > 6.1 来判断,短期看没啥影响,也看不出来区别,可是长期看这就是所谓的深坑,所以推荐使用 == 10.0 来规避未知的风险。
还有一个更细节的逻辑是,最初版本的 Windows 10 的版本号是 6.2,这部分用户是否需要考虑。
如果不知道或者没有把这些系统知识应用上,我们的测试点可能就两条:

如果我们应用了这些系统知识的话,测试点就变成下面这样了:

是不是差别挺大?基础的测试点就算没做过测试的人也都能想到,但是深入的测试点就需要专业的人来考虑了。
能够充分合理的把系统知识应用到实际项目中,这就是咱们专业性的体现。
当然你也可以说,没考虑这些深入的测试点,短时间内也不会有任何问题,反正等到出问题的时候咱可能都不在公司了,到时候让别人去填坑好了,如果你真这么想,我只能说,道不同不相为谋。
上面仅仅是拿一个很常用的系统知识来举例,其实这样的例子还有很多。
比如进程相关的,我们要考虑是新建独立进程,还是直接使用多线程?独立进程是否允许进行虚拟内存切换?等等。
比如文件相关的,首先要考虑 IO 的问题,读取文件时,是否做的全文读取?大文件的全文读取那叫一个慢,即使是小文件也不建议频繁读取等等。
比如注册表相关的,需要考虑 HKCU 和 HKLM 的权限区别,需要了解几个常用注册表项的路径,需要考虑 services 项下各个 value 值的不同含义等等。
比如网络相关的,需要关注当前处理逻辑是在网络模型的哪一层,对系统和其他软件的最坏可能的影响,所有的网络处理都必须慎之又慎。
比如驱动相关的,就更应该非常谨慎了,要了解驱动的启动类型,要了解驱动的工作模式,要做好驱动异常的自动规避方式等等。
上面这些例子中,我都是以 Windows 系统为参考,其他的 Android、IOS、鸿蒙、类 Linux 系统应该也是类似的,适当调整分类方式即可。
二、系统知识的关键是体系化,要提炼
前面说的有点多了哈,因为系统知识在实际工作中的应用真的很重要,却又是很多人容易忽略的地方,特别是当大家把关注点都集中在需求上的时候,往往就只看到显式需求了。
下面我接着要说的是,如何在关注需求的同时,还能进行系统知识的提炼,从而在编写用例过程中有系统知识来辅助输出。
我目前了解到关于系统知识使用上的不足,主要是因为很多人没有区分开哪些是开发实现逻辑,哪些是系统知识。
比如前面那个获取系统版本的例子中,对 RtlGetVersion 结果进行处理,是本次代码实现逻辑,而对于 RtlGetVersion 本身是系统 API,对于系统 API 我们去查看 API 文档说明进行了解,基本不需要测试点覆盖,但是对于自己开发代码的实现逻辑却是需要充分的覆盖。
那么从经验积累的角度看,我们需要在了解完需求后,有意识的区分哪些是本次开发修改的逻辑,哪些是调用的系统接口。
不同的实现方式,对应不同的测试覆盖率的要求,需要挖掘的点和挖掘的方向也不同。
还是拿上面这个例子来说,如果只是按需求实现的角度去看,那么根本挖掘不到系统版本号的判断逻辑,也根本不会想着去了解 GetVersion 和 RtlGetVersion 的区别,也就不会有对应的测试点出来。
类似这样的知识点每个需求中都可以涉及很多,能不能把它们进行充分合理的提炼就是我们能力的体现了。
不过,也有很多人确实每次项目都进行了提炼,但是之后有新项目涉及类似的逻辑时,还是没有关联上,等到别人提醒,才会恍然大悟的说自己也知道这个点,问题是,如果知道的东西用不上,那和不知道有啥区别?
所以这里我要再强调一下体系化,就是我们吸收过来的系统知识,一定要分门别类的进行体系化的归纳总结。
体系化的好处是,等需要用到某个知识点的时候,可以极其方便快捷的按照固定路径进行知识的搜寻和提取。
其实和我们用脑图写测试点是一个道理,一个东西如果庞大到强记忆无法覆盖的程度,一定要进行体系化梳理。
当然,体系化不是目的,体系化之后的快速准确的输出才是目的。
以上,通过自己的实际经验,把测试过程中涉及的系统知识按照输入和输出两部分进行了简要说明,不知道你在实际项目中,涉及系统知识的地方多不多?是否有进行过系统知识和业务逻辑的分离?欢迎留言说说你的看法。
当然,如果你觉得自己有所收获,欢迎分享文章到朋友圈 + 点个「在看」让更多人看到,谢谢。
