
360 流程管理系统文件发布模块用于对安全卫士文件新上线发布和更新发布进行管控,开发、产品、测试等在该模块上提交发布申请,QA 根据此次发布的需求对提交的发布申请量进行再次审核和调整,最终由发布审批组审批申请确认发布。系统使用过程中发现创建发布申请时容易出现放量比率、对象、灰度值填写不合理的问题,这无疑增加了文件发布工作量,针对该痛点,我们利用已有的历史数据和 GBDT 算法构建了文件发布预测模型,描述不同文件发布的规律,对文件发布申请的放量比率、对象、灰度值进行预测,并将该模型转成服务,集成至已有的流程管理系统中,用于减少文件发布申请的工作量。
利用 sql 语句从数据库中将文件新上线发布申请和调量申请的历史数据捞取出来,构建数据集。通过观察发现数据集中有很多没有标签的脏数据,由于历史数据比较多,我们直接采用剔除的方式处理数据集中的脏数据。
数据集中每条数据由若干个字段组成,通过和发布审批组需求对接了解到不是所有的字段都对放量比率、对象、灰度值有影响,比如:文件的释放路径一般都是唯一的,用于标识文件存放路径,因此对文件发布申请的放量比率、对象、灰度值是没有影响的。因此我们需要筛选出真正对放量比率、对象、灰度值有影响的字段,这个过程中可以理解成特征选择,特征选择除了通过需求理解发现无效字段还可以利用随机森林算法实现。最终我们使用的特征字段有文件名、发布模式、目前量级、目前比率、目前 V5 条件、优先级,标签字段是放量比率、放量对象、灰度值。
由于机器学习算法只能处理数值类型的数据,因此需要对非数值类字段进行数值化,并对数值类字段进行量纲统一处理。对于数值类字段,以灰度值为例,有的单位是 w,有的单位是个,这个和提交申请发布的个人习惯有关,我们需要对其进行量纲统一,由于数据集大部分该字段取值都是 0,因此统一使用个做灰度量级。对于非数值类字段,如文件名,由于每个文件都是独立的,且不能通过文件名或者后缀名找到文件发布的联系,因此没有利用
embedding 编码,而是简单的用 unique 编码来标识每个文件名字段。
通过特征选择和处理得到最终的训练数据,通过需求理解知道文件放量对象、比率和灰度值大概分为若干个级别,而且训练数据中数据分布不均匀,因此我们采用效果比较好的集成学习算法梯度提升分类树算法训练模型。目前预测模型支持的发布方式有新上线和调量两种,由于新上线和调量的特征空间差异比较大,因此是分开训练的,而且每种方式预测的值分别是放量对象、比率和灰度值三种,比较特殊的是,放量比率不仅和特征空间中的特征有
关还受放量对象影响,灰度值除了受特征空间中的特征影响还和放量对象、比率有关,对于这类特殊问题,我们一种发布方式构建了三个模型。实际预测时,首先放量对象预测模型利用已有的特征得到预测放量对象,然后放量比率预测模型利用已有特征和预测放量对象得到放量比率预测值,最后放量灰度值预测模型利用已有特征和预测放量对象、比率得到预测的灰度值。因此总共构建了六个模型,构建模型的代码如下所示:
def train_and_test_online_datas_by_GBDT(datas, labels):
train_datas, test_datas, train_targets, test_targets, \
train_rates, test_rates, train_grays, test_grays = __split_train_test(datas, labels)
print test_datas[1], test_targets[1], test_rates[1], test_grays[1]
print "**************target***********************"
__train_datas = train_datas
__test_datas = test_datas
target_clf = GradientBoostingClassifier()
target_clf.fit(__train_datas, train_targets)
print target_clf.score(__train_datas, train_targets)
print target_clf.score(__test_datas, test_targets)
print "**************rate***********************"
train_datas = np.insert(train_datas, 1, values=train_targets, axis=1)
test_datas = np.insert(test_datas, 1, values=test_targets, axis=1)
__train_datas = train_datas
__test_datas = test_datas
rate_clf = GradientBoostingClassifier()
rate_clf.fit(__train_datas, train_rates)
print rate_clf.score(__train_datas, train_rates)
print rate_clf.score(__test_datas, test_rates)
print "**************gray***********************"
train_datas = np.insert(train_datas, 2, values=train_rates, axis=1)
test_datas = np.insert(test_datas, 2, values=test_rates, axis=1)
__train_datas = train_datas
__test_datas = test_datas
gray_clf = GradientBoostingClassifier()
gray_clf.fit(__train_datas, train_grays)
print gray_clf.score(__train_datas, train_grays)
print gray_clf.score(__test_datas, test_grays)
模型训练和测试后,需要转换成一种服务,集成到已有的流程管理系统中,我们使用 tornado 框架搭建 web 服务,提供 web 接口供流程管理系统调用,预测服务框架如下图所示,服务将处理过的请求加入缓存中,当有相同的请求无需等待模型预测快速也能返回预测结果,缓解模型接口压力。当数据库中积累了更多的数据后,一周在线更新一次模型,用于适应文件发布规律变化和增加新的文件发布规律,提高模型的鲁棒性,进一步提高文件发布申请效率。
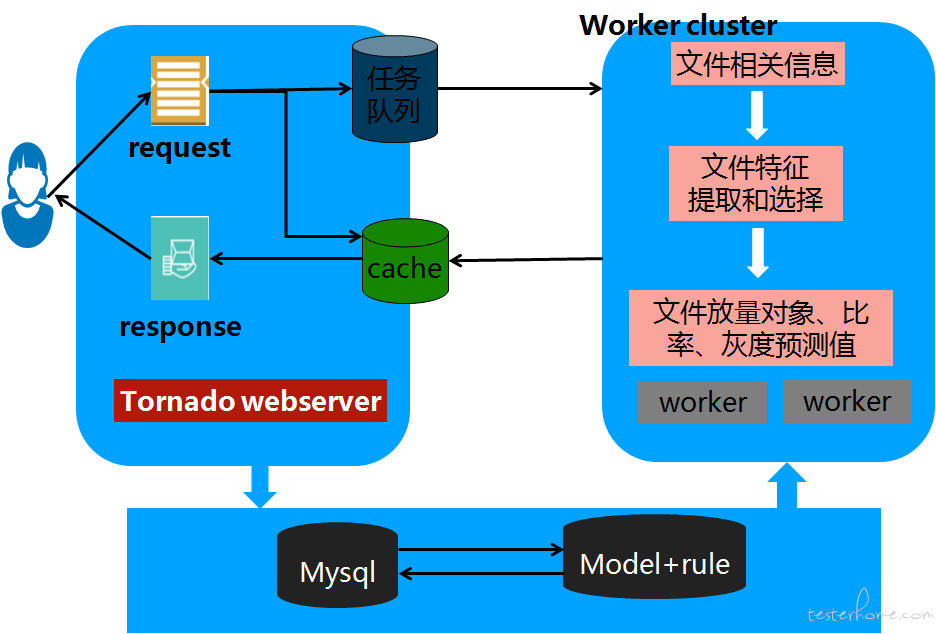
在实际使用过程中,线上可能会出现 bad case,即预测的结果不是用户想要的,对于这种情况,如果对线上使用影响比较大的话我们需要及时干预,干预方式可以是做些后处理,加些规则约束;也可以是构造一些满足用户需求的数据,及时更新和纠正线上模型。以我们遇到的一类 bad case 为例,对于已经全网更新的文件我们给出的预测放量对象可能是正式,这种对于用户来说是不符合实际逻辑的,正常逻辑下,文件放量对象应该满足的从 beta—>正式—>全网的一个递进的规律,通过分析发现训练集中正式和全网的界限不是很清晰,很多该写全网的之前历史数据中都是给的正式,由于历史数据的偏差,学习得到的模型很可能会出现从全网预测成正式这种情况,针对该问题,我们做了后处理,将正式纠正成全网,随着后边数据的积累,慢慢纠正模型。
所以当我们没有专家对已有数据进行标注和标签纠正的时候,我们可以利用已有的数据先构建出一个初始模型,也可以叫做打点模型,上线后出现 bad case,通过用户纠正或者规则干预等方式得到正确的标签,经过一段时间的数据积累,我们可以慢慢更新和纠正模型,提高模型预测能力。
