上一次介绍了混沌工程的一些基本原理和测试理念,今天让我们来看看实施混沌工程的其他要素。目前业界关于混沌工程的方案主要集中在故障注入的工具或平台上。 我见过的一些开源项目比如阿里的 chaos blade, jvm-sandbox 等故障注入工具便是以此为卖点。 QA 人员使用工具注入故障然后验证业务是否正常运行便是目前大多数混沌工程实践的方案。 只不过在产品业务和架构高速发展的今天,我们面临了一些新的问题。 今天就主要分析一下故障的隔离与注入相关的设计。
故障的隔离很重要,原因有二:
上面也说过,故障隔离的一个方案就是容器化,我再 docker 技术的帖子中曾经介绍过容器技术的原理。 其中有一种技术叫 linux namespace,即名称空间。 这是虚拟化技术用来做隔离性的关键。 之所以说每个 docker 容器之间在网络,进程等都是隔离的,关键就在于 docker 会为每个容器创建独立的网络名称空间,进程名称空间。 比如我们希望模拟一个服务无响应的故障那么就可以使用 iptables 命令进行模拟:iptables -D INPUT -p tcp --dport 80 -j DROP,这里面我们的目标服务启动在 80 端口, 这条命令会把所有发送到目标服务的请求全部丢弃,这样就造成了网络故障。 而由于 docker 为每个容器都分配了单独的网络名称空间,有独立的 Netfilter 表 (iptables 使用的是 Netfiter),它的网络环境是隔离的。 所以这个网络故障并不会对宿主机或者其他容器产生影响。 即便我们不小心把整个容器网络断掉也不会影响其他容器,大不了删了重新创建,即便因为操作失误玩坏了也没关系。
实际上容器化已经越来越流行,很多公司都开展了容器化实践并将应用部署在 k8s 中。像阿里,美团,京东都已经大规模应用容器化技术。我们公司也是如此。 所以讲解一下当产品容器化部署到 k8s 中的时候,我们是如何做故障注入的。
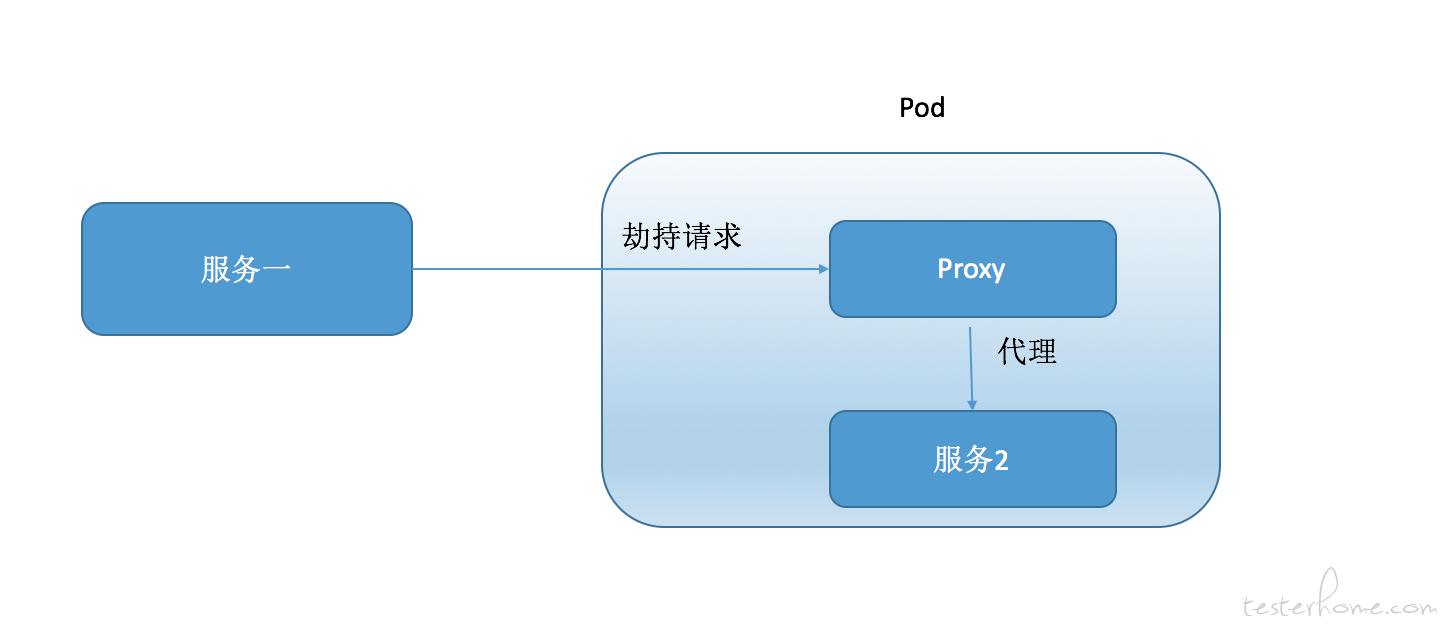
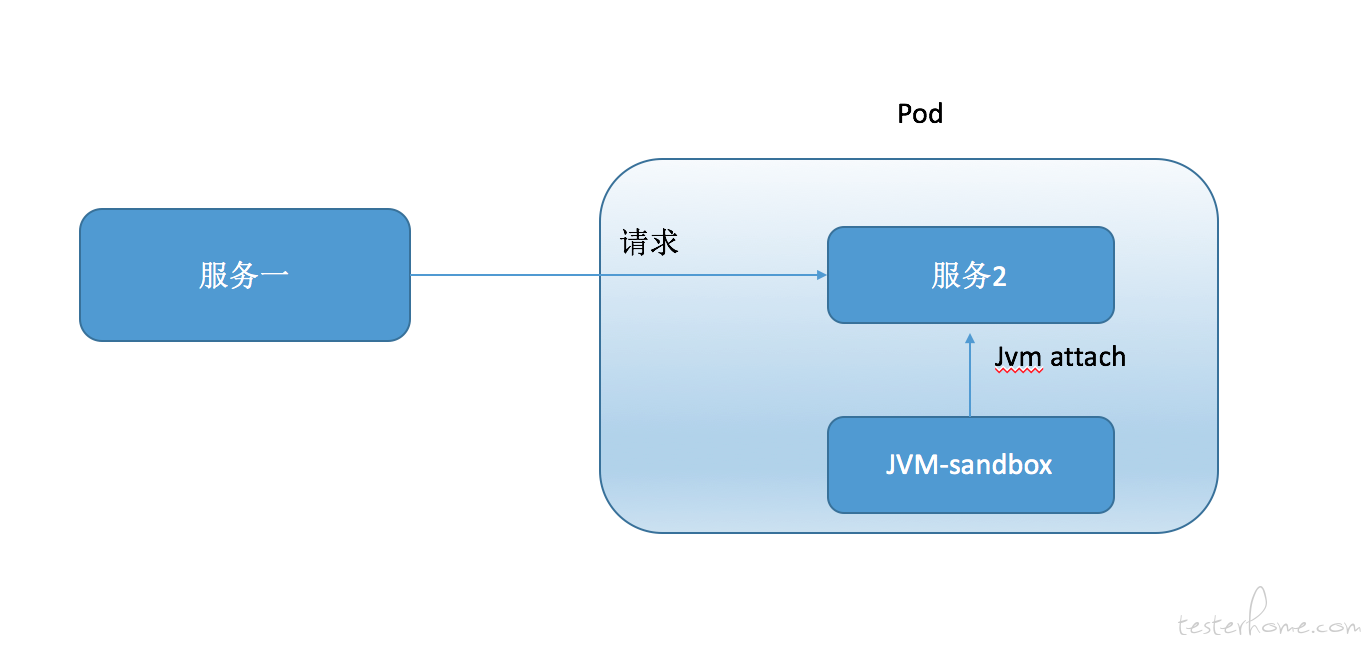
刚才我们说过向容器中注入一个网络异常其实是很容易的所以只需要在 k8s 针对 pod 的配置文件中增加 NET_ADMIN 的安全设置再运行 iptables 命令即可。但这只是比较简单的运维故障。 如果我们要注入一些复杂的故障,比如通过以 proxy 劫持目标服务篡改网络请求与响应的方式注入故障。这些复杂的故障注入方式需要目标容器有相应的环境,代码。 而这些测试用的依赖和代码是不会预设在业务镜像里的。所以我们使用如上图的方式,测试服务会修改 k8s 的配置,将故障容器以 sidecar 模式注入到业务 pod 中(PS: sidecar 模式的原理之前写过帖子:https://testerhome.com/articles/17752 ) 所有故障注入需要的依赖和代码都已经打入了镜像中,并且 proxy 会成为目标业务的代理,所以请求都会先经过 proxy。 PS:其实我们的 mock server 也是以这种形式启动的。 这里简单的介绍下 k8s 的机制, 我们之前说 docker 容器是每个容器都有一个独立的名称空间的,但是有一种情况例外,那就是容器之间以 container 网络模式连接后,连接的所有容器都共享同一个网络名称空间。 而 k8s 的 pod 中所有的容器就都是以这种网络模式相连。 也就是说一个 pod 中的所有容器都是共享同一个网络名称空间的。但是 pod 默认是不共享 pid 名称空间的, 如果要使用 jvm-sandbox 来注入字节码生成故障,是需要利用 java attach 的方式注入到目标进程中的。 所以这个时候需要使用 k8s 提供的 shareProcessNamespace=true 这个设置,来让 pod 内的容器共享 PID 名称空间。 这样就也同样可以使用 sidecar 模式注入故障了。 如下图:
如果没有使用 k8s 这类容器编排框架,也没有用应用容器化部署。那么故障的隔离,恢复和注入都会比较不容易。而且一定要小心翼翼的操作, 以免造成不可逆的故障或者是恢复起来太难导致拖慢测试进度。 举一个例子, 如果使用容器化部署,那么在部署时都会使用 limit 设置限制住容器能使用的 cpu 和内存上限。 那么针对 CPU 过载这个异常, 我只要在容器中注入一个命令:for i in seq 1 40; do dd if=/dev/zero of=/dev/null & done。 这条命令会使用 linux 自带的 dd 命令模拟 CPU 过载异常。 由于容器在启动时已经限制住了 CPU 的上限,所以我不必担心 cpu 过载过分了把宿主机压垮。 但是如果我们在没有使用容器化部署的时候,这条命令就很危险了。 有可能会直接搞挂你的机器。 所以这个时候就需要用到 cgroups 技术来限制你自己模拟异常的这个进程的 CPU 上限以免压垮主机。至于 cgroups 的用法我之前写过帖子:https://testerhome.com/articles/18471。 而模拟网络故障的时候要精确小心的运用 iptables 和 tc 命令,使用 iptables 命令的时候要精确影响的端口号 ,tc 命令要精确的将流量分组,保证只有固定分组收到 tc 的网络延迟故障的影响。 而恢复也需要更精确的命令, 不像之前在容器中注入故障,最不济的时候,恢复故障就就把容器删除然后重新创建就好了。 PS:容器其实限制 cpu 和内存的方式也是通过 cgroups 来限制的,只不过这部分由 docker 帮我们做好了。 详细的可以查看 docker 的文档, docker run 的时候可以指定参数,包括限制 CPU,内存,IO 等。
PS:如果是非容器化部署,故障注入方式可以选用阿里开源的 chaos blade。 我看过相关源码,隔离性已经做的不错, 模拟 cpu 过载的时候会添加 cgroups 作为限制, 模拟网络延迟的时候是使用了 tc 的流量分组来进行隔离的, 网络延迟不会影响其他应用。chaos blade 的使用方式也比较简单,后续有机会我再出一个教程来详细讲解。
今天先写到这吧,买了个新床到了, 得搬床了~~~ 下一次我们讲一下混沌工程的自动化实践要注意哪些东西。
