背景:
最近在测试组件在大容量环境下的健壮性,遇到了 OOM 问题,记录一次排查 OOM 的过程叭组件部署在 K8S 环境上,弹了五个 pod,每个 pod 当中跑了十个探针运行自己的业务,环境搭建好了过后,第一天观察没啥问题。第二天在早会上给领导汇报工作,目前大容量下,组件很健壮好叭。结果开完早会坐下来一看屏幕如下:
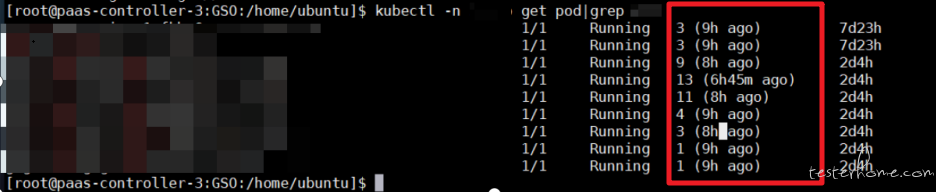
好好好,Pod 在昨晚疯狂重启,才汇报完工作就打脸,今天摸鱼时间无了。下面就来看看原因
排查过程:
1.先来看看目前组件内存占用,好家伙内存占用率 97%,离重启又不远了,进入到后台看看什么情况
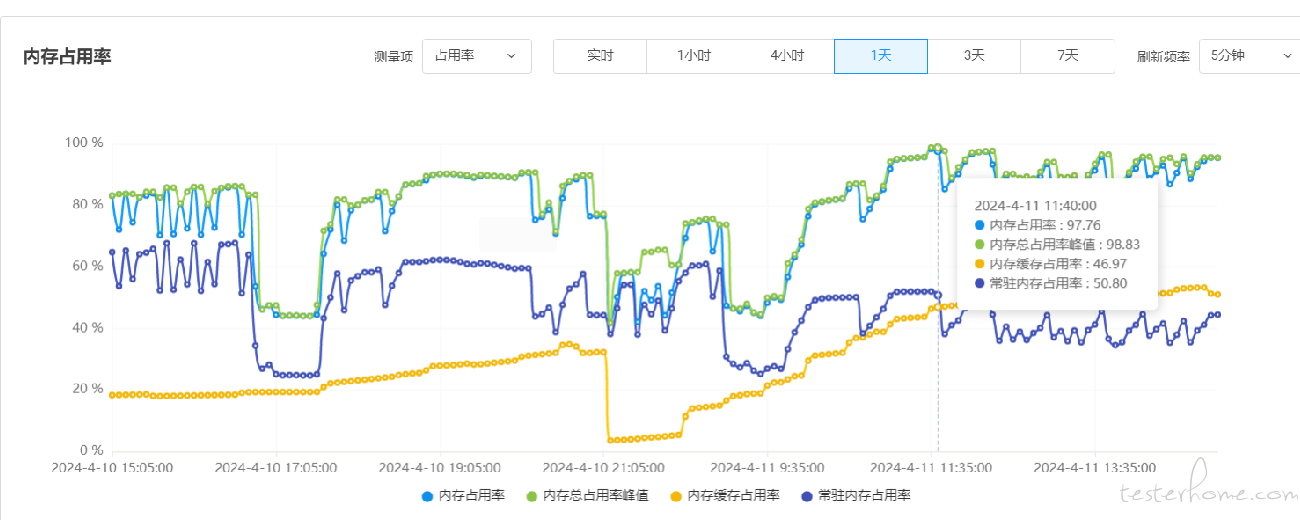
- 使用 kubectl(describe)命令或者 docker(inspect)命令查看容器状态,一般能得到重启原因,比如 OOMKilled,Error 等 如: kubectl -n [namespace] describe pod [容器 pod] 效果见下图

从图中可以看出是触发了 OOMKilled。很明显,问题的原因是因为容器配置的内存不满足实际运行的内存,大容量环境给出的资源规模是通过项目评估过的,一般来说不可能因为配置不够而导致 OOM,所以大概率还是因为代码写的不合理导致的,继续深入寻找线索。
2.借助于 java 自带的工具 jmap -histo pid,可以快速多次获取虚拟机堆中当前各对象的实例数量以及占用内存大小(这里随便找了张样例图参考),当时看到 char 对象占用了容器大部分内存,非常可疑。
3.继续查看堆内情况
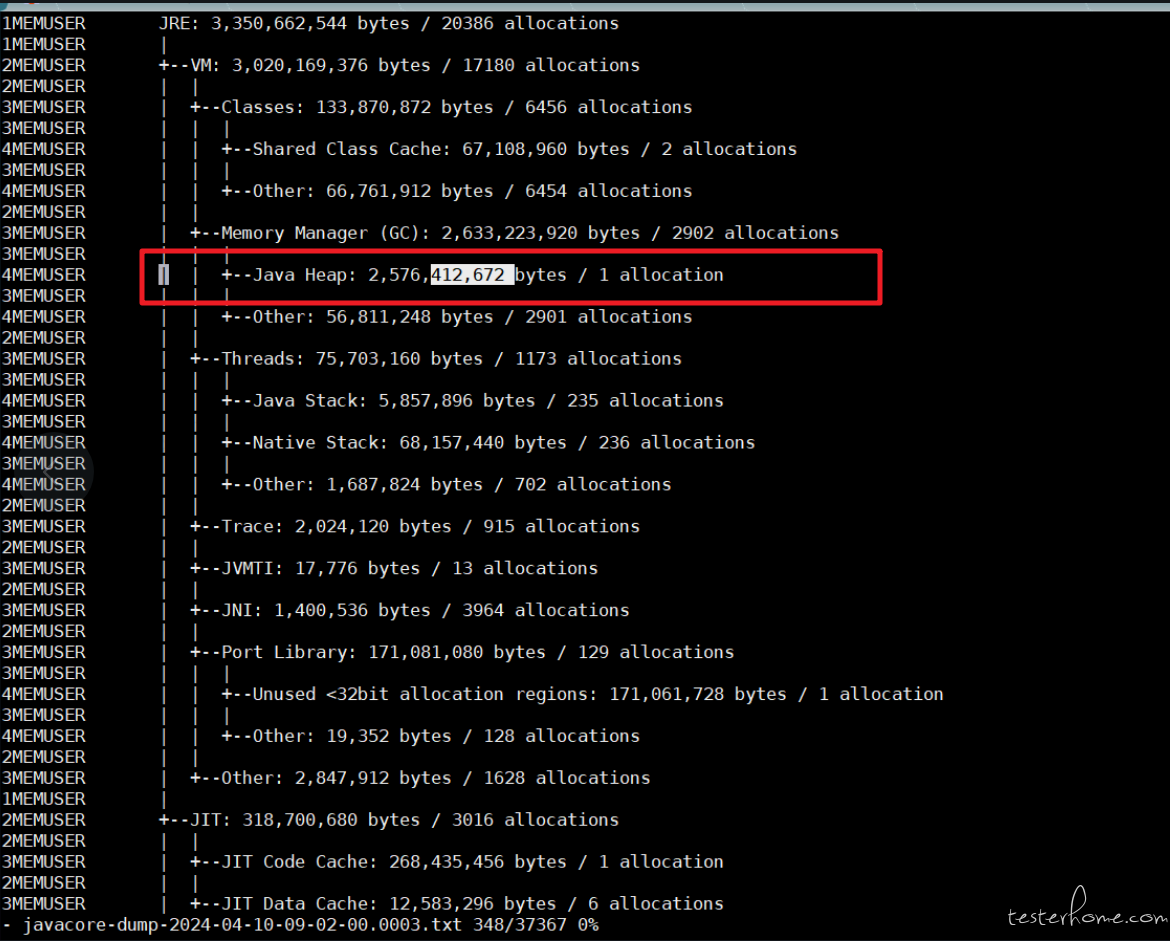
使用命令 kill -3 pid ,我们先分析 javacore.txt 文件
先看几处明显的信息
JVM 内存整体信息:
a.java 类占用了 133M
b.java 堆内存占用了 2576M
c.线程占用率 75M
d.JIT 占用率 318M
到目前位置,逐渐明朗,应该是 java 堆内存占用过多而导致 OOM。
补充一下:日常工作中容器重启原因有很多,比如类加载不合理占用过多内存导致重启、线程过多超过阈值导致重启、数据库导致的重启,以后遇到了再开文章分析。
4.把刚刚通过 kill -3 pid 命令生成的 phd 文件拉到本地,使用 JProfiler 打开 (phd 文件可以看堆具体的信息,包括对象等等)。
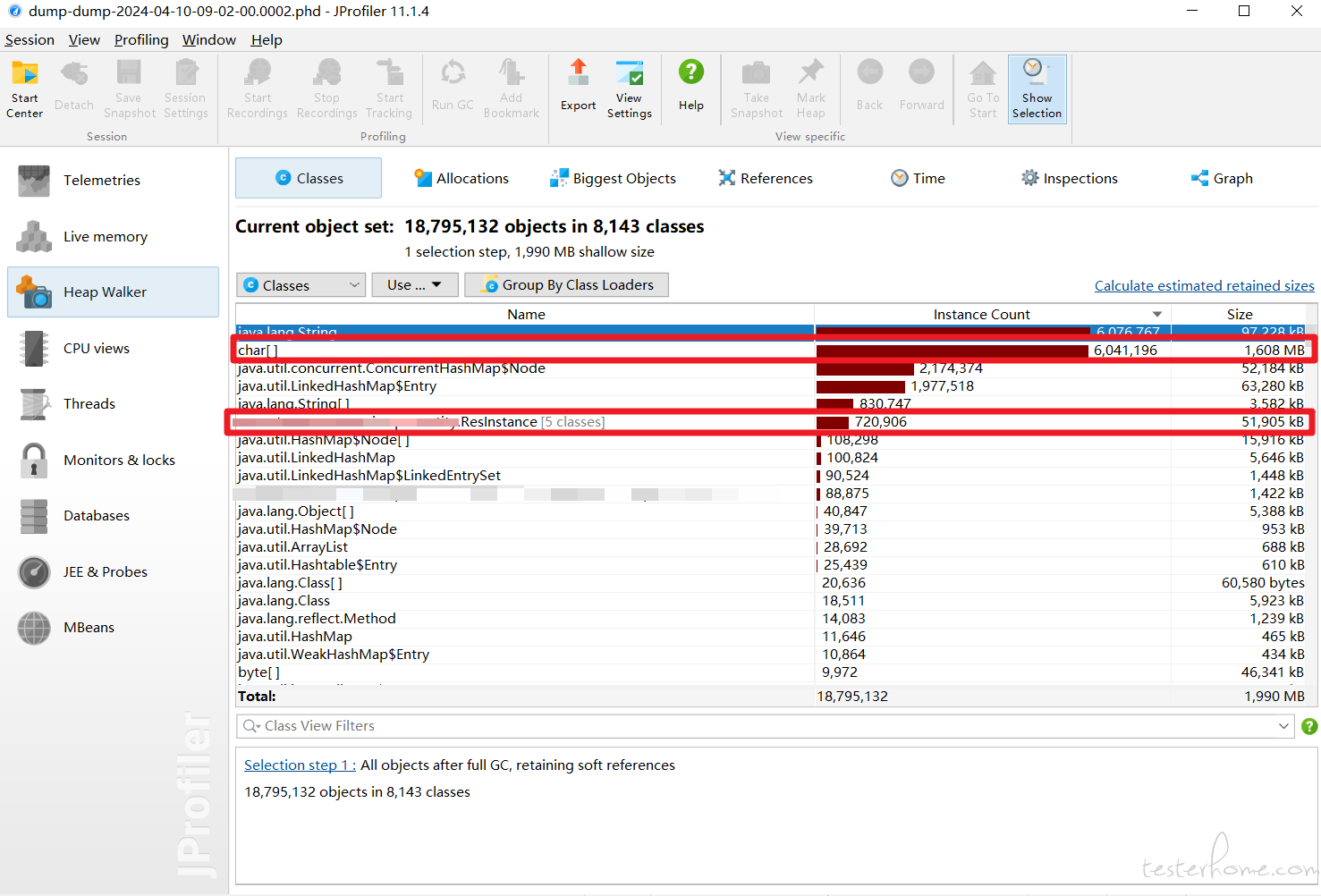
可以看到 char 对象实例一共有 600 万个,占用 1608MB 内存
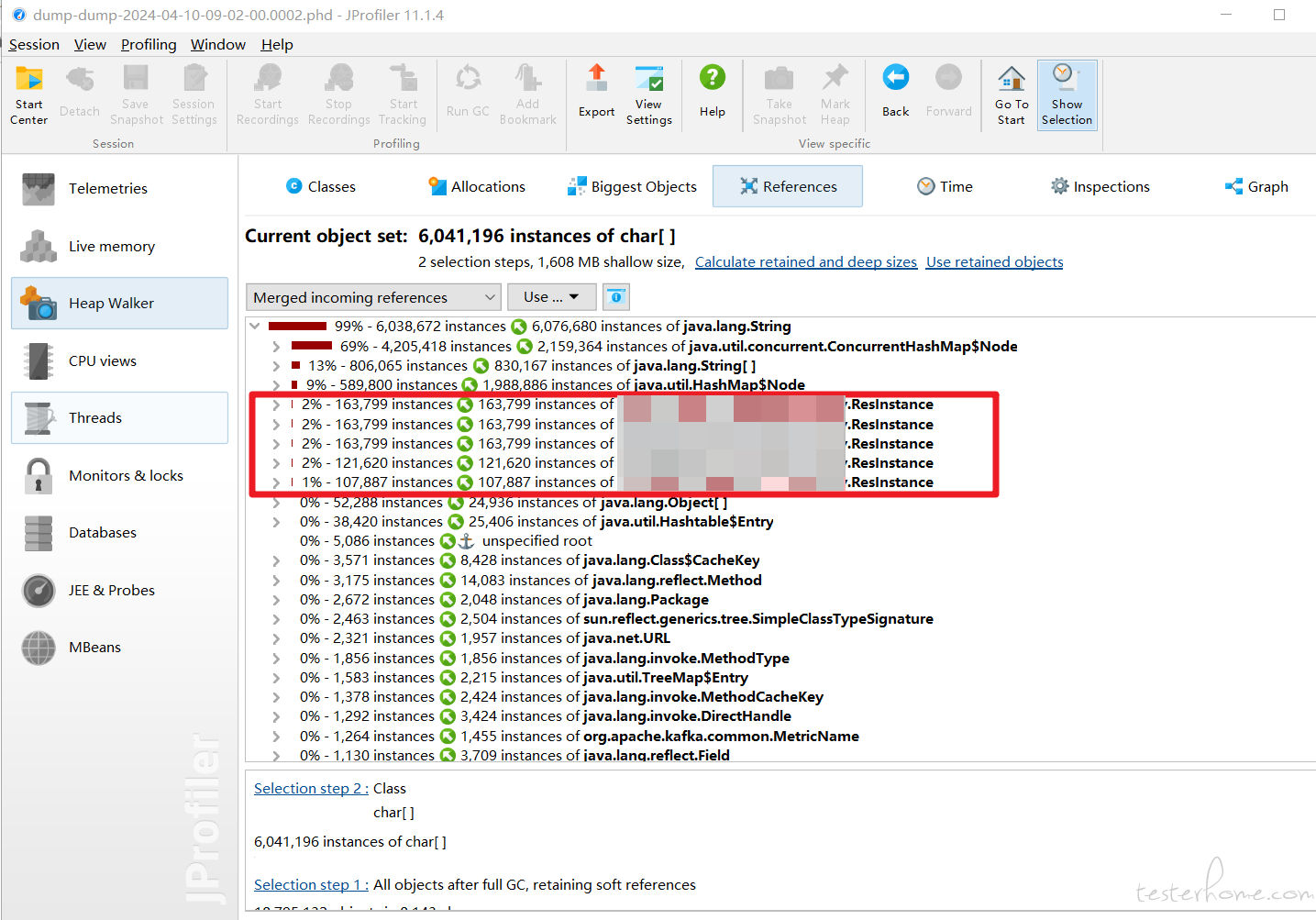
继续查看这些 char 对象被哪些对象与引用,发现大量 char 对象被 ResInstance 对象引用
那可以缩小范围了,问题就和 ResInstance 这个类有关
5.走查代码,发现 ResInstance 被 ResManager 所管理,ResManager 是一个单例,每一条资源数据映射成一个 ResInstance 对象,被 Manager 所管理。根据数据量计算,应该不会有这么大的数据量
继续查看 ResManager 代码,发现该类做了很多不同资源的缓存,有个资源调用接口写的方式很扎眼
请求为 POST 请求,但是过滤条件放在 uri 上面的,干了这么多年测试,还没遇到过这么写的。直觉告诉我可能这个过滤条件没有生效,下面来测试下。
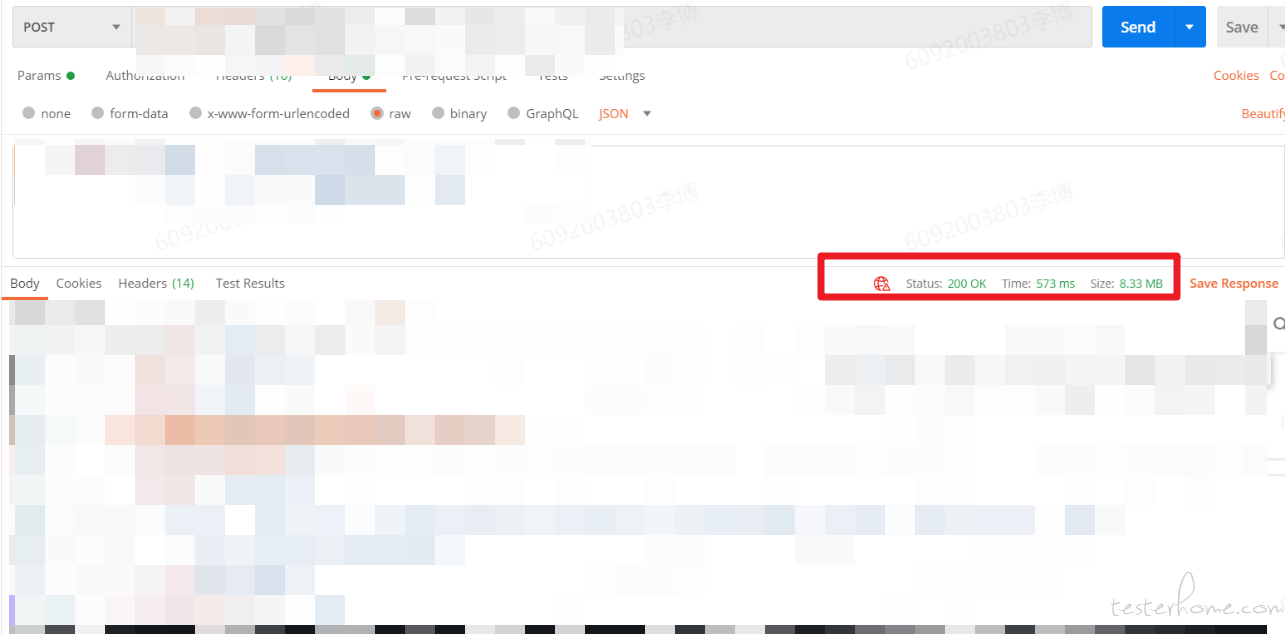
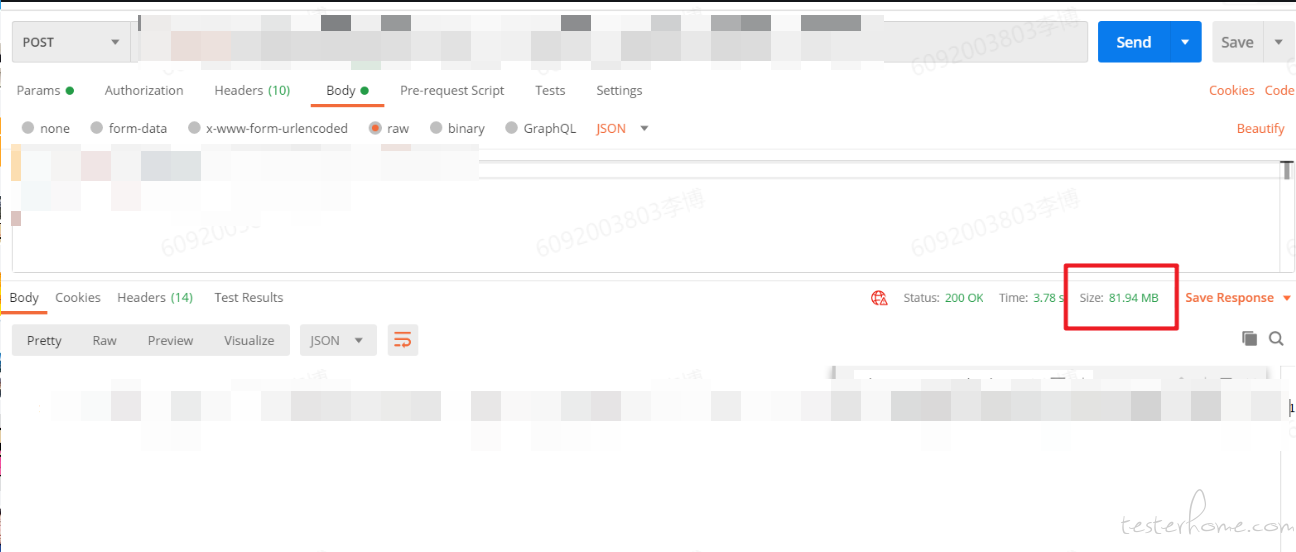
6.打开祖传 postman,使用代码中编写的方式调用,和把过滤条件放在 body 里面调用
好家伙,这一查把我 postman 都卡死了,只能看到总量 83M。把过滤条件放在 body 里查只有 8M。这一个探针数据量就多了十倍,十个探针多了 100 倍量。
7.让开发改了后,部署上去,内存终于正常了。
这个 OOM 问题排查整个流程如上,最近刷帖子看到很多人提到测试性能瓶颈啥的,不知道和我这个流程有没有相似之处 (没有干过专门的性能测试,来个懂哥说下,如果差不多,以后我也能说熟悉性能测试了 )。
)。
完结散花,感谢观看

