WeTest腾讯质量开发平台 从头到脚说单测——谈有效的单元测试(下篇)
导读
在《从头到脚说单测——谈有效的单元测试(上篇)》中主要介绍了:金字塔模型、为何要做单测、单测的阶段及指标,在下篇中我们主要介绍关于 mock、和如何不要滥用 mock、用例编写的策略等更多精彩内容,让我们赶紧来看一看吧~
七. 必须说一说 mock 了
test doubles
在《xUnit Test Patterns》一书中,作者首次提出 test doubles(测试替身)的概念。我们常挂在嘴边的 mock 只是其中一种,而且是最容易与 Stub(打桩)混淆的一种。在上一节中对 gomonkey 的介绍,你可以注意到了,我没有使用 mock,全部是 Stub。是的,gomonkey 不是 mock 工具,只是一个高级打桩的工具,适配了我们大部分的使用场景。
测试替身,共有五种:
·Dummy Object
用于传递给调用者但是永远不会被真实使用的对象,通常它们只是用来填满参数列表
·Test Stub
Stubs 通常用于在测试中提供封装好的响应,譬如有时候编程设定的并不会对所有的调用都进行响应。Stubs 也会记录下调用的记录,譬如一个 email gateway 就是一个很好的例子,它可以用来记录所有发送的信息或者它发送的信息的数目。简而言之,Stubs 一般是对一个真实对象的封装
·Test Spy
Test Spy 像一个间谍,安插在了 SUT 内部,专门负责将 SUT 内部的间接输出 (indirect outputs) 传到外部。它的特点是将内部的间接输出返回给测试案例,由测试案例进行验证,Test Spy 只负责获取内部情报,并把情报发出去,不负责验证情报的正确性
·Mock Object
针对设定好的调用方法与需要响应的参数封装出合适的对象
·Fake Object
Fake 对象常常与类的实现一起起作用,但是只是为了让其他程序能够正常运行,譬如内存数据库就是一个很好的例子。
stub 与 mock
打桩和 mock 应该是最容易混淆的,而且习惯上我们统一用 mock 去形容模拟返回的能力,习惯成自然,也就把 mock 常挂在嘴边了。
就我的理解,stub 可以理解为 mock 的子集,mock 更强大一些:
· mock 可以验证实现过程,验证某个函数是否被执行,被执行几次
· mock 可以依条件生效,比如传入特定参数,才会使 mock 效果生效
· mock 可以指定返回结果
· 当 mock 指定任何参数都返回固定的结果时,它等于 stub
只不过,go 的 mock 工具 gomock 只基于接口生效,不适合新闻、企鹅号项目,而 gomonkey 的 stub 覆盖了大部分的使用场景。
八. 不要滥用 mock
我把这一部分单独放一章节,表现出它重要的意义。需要读懂肖鹏的《mock 七宗罪》,在 gitchat 上。
两个门派
约从 2004-2005 年间,江湖上形成两大门派:经典测试驱动开发派 和 mockist(mock 极端派)。
先说 mockist。他主张将被测函数所有调用的外面函数,全部 mock。也即,只关注被测函数自己的一行行代码,只要调用其他函数,全都 mock 掉,用假数据来测试。
再说经典测试驱动开发派,他们主张不要滥用 mock,能不 mock 就不 mock,被测单元也不一定是具体的一个函数,可能是多个函数,串起来。必要的时候再 mock。
两个门派相争多年,理论各有利弊,至今仍然共存。存在即合理。比如 mockist,使用了过多的 mock,无法覆盖函数接口,这部分又是很容易出错的;经典派,串的太多,又被质疑是集成测试。
对于我们实际应用,不必强制遵从某一派,结合即可,需要的时候 mock,尽量少 mock,不用纠结。
什么时候适合 mock
如果一个对象具有以下特征,比较适合使用 mock 对象:
· 该对象提供非确定的结果(比如当前的时间或者当前的温度)
· 对象的某些状态难以创建或者重现(比如网络错误或者文件读写错误)
· 对象方法上的执行太慢(比如在测试开始之前初始化数据库)
· 该对象还不存在或者其行为可能发生变化(比如测试驱动开发中驱动创建新的类)
· 该对象必须包含一些专门为测试准备的数据或者方法(后者不适用于静态类型的语言,流行的 Mock 框架不能为对象添加新的方法。Stub 是可以的。)
因此,不要滥用 mock(stub),当被测方法中调用其他方法函数,第一反应应该走进去串起来,而不是从根部就 mock 掉了。
九. 用例设计法
看了一篇文章:像机器一样思考
文章讲述思考程序设计的根本思路——考虑输入输出。我们设计 case,想要得到最全面的设计,根本是考虑全输入全输出的组合,当然,一方面,这么做耗时太大,很多时候是不可执行的;一方面,这不是想要的结果,要考虑投入产出比。这时,需要理论与实践相结合,理论指导实践,实践精细理论。
先说理论
还是从上篇文章说起,考虑输入、输出,就要先知道哪些属于输入输出:

白盒&黑盒设计
白盒法:
·逻辑覆盖(语句、分支、条件、条件组合等)
·路径(全路径、最小线性无关路径)
·循环:结合 5 种场景(跳过循环、循环一次,循环最大次,循环 m 次命中、循环 m 次未命中)
黑盒法:
等价类:正确的,错误的(合法的,非法的)
边界法:[1,10] ==> 0,1,2,9,10,11(是等价类的有效补充)
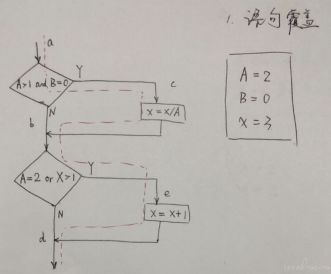
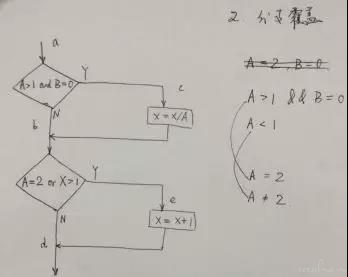
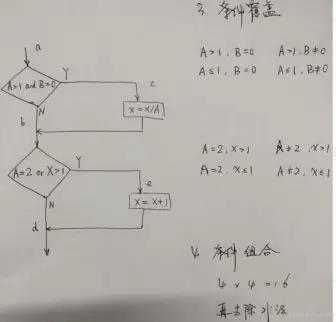
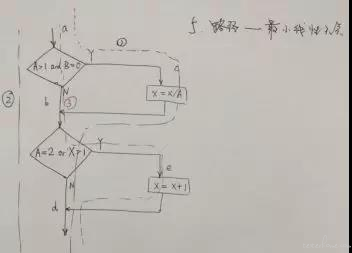
- 结合应用 全输入输出,实施难度较大,转而我们思考到业内大神们设计出白盒黑盒设计法,通过仔细思考,可以判断出是对全输入全输出的方法论体现。
因此,白盒&黑盒用例设计法,每一种我都亲自实践,理解其优缺点,从设计覆盖角度,条件组合>最小线性无关路径>条件>分支>语句。
下面这张图,是我早期思考用例设计时的一次实践,现在回忆起来,它过度设计了。
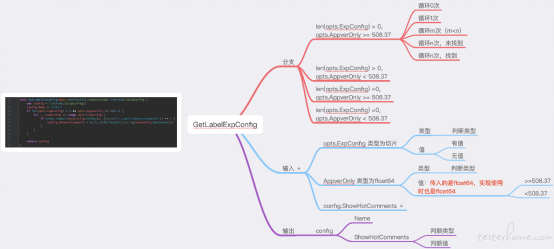
但实际中,我们担心 “过度设计”,也还无法给出答案 “用什么方法设计保证万无一失”。
·过度设计,也会使 case 脆弱
·在有限的时间内,我们寻求收益较大化
- 小函数&重要(计算,对象处理):尽量设计全面
- 逻辑较重,代码行数较多:分支、语句覆盖 + 循环 + 典型的边界处理(我们看个例子:GetUserGiftList)
- 引出 “基于实现” 与 “基于意图” 的设计:过多去 Stub 被测函数内部的调用,就越接近 “基于实现”(第二次提到 “基于意图”)
十. 基于意图与基于实现
这个话题是非常重要的。
基于意图:思考函数最终想做什么,把被测函数当做黑盒,考虑其输出输出,而不要关注其中间是怎样实现的,究竟生成了什么临时变量,循环了几次,有什么判断等。
基于实现:输入输出我也考虑,中间怎么实现的我也考虑。mock 就是一个好例子,比如我们写一个 case,我们会用 mock 去验证函数内是否调用了哪个外部方法、调用了几次,语句的执行顺序是怎样的。程序的变动比需求还快,重构随时都有,稍有一变,case 大批量失败,这也是《mock 七宗罪》中提到的一种情况。
我们要的是基于意图,远离基于实现。
结合实战经验,我总结如下:
- “要么写好,要么不写”。case 也是代码,也需要维护,也有工作量,所以要写的到位,而不是写得多。写了一堆没用的,你还得维护,不如删了。
- 拿到一个函数,先问问自己,这个函数要实现什么功能,最终输出是什么;然后,问自己,这个函数的风险在哪里,哪部分逻辑不太自信,最容易出错(计算、复杂的判断、某异常分支的命中等)。这些才是我们 case 要覆盖的点。
- 内联函数、直接 get/set,没几行没什么逻辑的,只要你判断没什么风险,就不用写 case。
- 确定了要写的 case,再用分支条件组合、边界等核心方面设计出具体用例,实施编写。 可以结合新闻几次单测 case review 记录,来详细理解。 我们看一个具体的 case:
- 拿到这个函数,作为测试同学的我先向开发了解该函数的意图:对符合格式、符合时间的用户礼物进行加和 2. 读代码,了解了代码流程、几个异常分支,先做了 code review 3. 根据必要的异常分支,设计 case 覆盖
- 对正常的业务流程,是按照开发讲述的函数意图,进行设计,case 如下:
被测函数

正常路径的单测 case
func TestNum_CorrectRet(t *testing.T) {
giftRecord := map[string] string{
"1:1000": "10",
"1:2001": "100",
"1:999": "20",
"2": "200",
"a": "30",
"2:1001": "20",
"2:999": "200",
}
expectRet := map[int] int{
1: 110,
2: 20,
}
var s *redis.xxx
patches := gomonkey.ApplyMethod(reflect.TypeOf(s), "Getxxx", func(_ *redis.xxx, _ string)(map[string] string, error) {
return giftRecord, nil
})
defer patches.Reset()
p := &StarData{xxx }
userStarNum, err := p.GetNum(10000)
assert.Nil(t, err)
assert.JSONEq(t, Calorie.StructToString(expectRet), Calorie.StructToString(userStarNum))
}
有同学会问到:但是你最终还是看的代码呀?看到代码的正确逻辑是怎么处理的,再去设计的 case 和构造数据吧?而且你不看代码,怎么知道有哪些异常分支要覆盖呢?
答:1. 我现在作为测试同学写开发同学的 case,确实需要知道有哪些异常分支要处理, 但不局限于代码中的几种,还应该包括我理解到的异常分支,都要体现在 case 中。我们的 case 绝不是为了证明代码是怎么实现的!通过单测,我们经常能够发现 bug。但是将来是开发来写单测的,他自己设计的函数肯定知道要覆盖哪些异常分支。
- 嗯,我需要看代码的正常流程是怎样的,但不代表着把代码扒下来以设计出 case。case 实际上是通过与开发的沟通后,了解输入数据的结构,输出的格式,数据校验和计算的过程,去设计输入输出的。
十一. 用例编写的策略
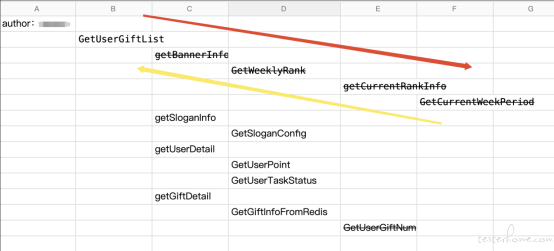
对于怎么个顺序去写单测,我们重点实践了一番,基本上也就三种情况吧:
·独立原子:mockist,被我们推翻了。当然,最底部的函数可能没有外部依赖,那单测它就够了。
·自上而下(红线):从入口函数往下测。实践的过程中,我发现很难执行,因为我从入口处就要想好每一次调用都需要返回哪些数据及格式,串起来一个 case 已经非常不易。
·自下而上 (黄线):我们发现,入口函数,往往没什么逻辑,调用另一个函数然后拿到响应返回。所以入口函数,也许不用写?我们继续往下看,每一次调用的函数都看,也调出了以往的线上线下 bug,我们发现出现问题的代码部分往往是调用链的底端,尤其是涉及计算、复杂分支循环等。而且,底端的函数往往可测性较好。
因此,考虑两方面,我们选择自下而上设计来选择函数编写 case:
1. 底部的函数可测性通常很好
- 核心逻辑比较多,尤其涉及计算、拼接,分支的。
十二. 可测性问题的解决——重构
导致无法写单测的重要原因是,代码可测性不好。如果一个函数八九十行、二三百行,基本就是不可测的,或者说 “不好测的”。因为里面逻辑太多了,从第一行到最后一行都经历了什么,各种函数调用外部依赖,各种 if/for,各种异常分支处理,写一个 case 的代码行数可能是原函数的几倍。
因此,推动单测走下去,重构提升可测性是必须环节。而且,通过重构,代码结构间接清晰了,更可读可维护,更容易发现和定位问题。
常见的问题:重复代码、魔法数字、箭头式的代码等
推荐的理论书籍是《重构:改善既有代码的设计》第二版、《clean code》
我输出了一篇关于重构的文章。
使用 codecc(腾讯代码检查中心)的圈复杂度、函数长度来评估代码结构质量,我们与开发一起学习,一起实践,不断有成果输出。
对于箭头式的代码,可考虑如下步骤:
1. 多使用卫语句,先判断异常,异常 return
2. 将判断语句抽离
3. 将核心部分抽离为函数
十三. 用例维护,可读性、可维护性、可信赖性
用例设计要素
·将内部逻辑与外部请求分开测试
·对服务边界(interface)的输入和输出进行严格验证
·用断言来代替原生的报错函数
·避免随机结果
·尽量避免断言时间的结果
·适时使用 setup 和 teardown
·测试用例之间相互隔离,不要相互影响
·原子性,所有的测试只有两种结果:成功和失败
·避免测试中的逻辑,即不该包含 if、switch、for、while 等
·不要保护起来,try…catch…
·每个用例只测试一个关注点
·少用 sleep,延缓测试时长的行为都是不健康的
·3A 策略:arrange,action,assert
用例可读性
· 标题要明确表明意图,如 Test+ 被测函数名 +condition+result。case 失败后,通过名字就知道哪个场景失败,而不用一行行再读代码。将来维护这个测试代码的,可能是其他人,我们需要让别人容易读懂
·测试代码的内容要清晰,3A 原则:arrange,action,assert 分成三部分。数据准备部分 arrange 如果代码行较多,考虑抽离出去。
·断言的意图明显,可以考虑将魔法数字变为变量,命名通俗易通
·一个 case,不要做过多的 assert,要专一
·和业务代码的要求一致,都要可读
用例可维护性
·重复:文本字符串重复、结构重复、语义重复
·拒绝硬编码
·基于意图的设计。不要因为业务代码重构一次,就导致一批 case 失败
·注意代码的各种坏味道,可参见《重构》第二版
用例可信赖性
单元测试,小而且运行快,它不是为了发现本次的 bug,更是为了放在流水线上 努力发现每一次 MR 是否产生了 bug。单测运行失败,唯一的原因只应该是出现 bug,而不是因为外部依赖不稳定、基于实现的涉及等,长期的失败将失去单元测试的警示作用,“狼来了” 的故事是惨痛的教训。
·非被测程序缺陷,随机失败的 case
·永不失败的 case
·没有 assert 的 case
·名不副实的 case
十四. 新闻单元测试的推动过程
我们提到,对单元测试的实践分为 4 个阶段,每阶段均有目标。
第一阶段 会写,全员写,不要求写好
·由上而下的推动,从总监到组长,极力支持,毫无犹豫,使组员情绪高涨
·快速确定单测框架,熟练使用
·结合开发需求,输出各场景下 单测框架的使用方法,包括 assert、mock,table-driven 等
·封装 http2WebContext,方便生成 context 对象
·多次培训,讲解单测理论及框架使用
·各团队(终端、接入层)指定单测接口人,由他先尝螃蟹。他是最熟悉框架使用,在前期写最多 case 的人
·在磨合好单测框架的集成使用后,启动会,部分同学先试点使用,确保连续两个迭代,这几个同学都有 case 输出
·每个迭代总结数据中,加入单测相关数据:组长和总监非常关注单测数据信息,针对性鼓励提升 case 数量和代码行数

第二阶段 写好,有效,全员写
· 测试同学探索出 mock 的正确使用方法、用例设计的正确思路,分享给团队,经过探讨达成一致
· 结对编程,每迭代结对 2-3 个开发,共同写 case,互相提升。
这里的结对是灵活的:有的开发,只需用半天的时间给他讲框架使用,同他练习,他就可以上手了不需要再担心;有的开发,会分给测试同学需求,测试同学写完 case 后,开发 review 学习,并尝试写出自己的第一个 case;有的开发,一开始可能不太接受,以需求不适合单测为理由,观察了一段时间,他发现其他人都写了,也没那么难,对团队也有利,他甚至会主动找到测试同学教他写 case。
·测试同学对开发提交的 case 进行 review,跟进开发修改后重新 MR
·连续两个迭代,邀请 dot 老师、乔帮主进行 case review,效果非常好
·对迭代的单测数据分析,关注需求覆盖度、人员覆盖度,case 增量
·组长持续鼓励支持单测
·每迭代的需求增加 “单元测试” 字段,由组长评估后置位。不带单测的 MR 不予通过,单测也要被 review
第三阶段 可测性提升
·测试和开发共同学习《重构》第二版,每周有分享会
·某些骨干同学优先重构自己的代码
·测试同学严格要求,先保证有单测,然后小步重构,每一步均有单测保障
·通过流水线的 codecc 扫描,圈复杂度和函数长度必须达标,不可人工干预其通过
第四阶段 TDD
·先不保证开发同学做到 TDD,门槛还是挺高的,而且需要在线下熟练之后再运用到业务开发中
·逐步推动开发将业务代码和测试代码同步编写,而不是完成业务代码后再补 case
·测试同学练成 TDD
十五. 流水线
单测要放在流水线上跑,客户端和后台都配好了流水线,保证每次 push 和 MR 都运行一次,发报告。
对于 go 的单测,新闻接入层各模块是通过 MakeFile 来编译,因为要导入一些环境变量,所以我将 go test 集成在 MakeFile 中,执行 make test 即可运行该模块下所有的测试用例。
GO = go
CGO_LDFLAGS = xxx
CGO_LDFLAGS += xxx
CGO_LDFLAGS += xxx
CGO_LDFLAGS += xxx
TARGET =aaa
export CGO_LDFLAGS
all:$(TARGET)
$(TARGET): main.go
$(GO) build -o $@ $^
test:
CFLAGS=-g
export CFLAGS
$(GO) test $(M) -v -gcflags=all=-l -coverpkg=./... -coverprofile=test.out ./...
clean:
rm -f $(TARGET)
注:上述做法,只能生成被测试的代码文件的覆盖率,无法拿到未被测试覆盖率情况。可以在根目录建一个空的测试文件,就能解决这个问题,拿到全量代码覆盖率。
//main_test.go
package main
import (
"fmt"
"testing"
)
func TestNothing(t *testing.T) {
fmt.Println("ok")
}
流水线加上流程
cd ${WORKSPACE} 可进入当前工作空间目录
export GOPATH=${WORKSPACE}/xxx
pwd
echo "====================work space"
echo ${WORKSPACE}
cd ${GOPATH}/src
for file in ls:
do
if [ -d $file ]
then
if [[ "$file" == "a" ]] || [[ "$file" == "b" ]] || [[ "$file" == "c" ]] || [[ "$file" == "d" ]]
then
echo $file
echo ${GOPATH}"/src/"$file
cp -r ${GOPATH}/src/tools/qatesting/main_test.go ${GOPATH}/src/$file"/."
cd ${GOPATH}/src/$file
make test
cd ..
fi
fi
done
附录. 资料
·《测试驱动开发》
·《单元测试的艺术》
·《有效的单元测试》
·《重构,改善既有代码的设计》
·《修改代码的艺术》
·《测试驱动开发的三项修炼》
·《xUnit Test Patterns》
·mock 七宗罪
关注腾讯 WeTest,了解更多热门测试产品:wetest.qq.com