阿里云 云原生应用研发平台 EMAS 李嘉华(千瞬)
前言
性能测试在移动测试领域一直是一个大难题,它最直观的表现是用户在前台使用 App 时的主观体验,然而决定体验优劣的背后,涉及到了许许多多的技术变迁。
- 当我们习惯于诺基亚时,智能机出现了;当我们学会 native 开发时,hybrid 来了;当各种 hybrid 框架下的巨型应用倾向成熟时,小程序出现在了我们眼前;紧接着直播、iot、ar、vr、人工智能,新的技术与应用场景正在以无法想象的速度向前发展。性能测试技术在快速变化的场景与开发技术面前,面临着巨大的挑战,当我们还在纠结如何测试 a 时,b 就已经出来了。
- 性能测试本身,有发展日渐成熟的解决方案,如线上性能监控 APM、线下性能采集工具;有基于各个应用场景衍生的测试技术,如压力测试、稳定性测试、功耗测试等;也有基于各项性能指标(内存、cpu、电量、流量)而来的各种专项测试能力。
我们致力于打造线上线下一体的性能解决方案,希望能够帮助开发者发现、定位与解决一系列移动端性能问题。本文将着重介绍 EMAS 性能测试平台的能力与规划,还是那句话:功能决定现在,性能决定未来。
通常我们在采集 Android 设备性能数据时,都是通过 adb shell 获取各项系统数据,对采集效率、数据准确度等影响很大。阿里云移动测试做了大量技术优化创新,目前性能测试采集间隔为 1s,并且同时做到了无侵入、低延迟、低功耗。
在介绍技术方案之前,这里将本文的方案(app_process)与 adb shell 的方案做一组简单的数据对比。
- 采集的所有性能数据为:cpu、memory、fps、network
- 开发环境: java + ddmlib
- 测试电脑:MacBook Pro (Retina, 15-inch, Mid 2015) 上进行测试
- 测试设备:OPPO R17/Android 8.0
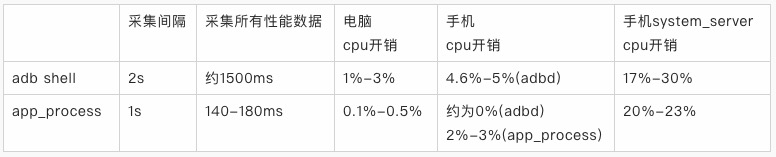
尽管对比的样本数不多,且不同实现方式也会有些许差异,但基于 app_process 的性能采集方案依然有很明显的优势:
- 性能数据误差更小。相比之下性能与精度的提升是显而易见的,在部分手机上 app_process 的 cpu 开销甚至低于 1%;
- 数据采集更及时、响应更快。由于 app_process 接口的高效性,我们在每一秒钟都会监控被测应用的 pid,实际上性能数据对 APP 重启等动作的响应是实时的;
- 兼容性更好。ps、top 等命令在不同的设备上可能存在数据格式上的差异,这类不同机型的适配问题在本文方案中是不存在的。
1. APP_PROCESS
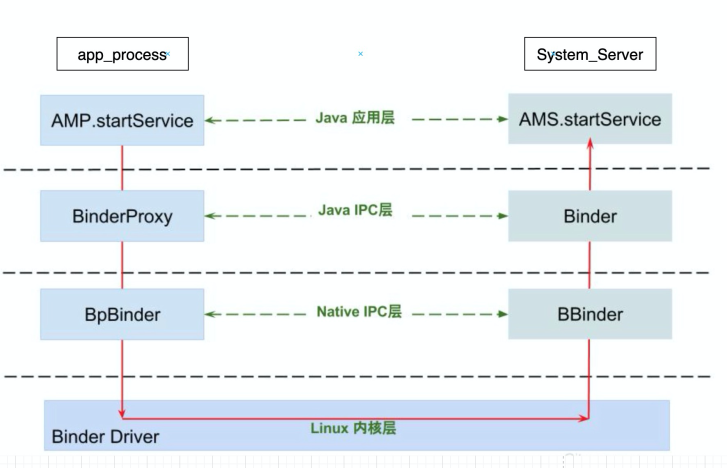
在 Android 系统中,zygote 通过 fork() 调用一个 app_process 进程作为 App 的载体,我们同样也可以通过 app_process 运行一个普通的 java 程序,这个 java 程序可以像 App 一样通过 binder 跨进程与 system_server 通信,实现并调用一些 Android 系统服务的接口,同时,通过 app_process 启动的程序拥有 shell 等同的权限,这样可以完成一些 app 无权限但是 adb 能够完成的命令。
通过下图我们简单理解一下 Android Binder 与本文的基本原理,更多细节可以自行搜索学习。通常来说,如果我们的 App 能够获取到一个 Manager(如 ActivityManager),那么 System_Server 中必然存在对应的 Service(如 ActivityManagerService),那么我们就可以通过 ActivityManagerProxy 与它通信。
2. 性能指标
目前 移动测试 性能测试平台支持采集的性能指标如下:
2.1 内存
指标说明
- TotalPss: 应用实际占用物理内存
- NativePss: native 进程申请分配的物理内存
- SwapPss: 动态内存交换区,zRAM 交换可通过压缩内存页面并将其放入动态分配的内存交换区来增加系统中的可用内存量。由于这是以牺牲 CPU 时间为代价来增加少量内存,所以 swapPss 的异常变化可能对系统性能造成影响。(https://source.android.com/devices/tech/config/low-ram.html)
原理
通过 adb shell dumpsys meminfo pid,我们可以获得如下内容
Applications Memory Usage (in Kilobytes):
Uptime: 543447125 Realtime: 543469686
** MEMINFO in pid 23178 [com.huawei.browser:sandboxed_process0:com.huawei.browser.sandbox.SandboxedProcessService0:6] **
Pss Private Private SwapPss Heap Heap Heap
Total Dirty Clean Dirty Size Alloc Free
------ ------ ------ ------ ------ ------ ------
Native Heap 99 96 0 2028 6656 4327 2328
Dalvik Heap 4 0 0 754 3078 1030 2048
Dalvik Other 4 4 0 366
Stack 8 8 0 26
Other dev 4 0 4 0
.so mmap 535 4 0 319
.jar mmap 114 0 0 0
.apk mmap 2 0 0 0
.dex mmap 622 0 4 2617
.oat mmap 409 0 0 0
.art mmap 259 16 0 2183
Other mmap 14 0 0 6
Unknown 28 28 0 455
TOTAL 10856 156 8 8754 9734 5357 4376
App Summary
Pss(KB)
------
Java Heap: 16
Native Heap: 96
Code: 8
Stack: 8
Graphics: 0
Private Other: 36
System: 10692
TOTAL: 10856 TOTAL SWAP PSS: 8754
在 Android 10 以下的设备中,我们可以通过 activityManager.getProcessMemoryInfo(pids) 获取进程相关的内存信息,Android 10 之后的系统对这个接口加了一些限制,数据更新时间为 5 分钟,需要直接调用 meminfo service 来 dump 获取这部分内容。
2.2 CPU
指标说明
ProcessCpu:测试进程 CPU 使用率
SystemCpu:整机 CPU 使用率
原理
通过读取/proc/stat 文件,我们可以看到下面的内容
cpu 2490696 175785 2873834 17973539 12823 680472 230184 0 0 0
cpu0 621631 33199 739364 12893642 10736 365458 86720 0 0 0
cpu1 623944 30576 688904 677748 609 145744 93230 0 0 0
cpu2 519768 33948 650022 685194 703 78117 23873 0 0 0
cpu3 499978 33082 547153 687802 650 81072 21360 0 0 0
cpu4 32586 4853 41910 774975 36 2097 1025 0 0 0
cpu5 30950 5003 40730 776693 19 2060 999 0 0 0
cpu6 99227 22708 109219 722048 23 3970 2140 0 0 0
cpu7 62610 12414 56531 755434 44 1952 836 0 0 0
intr 209333749 0 0 0 0 35952688 0 11796562 7 5 5 17537 80 2431 0 0 0 1069962 0 35 1334360 0 0 0 0 0 11 11 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 34984538 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 505 50695 1174791 345 0 0 0 11301652 24660 0 111 0 0 0 0 0 0 0 0 0 0 0 86153 54 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1099230 0 18 1814 0 0 23 514624 1300943 248469 0 0 0 0 0 97168 60709 1641967 609754 38618 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 519 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1556 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 18 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 5 0 0 0 3548401 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 18 0 0 163911 192365 0 0 0 0 1018 0 1 0 2 0 2 0 2 1 0 0 2 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 56891 4227 147 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 751521 0 0 200 0 0 0 0 0 0 0 0 0 0 0 0 0 27 26 26 0 34 50 330 34 0 0 0 0 0 0 0 0 1223 0 11 0 0 0 26
对于上述 cpu 数据来说,每行 CPU 的数字依次表示
user (14624) 从系统启动开始累计到当前时刻,处于用户态的运行时间
nice (771) 从系统启动开始累计到当前时刻
system (8484) 从系统启动开始累计到当前时刻,处于核心态的运行时间
idle (283052) 从系统启动开始累计到当前时刻,除IO等待时间以外的其它等待时间
iowait (0) 从系统启动开始累计到当前时刻,IO等待时间
irq (0) 从系统启动开始累计到当前时刻,硬中断时间
softirq (62) 从系统启动开始累计到当前时刻,软中断时间
- 我们可以得到 cpu 运行时长为 cpu = user + nice + system + iowait + irq + softirq,而总时长为 cpu_total = cpu + idle
- 由于我们的采集间隔几乎等于 1s,于是过去 1s 的设备整体 cpu 使用率为 (cpu - cpu_pre) / (cpu_total - cpu_total_pre)
通过读取/proc/pid/stat 文件,我们可以看到下面的内容
6873 (a.out) R 6723 6873 6723 34819 6873 8388608 77 0 0 0 41958 31 0 0 25 0 3 0 5882654 1409024 56 4294967295 134512640 134513720 3215579040 0 2097798 0 0 0 0 0 0 0 17 0 0 0
这里数据较多,依次表示
pid=6873 进程(包括轻量级进程,即线程)号
comm=a.out 应用程序或命令的名字
task_state=R 任务的状态,R:runnign, S:sleeping (TASK_INTERRUPTIBLE), D:disk sleep (TASK_UNINTERRUPTIBLE), T: stopped, T:tracing stop,Z:zombie, X:dead
ppid=6723 父进程ID
pgid=6873 线程组号
sid=6723 c该任务所在的会话组ID
tty_nr=34819(pts/3) 该任务的tty终端的设备号,INT(34817/256)=主设备号,(34817-主设备号)=次设备号
tty_pgrp=6873 终端的进程组号,当前运行在该任务所在终端的前台任务(包括shell 应用程序)的PID。
task->flags=8388608 进程标志位,查看该任务的特性
min_flt=77 该任务不需要从硬盘拷数据而发生的缺页(次缺页)的次数
cmin_flt=0 累计的该任务的所有的waited-for进程曾经发生的次缺页的次数目
maj_flt=0 该任务需要从硬盘拷数据而发生的缺页(主缺页)的次数
cmaj_flt=0 累计的该任务的所有的waited-for进程曾经发生的主缺页的次数目
utime=41958 该任务在用户态运行的时间,单位为jiffies
stime=31 该任务在核心态运行的时间,单位为jiffies
cutime=0 累计的该任务的所有的waited-for进程曾经在用户态运行的时间,单位为jiffies
cstime=0 累计的该任务的所有的waited-for进程曾经在核心态运行的时间,单位为jiffies
priority=25 任务的动态优先级
nice=0 任务的静态优先级
num_threads=3 该任务所在的线程组里线程的个数
it_real_value=0 由于计时间隔导致的下一个 SIGALRM 发送进程的时延,以 jiffy 为单位.
start_time=5882654 该任务启动的时间,单位为jiffies
vsize=1409024(page) 该任务的虚拟地址空间大小
rss=56(page) 该任务当前驻留物理地址空间的大小
Number of pages the process has in real memory,minu 3 for administrative purpose.
这些页可能用于代码,数据和栈。
rlim=4294967295(bytes) 该任务能驻留物理地址空间的最大值
start_code=134512640 该任务在虚拟地址空间的代码段的起始地址
end_code=134513720 该任务在虚拟地址空间的代码段的结束地址
start_stack=3215579040 该任务在虚拟地址空间的栈的结束地址
kstkesp=0 esp(32 位堆栈指针) 的当前值, 与在进程的内核堆栈页得到的一致.
kstkeip=2097798 指向将要执行的指令的指针, EIP(32 位指令指针)的当前值.
pendingsig=0 待处理信号的位图,记录发送给进程的普通信号
block_sig=0 阻塞信号的位图
sigign=0 忽略的信号的位图
sigcatch=082985 被俘获的信号的位图
wchan=0 如果该进程是睡眠状态,该值给出调度的调用点
nswap 被swapped的页数,当前没用
cnswap 所有子进程被swapped的页数的和,当前没用
exit_signal=17 该进程结束时,向父进程所发送的信号
task_cpu(task)=0 运行在哪个CPU上
task_rt_priority=0 实时进程的相对优先级别
task_policy=0 进程的调度策略,0=非实时进程,1=FIFO实时进程;2=RR实时进程
通过 app_process 更优雅
实际上我们并不确定上述数据格式在不同的系统版本或者机型上是否存在兼容性,这也是潜在的风险。
而通过 app_process 我们可以直接反射调用 Process 的 readProcFile 接口,很容易获得 utime 与 stime,这样就完全消除了兼容性问题风险。
- 由于我们的采集间隔为 1s,可以计算进程 cpu 使用率为 ((utime + stime) - (utime_pre + stime_pre)) / (cpu_total - cpu_total_pre)
接口调用伪代码如下
Method readProcFile = android.os.Process.class.getMethod("readProcFile", String.class, int[].class, String[].class, long[].class, float[].class);
readProcFile.setAccessible(true);
readProcFile.invoke(null, statFile, PROCESS_STATS_FORMAT, null, statsData, null);
readProcFile.invoke(null, "/proc/stat", SYSTEM_CPU_FORMAT, null, sysCpu, null);
2.3 流量
指标说明
recv:被测应用的下行流量
send:被测应用的上行流量
原理
通过读取 /proc/pid/net/dev 文件(低版本直接使用接口 TrafficStats.getUidRxBytes()),我们可以获得如下数据,其中 wlan0 表示 wifi 流量,rmnet0 表示 sim 卡流量
解析/proc/%d/net/dev示例结果
Inter-| Receive | Transmit
face |bytes packets errs drop fifo frame compressed multicast|bytes packets errs drop fifo colls carrier compressed
rmnet4: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
rmnet_tun03: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
rmnet_r_ims01: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
rmnet_tun02: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
dummy0: 0 0 0 0 0 0 0 0 1610 23 0 0 0 0 0 0
rmnet2: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
rmnet_tun11: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
rmnet_ims00: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
rmnet_tun10: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
rmnet_emc0: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
rmnet_tun13: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
rmnet0: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
rmnet_tun00: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
rmnet_tun04: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
rmnet5: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
wlan0: 1241518561 840807 0 0 0 0 0 7 7225770 73525 0 6 0 0 0 0
rmnet_r_ims00: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
rmnet3: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
rmnet_tun01: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
sit0: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
rmnet_tun14: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
ip_vti0: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
ip6tnl0: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
rmnet1: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
ip6_vti0: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
rmnet_r_ims11: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
rmnet_r_ims10: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
rmnet6: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
rmnet_tun12: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
lo: 3796620 292 0 0 0 0 0 0 3796620 292 0 0 0 0 0 0
rmnet_ims10: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
2.4 流畅度
指标说明
fps:用户可见的每秒显示帧数
jank:卡顿发生次数
FPS 原理
关于 fps 的统计存在很多个版本,基于不同方案统计的 fps 其含义完全不一样。
这里主要讲讲 移动测试 在 fps 上的选择与方案:
Choreographer
Choreographer 需要在 App 中实现,常见于 APM 等性能监控方案上,简单介绍一下原理:
- Vsync 信号一般来说由硬件产生,负责产生硬件 Vsync 的是 HWC;
- DispSync 将 Vsync 生成 VSYNC_APP 和 VSYNC_SF 信号,之后由 Choreographer 和 SurfaceFlinger 使用;
- SurfaceFlinger 收到 VSYNC_SF 信号,开始第 N-1 帧的合成与绘制;
- App 收到 VSYNC_APP 信号,开始第 N 帧渲染;
由于大部分设备都是 60HZ 的刷新频率,所以 VSYNC 信号的周期通常是 16.6ms,这个信号周期的长短可以很直观的反映应用代码实现的性能。但如果 App 处于 “静止” 状态,VSYNC 信号依然会持续产生,这时 GPU 绘制可能并未实际发生,这个统计值通常高于我们视觉看到的帧数。fps 的定义为 “每秒显示帧数” 或 “赫兹”,一般来说 FPS 用于描述影片、电子绘图或游戏每秒播放多少帧。
所以我更加倾向于 Choreographer 采集的 VSYNC 信号是一个流畅度指标(SM),而非真实 FPS。
SurfaceFlinger
SurfaceFlinger 接受来自多个数据源的数据缓冲区数据,通过 GPU 合成并发送给显示设备。这是我们通常描述的 fps,也是客户真实可视可体验到的的帧数数据。
在安卓系统中,WindowManagerService 会对每一个 contentView 创建相关的 UI 载体 Surface,SurfaceFlinger 主要负责将这个 Surface 渲染到手机屏幕上。
除了 Android 主窗口的焦点 Activity 与相对应的 ContentView 之外,还存在一种特殊的 SurfaceView, 他会独享一个 Surface,这个 Surface 独立渲染非常高效,支持 OpenglES 渲染。也就是说可能会出现两类窗口 fps。一个是 Activity 窗口帧率和 SurfaceView 窗口帧率。
一般来说,游戏、视频类应用都是通过这种 SurfaceView 来进行绘制,为了能够尽可能准确的获取被测应用的帧率,我们默认优先获取 SurfaceView 的 FPS。
如下是 优酷视频 我们能获取到的 Surface 如下:
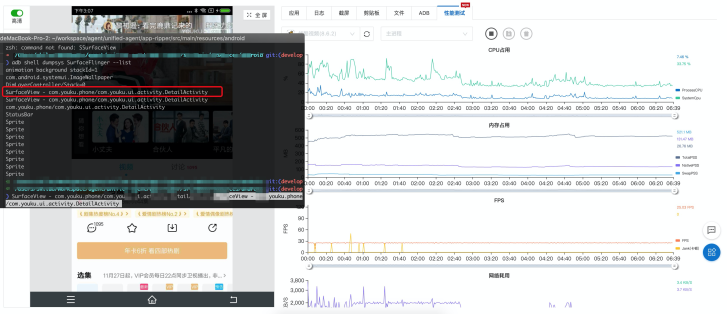
然后,再通过 dumpsys SurfaceFlinger --latency SurfaceView com.youku.phone/com.youku.ui.activity.DetailActivity 可以准确获取到视频窗口的帧绘制信息。
采用以上方法统计 fps 通常会有以下疑问:
- SurfaceFlinger 必须始终显示内容,所以当上层并没有新的缓存数据时,SurfaceFlinger 会继续显示当前数据,因此通过这种方法统计出来的 fps 值一般较低,静态页面可能为 0,这样的 fps 值是否具有迷惑性;
- 比如上图的视频应用只有 25fps,我们滑动时可能都有 40+ fps,这个数据能说明什么样的问题;
- fps 波动范围这么大,fps 值怎样才可以描述应用的流畅程度。
回答上面的问题,首先要需要重新定义 FPS != 流畅度。
这里引用苹果 WDDC2018 开发者大会的一个分享 (https://developer.apple.com/videos/play/wwdc2018/612/)。左图试图以 60fps 运行程序,实际只能达到 40fps,而右图实现了稳定的 30fps,右图的流畅度是明显要高于左图的,这种现象称为 Micro Stuttering。

这里不再深究 Micro Stuttering 的产生原因,回到 FPS 本身,首先 FPS 并不是越高越好,也不是越低就越差。它反映的是一种视觉惯性现象,FPS 值应当是越稳定越好。正如前面优酷视频的例子中,FPS 基本稳定在 25 左右,同样的在各类视频应用中,我们发现 FPS 几乎都是稳定在 20+,这已经足够给我们带来良好的观看体验了。
视觉惯性
视觉预期帧率,用户潜意识里认为下帧也应该是当前帧率,比如我们玩游戏一直是 60 帧,用户潜意识里认为下帧也应该是 60 帧率。刷新一直是 25 帧,用户潜意识里认为下帧也应该是 25 帧率。但是如果 60 帧一下跳变为 25 帧,就会产生明显的卡顿感。
电影帧
电影帧率一般是 24 帧。电影帧单帧耗时为 1000ms/24≈41.67ms。电影帧率是一个临界点。低于这个帧率,人眼可以感觉出画面的不连续性。
JANK 原理
既然 fps 无法完整的描述应用的流畅度,那么是否可以有一个指标表示应用的流畅程度,换言之,能否描述应用的卡顿程度。答案是 jank。
理解 jank,就一定要理解 google 设计的三重缓存机制(如下)。三重缓存指的是 A、B、C 三个缓存结构,当 GPU 未能在一次 VSync 时间内完成 B 的处理,此时 display、gpu、cpu 同时在处理 A、B、C 三个缓存,实现资源最大化的利用。
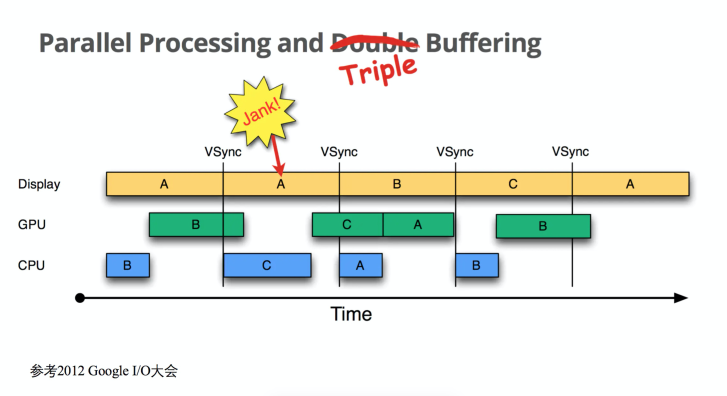
我们可以通过 dumpsys gfxinfo packageName 获取到的 janky frames 如下。这里的 Janky frames 是当一帧的时间大于 16.67ms 时,就计为一次 Janky frame。
从上文提到的三重缓存机制我们可以进行分析,B 先导致了一次视觉上的 jank,C 理论上也是 jank(跨 VSync),但是由于此时屏幕上显示的是 B,C 虽然 delay 了一帧,但是 C 看起来仍然是紧跟着 B 显示在屏幕上,而且 A 顺利的在 16.67ms 完成了绘制,实际上用户视觉上只少看了一帧,而 Janky frames 是 2。我们发现,当 Janky frames 高达近 40% 甚至 50% 时,我们依然感受不到卡顿,这个值并不是理想中的反映流畅度的指标。
Applications Graphics Acceleration Info:
Uptime: 171070276 Realtime: 962775383
** Graphics info for pid 13422 [com.zhongduomei.rrmj.society] **
Stats since: 152741070392878ns
Total frames rendered: 110
Janky frames: 7 (6.36%)
50th percentile: 9ms
90th percentile: 13ms
95th percentile: 18ms
99th percentile: 36ms
Number Missed Vsync: 2
Number High input latency: 0
Number Slow UI thread: 6
Number Slow bitmap uploads: 3
Number Slow issue draw commands: 0
基于以上考虑,我们重新定义 jank 的计算方式:
- 视觉连续性问题:帧时长 > 前三帧平均时长 *2
- 卡顿问题:帧时长 > 电影帧时长 * 2
假设应用按照电影帧 41.67ms 运行,若帧时长大于 2*41.67ms,意味着在缓存机制下,依然必现一次卡顿问题。
3. 其它接口
通过 app_process,我们还能够完成很多其它有趣的事情。
- 获得已安装应用列表。通过 android.content.pm.PackageManager,我们可以获得所有已安装应用,同时获得所有应用的图标,也可以提前获得应用程序的所有 Service,目前小程序大多使用 Service 层来做逻辑处理、数据请求以及接口调用,提前确认要测试的 Service 可以更加精确的完成小程序测试;
- 获得更多的设备硬件信息,如 gpu 信息等等;
- 获取设备视音频流;
- 部分实现静默安装等。
阿里云移动研发平台 EMAS https://www.aliyun.com/product/emas
阿里云移动测试 https://www.aliyun.com/product/mqc
钉钉交流群:11762195

